记一次爬虫经历(友话APP的Web端)
背景:学校为迎接新生举办了一个活动,在友话APP的校园圈子内发布动态即可参与活动,最终抽取数名同学赠送福利。
分析:动态的数量会随着迎新的开始逐渐增加,人工统计显然不现实,因此可以使用爬虫脚本在友话APP的Web端抓取数据做统计。
任务:1.抓取所有动态 2.统计数据并按用户名去重 3.抽奖工作需由抽奖平台完成,保存统计结果即可,抽奖不做涉及。
环境:Chrome、Python
历程:
首先,常规操作,查看友话校园圈子的网页源代码。
里面关于网页的内容什么都没有,基本可以确定网页中所有的内容均是由JS加载。

接下来就需要F12进入开发者模式一探究竟
在网页加载的过程中,网页的内容通过请求两个URL来获取。都打开查看后发现第一个URL中保存的是包含动态内容的JSON格式的数据。
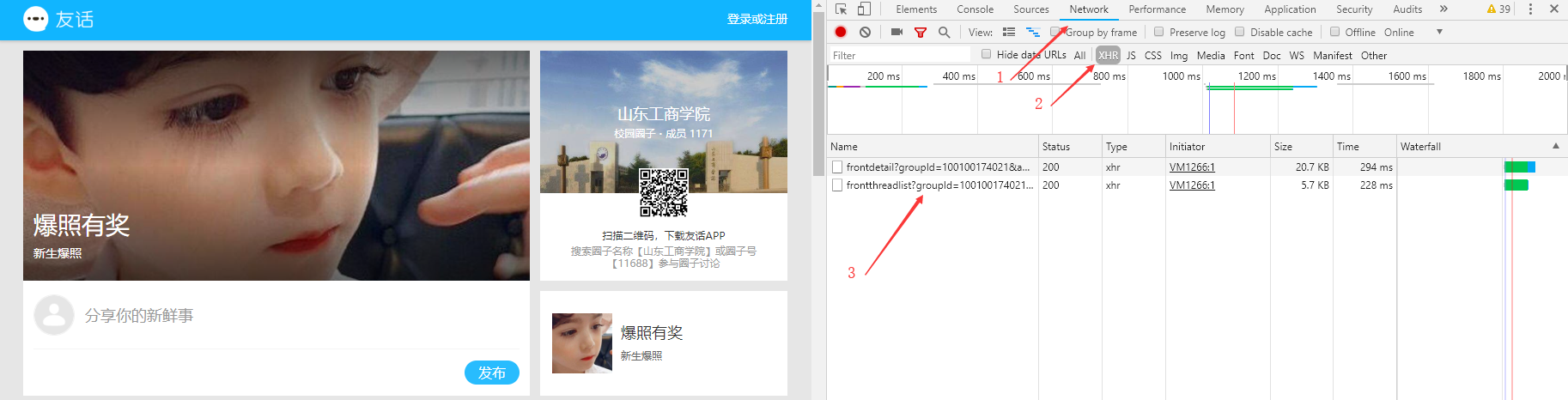
下面就需要想办法用爬虫去请求第一个URL来获取JSON数据,可以看到URL的参数有四个。

其中前两个参数是固定值,而后两个参数每次请求都不同,因此请求URL时的重点是如何获得后两个参数的值。timestamp为时间戳,sign为请求签名。
时间戳由Python中的time模块可以获得,而请求签名是最让人头疼的一个值,它是由某种规则将数据加密而成的,加密的工作是由JS来完成,加密的方式肯定不会明摆着,接下来的任务就是去寻找完成加密工作的那段JS代码。
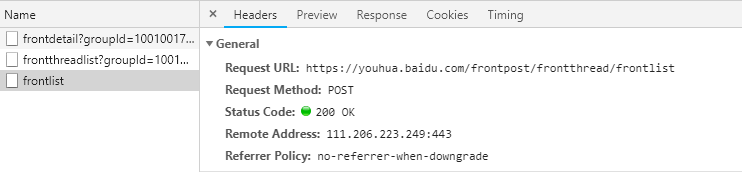
在网页加载的过程中,运行的JS代码通过请求四个URL来获取,仔细比对名字后发现,这四个URL在网页源代码内都有(详见第一张图)。
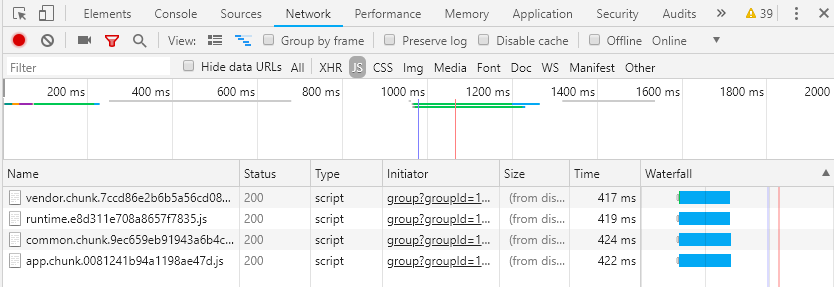
查看四个URL中的JS代码后发现,所有代码均被格式化过,变量名都已变成a、b、c、d的样式。
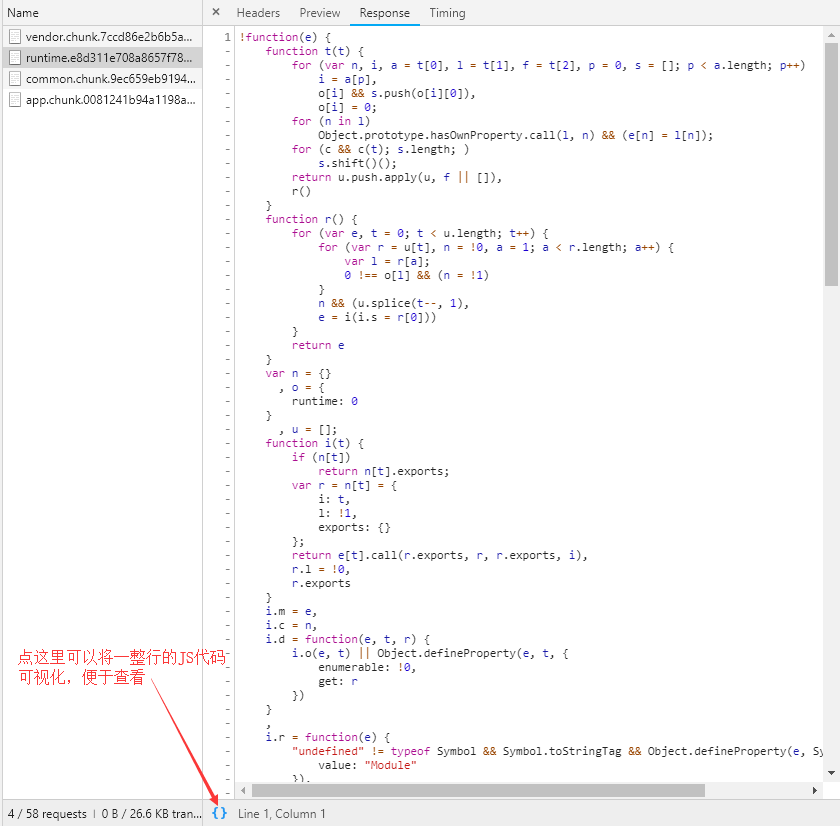
由于所有代码均被格式化,所以不能从变量名入手寻找完成加密工作的代码,因此尝试在四份JS代码中寻找sign关键字,最终在名为common······的JS代码中找到了完成拼接URL工作的函数。
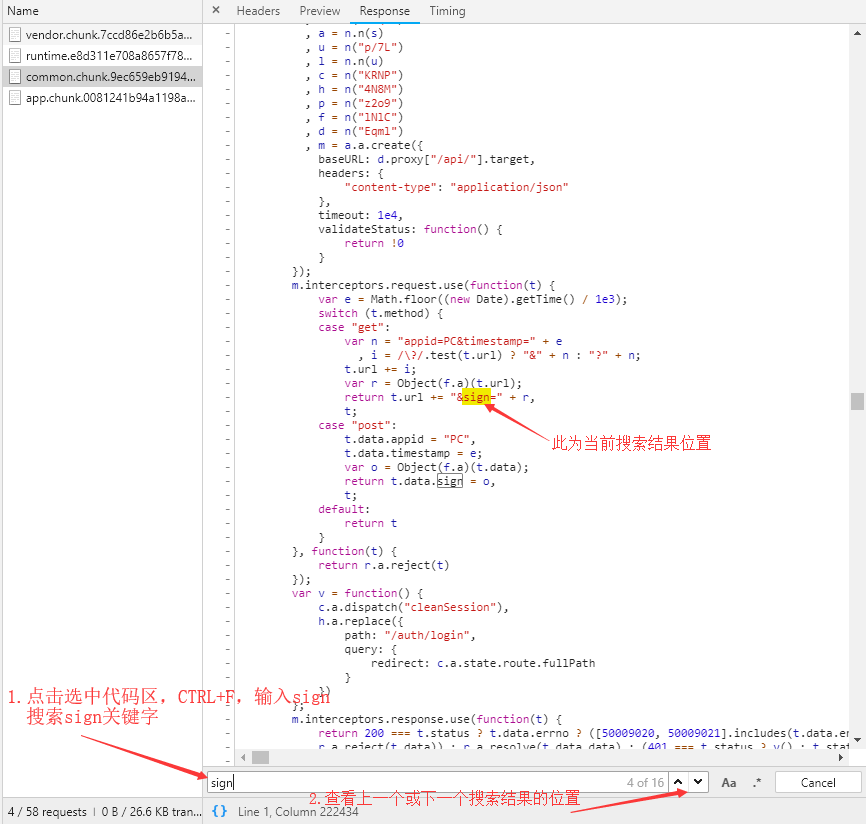
在上面图片中的当前位置,可以看出代码在这里完成了拼接所请求URL的sign参数的工作,能肯定的是变量r中存储的就是加密后的字符串,并且变量r是通过上一行代码获得的。由于不能从变量名入手寻找完成加密工作的代码,所以只能通过调试这一段代码,去寻找完成加密工作的代码的位置。
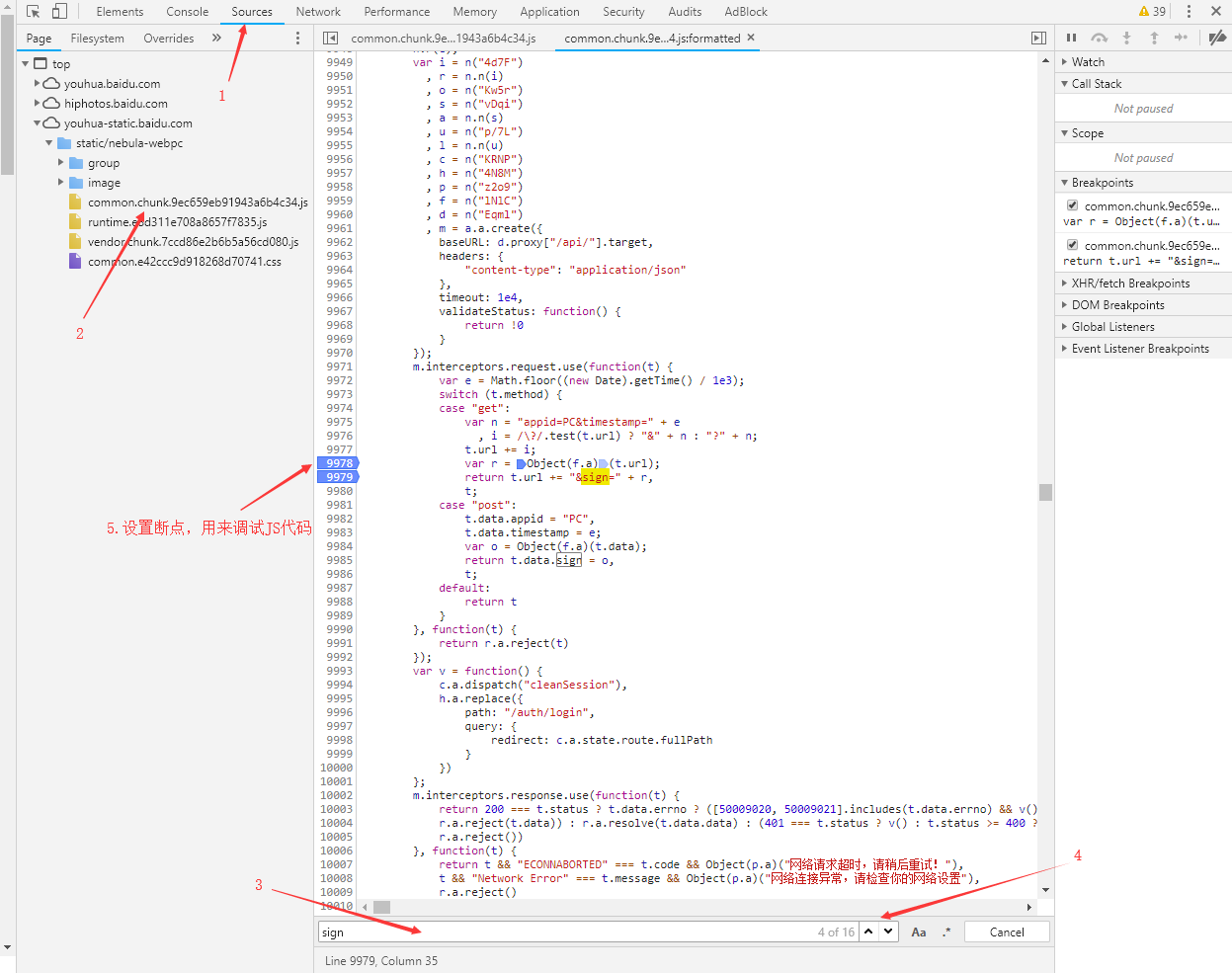
