Python 自动爬取B站视频
文件名自定义(文件格式为.py),脚本内容:
#!/usr/bin/env python
#-*-coding:utf-8-*-
import requests
import random
import time
def get_json(url):
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
params = {
'page_size': 10,
'next_offset': str(num),
'tag': '今日热门',
'platform': 'pc'
}
try:
html = requests.get(url,params=params,headers=headers)
return html.json()
except BaseException:
print('request error')
pass
def download(url,path):
start = time.time() # 开始时间
size = 0
headers = {
'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url,headers=headers,stream=True) # stream属性必须带上
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 总大小
if response.status_code == 200:
print('[文件大小]:%0.2f MB' %(content_size / chunk_size / 1024)) # 换算单位
with open(path,'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data) # 已下载的文件大小
if __name__ == '__main__':
for i in range(10):
url = 'http://api.vc.bilibili.com/board/v1/ranking/top?'
num = i*10 + 1
html = get_json(url)
infos = html['data']['items']
for info in infos:
title = info['item']['description'] # 小视频的标题
video_url = info['item']['video_playurl'] # 小视频的下载链接
print(title)
# 为了防止有些视频没有提供下载链接的情况
try:
download(video_url,path='videos/%s.mp4' %title)
print('成功下载一个!')
except BaseException:
print('凉凉,下载失败')
pass
time.sleep(int(format(random.randint(2,8)))) # 设置随机等待时间
爬取效果如下:

爬取的文件:

生成一个windows平台可执行exe程序
工具安装:pip install PyInstaller
生成exe程序:
pyinstaller -i test.ico -F Grasp.py
打包过程:
打包好的文件:
参数含义:
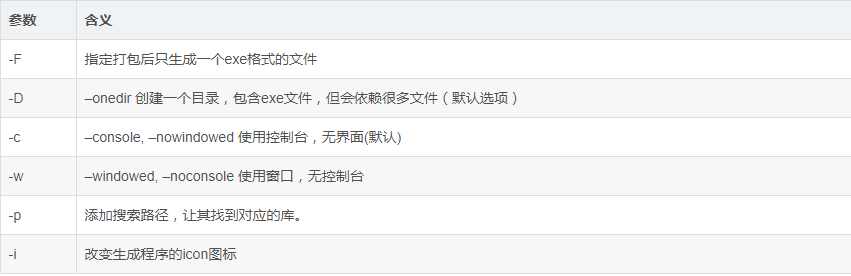
程序:

百度云下载链接
链接:百度云
提取码:hqhr
脚本内容收集自互联网,不保证生成的程序时效
Python 自动爬取B站视频的更多相关文章
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- python爬取B站视频弹幕分析并制作词云
1.分析网页 视频地址: www.bilibili.com/video/BV19E… 本身博主同时也是一名up主,虽然已经断更好久了,但是不妨碍我爬取弹幕信息来分析呀. 这次我选取的是自己 唯一的爆款 ...
- python 爬取B站视频弹幕信息
获取B站视频弹幕,相对来说很简单,需要用到的知识点有requests.re两个库.requests用来获得网页信息,re正则匹配获取你需要的信息,当然还有其他的方法,例如Xpath.进入你所观看的视频 ...
- 爬取B站视频
先安装you_get pip install you_get 爬取代码,爬了个ASMR的,学习困了自我催眠 import sys from you_get import common as you_g ...
- python爬虫——爬取B站用户在线人数
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序.主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析 ...
随机推荐
- Hadoop学习之路(十一)HDFS的读写详解
HDFS的写操作 <HDFS权威指南>图解HDFS写过程 详细文字说明(术语) 1.使用 HDFS 提供的客户端 Client,向远程的 namenode 发起 RPC 请求 2.name ...
- glusterfs分布式文件系统
第一:安装依赖包: yum install libibverbs librdmacm xfsprogs nfs-utils rpcbind libaio liblvm2app lvm2-devel ...
- 前端技术-js插件
学习良好的规范,培养良好的书写习惯,苦练基本功才能快速成长. http://www.cnblogs.com/cssbbs/category/758479.html 常用插件 插件名 使用范围 说明 官 ...
- Zookeeper入门(四)之Leader选举
让我们分析如何在ZooKeeper集合中选举leader节点.考虑一个集群中有N个节点.leader选举的过程如下: 所有节点创建具有相同路径 /app/leader_election/guid_ 的 ...
- Python自动化之高级语法单例模式
方法1 共享属性;所谓单例就是所有引用(实例.对象)拥有相同的状态(属性)和行为(方法) 同一个类的所有实例天然拥有相同的行为(方法), 只需要保证同一个类的所有实例具有相同的状态(属性)即可 所有实 ...
- 多线程并发容器CopyOnWriteArrayList
原文链接: http://ifeve.com/java-copy-on-write/ Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容 ...
- SQLserver中取众位数的写法
取众位数:先按个数倒排序,再取第一条SELECT * FROM ( select a.billid,a.DemandVoltage,count(1) as RecordCount, Row_NUMBE ...
- 在存放源程序的文件夹中建立一个子文件夹 myPackage。例如,在“D:\java”文件夹之中创建一个与包同名的子文件夹 myPackage(D:\java\myPackage)。在 myPackage 包中创建一个YMD类,该类具有计算今年的年份、可以输出一个带有年月日的字符串的功能。设计程序SY31.java,给定某人姓名和出生日期,计算该人年龄,并输出该人姓名、年龄、出生日期。程序使用YM
题目补充: 在存放源程序的文件夹中建立一个子文件夹 myPackage.例如,在“D:\java”文件夹之中创建一个与包同名的子文件夹 myPackage(D:\java\myPackage).在 m ...
- P1719 最大加权矩形
题目描述 为了更好的备战NOIP2013,电脑组的几个女孩子LYQ,ZSC,ZHQ认为,我们不光需要机房,我们还需要运动,于是就决定找校长申请一块电脑组的课余运动场地,听说她们都是电脑组的高手,校长没 ...
- MariaDB中文乱码之解决思路
首先出现乱码的原因就是编码不一致问题引起的,那么就从以下2个方面入手: 1.应用层:前提条件数据库服务端存储的中文数据是对的,但是页面上显示乱码,这里只需要检查你的项目的编码格式,设置成一致就行. 2 ...