断点设置好后开始调试JS代码,主要功能键说明:F5开始进行调试(意味着刷新并从头开始一步一步加载网页,等待代码运行到断点处,可能会比较卡,笔记本的小风扇是会嗡嗡转起来的),F10运行下一行(遇到函数直接执行,不会进入函数调试),F11运行下一行(遇到函数会进入函数继续调试),F8终止调试(停止一步一步加载网页,直接显示完整的网页),。
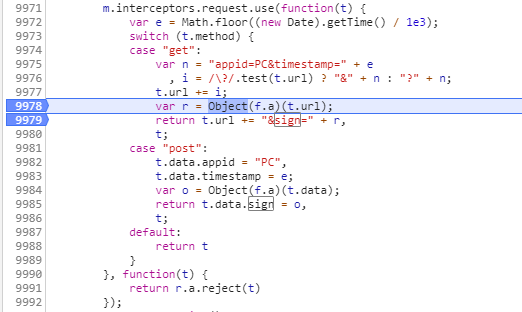
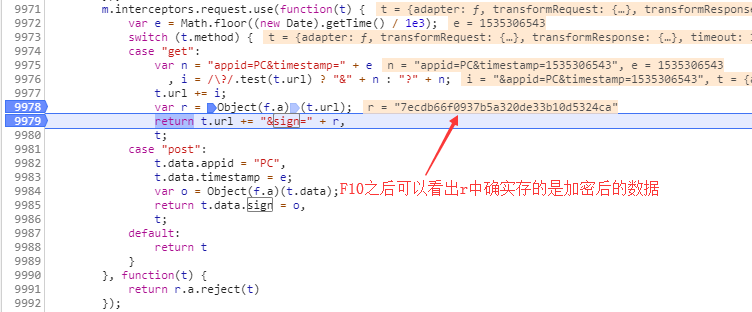
上面通过F10调试确认之前的判断没有问题,之后终止调试再重新调试,通过F11进入加密数据的函数
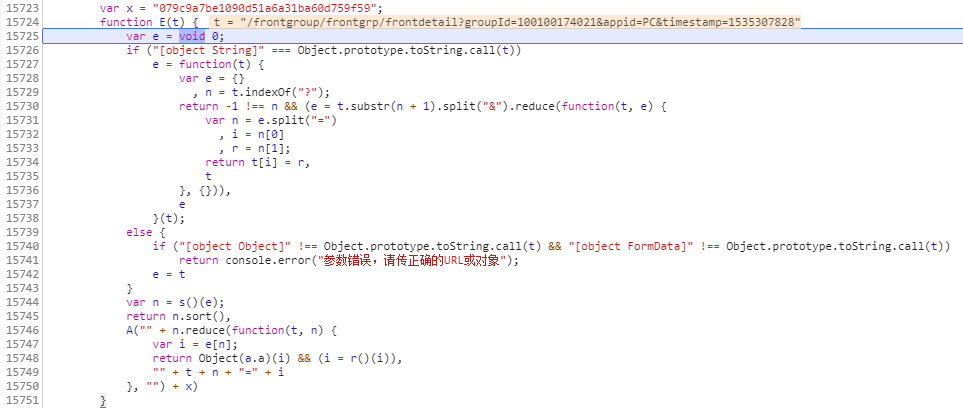
通过调试该函数,可以得出数据加密的方式(加密算法是md5,这个是我自己试出来的,因为加密算法的函数是对方自己编写的,所以函数名也被格式化了,调试加密算法函数的时候什么都看不懂,最后拿调用加密算法函数之前的数据用md5算法一试,结果相同,也算是走狗屎运了,具体加密的方式见Python代码)
有了最后一个参数的获取方式之后,终于可以去请求URL获取JSON数据了,代码如下:
def start_page():
# 获取时间戳
timing = int(time.time())
# 获取需要加密的数据 key为密钥
s = "appid=PCgroupId=100100174021timestamp=" + str(timing) + key
# 通过md5加密数据生成请求签名
sign = hashlib.md5(s.encode(encoding = "utf-8")).hexdigest()
# 请求起始页
r = requests.get("https://youhua.baidu.com/frontgroup/frontgrp/frontdetail", params = {
",
"appid" : "PC",
"timestamp" : timing,
"sign" : sign,
}, headers = headers1, timeout = 5)
r.encoding = "UTF-8"
text = json.loads(r.text)
if not text["data"]:
print(text)
return None
return text["data"]["groupThreadList"]["list"]
但是问题又来了,此JSON数据中的动态内容只有10条,通过将网页拉到最底发现,网页又请求了另一个URL来获取更多的动态。
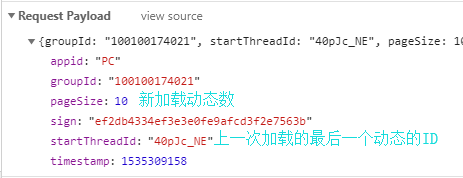
请求参数是Payload格式的,因此需要把参数打包成JSON格式去请求。代码如下:
def pull_list(threadId):
# 获取时间戳
timing = int(time.time())
# 获取需要加密的数据
s = ("appid=PCgroupId=100100174021pageSize=10startThreadId=" +
threadId + "timestamp=" + str(timing) + key)
# 生成请求签名
sign = hashlib.md5(s.encode(encoding = "utf-8")).hexdigest()
# 打包请求参数
data = {
"appid" : "PC",
",
"pageSize" : 10,
"sign" : sign,
"startThreadId" : threadId,
"timestamp" : timing,
}
# 拉取更多动态,请求时需要把上面打包好的参数生成JSON格式
r = requests.post("https://youhua.baidu.com/frontpost/frontthread/frontlist", headers = headers2, data = json.dumps(data), timeout = 5)
r.encoding = "UTF-8"
text = json.loads(r.text)
if not text["data"]:
print(text)
return None
return text["data"]["list"]
全部代码:
import re
import json
import time
import hashlib
import requests
from openpyxl import Workbook
class StartPageError(Exception):
"""首页抓取失败"""
pass
class PullListError(Exception):
"""拉取列表失败"""
pass
# 起始页的请求头
headers1 = {
"Accept" : "application/json, text/plain, */*",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "zh-CN,zh;q=0.9",
"Connection" : "keep-alive",
"Host" : "youhua.baidu.com",
"Referer" : "https://youhua.baidu.com/group?groupId=100100174021",
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36",
}
# 获取更多动态的请求头
headers2 = {
"Accept" : "application/json, text/plain, */*",
"Accept-Encoding" : "gzip, deflate, br",
"Accept-Language" : "zh-CN,zh;q=0.9",
"Connection" : "keep-alive",
",
"Content-Type" : "application/json",
"Host" : "youhua.baidu.com",
"Origin" : "https://youhua.baidu.com",
"Referer" : "https://youhua.baidu.com/group?groupId=100100174021",
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36",
}
# 密钥
key = "079c9a7be1090d51a6a31ba60d759f59"
# 获取起始页的数据
def start_page():
# 获取时间戳
timing = int(time.time())
# 获取需要加密的数据 key为密钥
s = "appid=PCgroupId=100100174021timestamp=" + str(timing) + key
# 通过md5加密数据生成请求签名
sign = hashlib.md5(s.encode(encoding = "utf-8")).hexdigest()
# 请求起始页
r = requests.get("https://youhua.baidu.com/frontgroup/frontgrp/frontdetail", params = {
",
"appid" : "PC",
"timestamp" : timing,
"sign" : sign,
}, headers = headers1, timeout = 5)
r.encoding = "UTF-8"
text = json.loads(r.text)
if not text["data"]:
print(text)
return None
return text["data"]["groupThreadList"]["list"]
# 获取更多动态的数据
def pull_list(threadId):
# 获取时间戳
timing = int(time.time())
# 获取需要加密的数据
s = ("appid=PCgroupId=100100174021pageSize=10startThreadId=" +
threadId + "timestamp=" + str(timing) + key)
# 生成请求签名
sign = hashlib.md5(s.encode(encoding = "utf-8")).hexdigest()
# 打包请求参数
data = {
"appid" : "PC",
",
"pageSize" : 10,
"sign" : sign,
"startThreadId" : threadId,
"timestamp" : timing,
}
# 拉取更多动态,请求时需要把上面打包好的数据生成JSON格式
r = requests.post("https://youhua.baidu.com/frontpost/frontthread/frontlist", headers = headers2, data = json.dumps(data), timeout = 5)
r.encoding = "UTF-8"
text = json.loads(r.text)
if not text["data"]:
print(text)
return None
return text["data"]["list"]
# 统计、去重、打印结果
def print_data(datas):
datas.sort(key = lambda data : data["like"], reverse = True)
newdatas = []
for data in datas:
for newdata in newdatas[:]:
if data["nickname"] == newdata["nickname"]:
break
else:
data["content"] = re.sub(r"<.+?>", "", data["content"])
newdatas.append(data)
print("no repeat datas has", len(newdatas))
newdatas.insert(0, {"userid" : "用户id",
"nickname" : "昵称",
"publishtime" : "发布日期",
"like" : "点赞数",
"content" : "动态内容",})
wb = Workbook()
# wb = load_workbook("userdatas.xlsx")
sheet = wb.active
timing = time.strftime("%m-%d %H:%M", time.localtime(time.time()))
sheet['A1'] = "截止时间:%s"%timing
row = len(newdatas)
for i in range(2, row + 2):
_ = sheet.cell(row = i, column = 1, value = newdatas[i-2]["userid"])
_ = sheet.cell(row = i, column = 2, value = newdatas[i-2]["nickname"])
_ = sheet.cell(row = i, column = 3, value = newdatas[i-2]["publishtime"])
_ = sheet.cell(row = i, column = 4, value = newdatas[i-2]["like"])
_ = sheet.cell(row = i, column = 5, value = newdatas[i-2]["content"])
wb.save("userdatas.xlsx")
# 主函数
def get_content():
# 请求起始页,若失败重新请求
while True:
try:
time.sleep(3)
content = start_page()
if not content:
raise StartPageError("start_page error")
except StartPageError as error:
print("errorinfo:", error)
except Exception as error:
print("errorinfo: unknow error,", error)
else:
break
datas = []
total = 0
# 获取更多动态的数据
try:
while content != []:
length = len(content)
total += length
for i in range(length):
data = content[i]
if "text" in data["content"][0].keys():
cont = data["content"][0]["text"]
else:
cont = ""
datas.append({"userid" : data["userInfo"]["userId"],
"nickname" : data["userInfo"]["displayName"],
"publishtime" : time.strftime("%m-%d %H:%M", time.localtime(data["publishTime"])),
"like" : data["agreeNum"],
"content" : cont,})
# 若请求失败重新去请求
while True:
try:
time.sleep(3)
content = pull_list(content[length - 1]["threadId"])
if content == None:
raise PullListError("pull_list error")
except PullListError as error:
print("errorinfo:", error)
except Exception as error:
print("errorinfo: unknow error,", error)
else:
break
# if total == 20:
# break
except Exception as error:
print("errorinfo: unknow error,", error, ", run in ", total)
else:
print("end of the spider, the total is", total)
# 最后不管成功与否都要把统计结果打印出来
finally:
print_data(datas)
if __name__ == "__main__":
get_content()
总结:
此次爬虫编写虽然只有区区一百多行,但却历经了四十八小时,其中通了一次宵。几经想要放弃,因为不会的东西太多了,都是一点一点通过各种搜索学习的。现在想来,基础扎实与否,最主要的体现就是在遇到问题的时候搜索问题的精确度。就比如我在一开始遇到请求的四个参数时,有两个参数是每次请求都不同的,而我完全不知道一个叫时间戳,一个叫请求签名,刚开始搜索问题的时候一直在搜索:爬虫遇到请求参数是随机的怎么办。像这样浪费时间的地方有很多。
这里面最让我头疼的就是请求签名了,在这里卡的时间是最久的,在这里有想要放弃的念头也是最多的。刚知道他叫请求签名的时候,直接去搜请求签名的生成规则,按照网上各种生成规则得出来的结果都和网页中的结果不一样,最后只能选择调试JS代码这一条路,又开始各种搜索Chrome调试JS代码的方法。开始很不顺利,因为完全看不懂JS的代码,只能通过调试一步一步的看变量的值。找到最后发现还是看不懂为什么,其实我一直忽略了最重要的一个事,就是密钥,很多博客上讲请求签名生成规则的时候都会说提到密钥这个东西。有了密钥这个概念之后,再看到加密时的结果就豁然开朗了。
最终,我终于完成了以我当前的水平来说几乎不可能完成的任务,心中的喜悦肯定是有的,只希望以后学习不要心浮气躁,踏下心来多打基础才是最重要的。
记一次爬虫经历(友话APP的Web端)的更多相关文章
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- 记一次抓包和破解App接口
目录 第一章 · 起源 第二章 · 尝试 第三章 · 脱狱 第四章 · 柳暗花明 第五章 · 终结 第一章 · 起源 某日,想做个爬虫工具,爬某个网站上的数据已做实验之用.大家都知道爬pc网页上的数据 ...
- Native App、Web App 还是Hybrid App?
一.什么是Native App? Native App即原生应用,即我们一般所称的客户端,是针对不同手机系统单独开发的本地应用,如需使用需要先下载到手机并安装,下载Native App的最常见方法是访 ...
- 无框架完整搭建安卓app及其服务端(一)
技术背景: 我的一个项目做的的是图片处理,用 python 实现图片处理的核心功能后,想部署到安卓app中,但是对于一个对安卓和服务器都一知半解的小白来说要现学的东西太多了. 而实际上,我们的项目要求 ...
- Native App、Web App 还是Hybrid App
Native App.Web App 还是Hybrid App? 技术 标点符 1年前 (2014-05-09) 3036℃ 0评论 一.什么是Native App? Native App即原生应用, ...
- PC/APP/H5三端测试的相同与不同
随着手机应用的不断状态,同一款产品的移动端应用市场占相较PC端也越来越大,那么app与PC端针对这些产品的测试有什么相同与不同之处呢?总结如下: 首先谈一谈相同之处: 一,针对同一个系统功能的测试,三 ...
- APP开发手记01(app与web的困惑)
文章链接:http://quke.org/post/app-dev-fragment.html (转载时请注明本文出处及文章链接) 最近在用博客园的wcf服务做博客园的android和ios的app, ...
随机推荐
- Recommend ways to overwrite hashCode() in java
Perface In the former chapter, I talk about topics about hashCode, And I will continue to finish the ...
- HTTP协议之内容协商
一个URL常常需要代表若干不同的资源.例如那种需要以多种语言提供其内容的网站站点.如果某个站点有说法语的和说英语的两种用户,它可能想用这两种语言提供网站站点信息.理想情况下,服务器应当向英语用户发送英 ...
- MPVUE - 使用vue.js开发微信小程序
MPVUE - 使用vue.js开发微信小程序 什么是mpvue? mpvue 是美团点评前端团队开源的一款使用 Vue.js 开发微信小程序的前端框架.框架提供了完整的 Vue.js 开发体验,开发 ...
- css-使不同大小的图片在固定大小的容器中居中
HTML示例如下: <ul> <li class="imgbox"><img src="img1.jpg"></li& ...
- 使用display:none和visibility:hidden隐藏的区别
今天做毕设时遇到了一个小问题,我做了一个tab导航栏,点击一个tab页其它tab页隐藏,这时候第一想法是使用display:none来控制显示隐藏,写了之后发现使用display会有一个问题,就是第二 ...
- CSS3D动画制作一个3d旋转的筛子
希望这个demo能让大家理解CSS3的3d空间动画(其实是个假3D) 首先给一个3d的解剖图,x/y/z轴线轴线已经标出 下面附上添加特效的动画旋转 可以根据demo并参考上面解剖图进行理解 < ...
- dynamics 365 AI 解决方案 —— 介绍
Digital transformation has been reshaping our world and artificial intelligence (AI) is one of the n ...
- android中的textview显示汉字不能自动换行的一个解决办法
<TableLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_ ...
- 如何优雅使用Coursera ? —— Coursera 视频缓冲 & 字幕遮挡
Coursera 视频缓冲 其实这个问题的根本是coursera上视频源d3c33hcgiwev3.cloudfront.net被墙,而ss的pac并未及时更新所导致的. 1 chrome 插件 - ...
- Android应用程序启动过程(二)分析
本文依据Android6.0源码,从点击Launcher图标,直至解析到MainActivity#OnCreate()被调用. Launcher简析 Launcher也是个应用程序,不过是个特殊的应用 ...