python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例
XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历。
选取节点
XPath使用路径表达式来选取XML文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
常用路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前父节点。 |
| @ | 选取属性。 |
| text() | 选取文本内容。 |
实例
在下面的表格中,列出一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取bookstore元素 |
| /bookstore | 选取根元素bookstore。注释:假如路径起始于(/),则此路径始终代表到某元素的绝对路径。 |
| bookstore/book | 选取属于bookstore的子元素的所有book元素。 |
| //book | 选取所有book子元素,而不管他们在文档中的位置。 |
| bookstore//book | 选择属于bookstore元素的后代的所有book元素,而不管它们位于bookstore之下的什么位置。 |
| //book/title/@lang | 选择所有的book下面的title中的lang属性的值。 |
| //book/title/text() | 选择所有的book下面的title的文本。 |
查找特定的节点
| 路径表达式 | 结果 |
|---|---|
| //title[@lang] | 选取所有拥有名为lang的属性的title元素。 |
| //title[@lang="eng"] | 选取lang属性值为eng的所有title元素。 |
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素。 |
| /bookstore/book[last()] | 选取属于bookstore子元素的最后一个book元素。 |
| /bookstore/book[position()>1] | 选择bookstore下面的book元素,从第二个开始选择。 |
| //book/title[text()='Harry Potter'] | 选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素。 |
| /bookstore/book[price>35.00]/title | 选取bookstore元素中的book元素的所有title元素,且其中的price元素的值需大于35.00。 |
注意点:在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1。
选取未知节点
XPath通配符可用来选取未知的XML元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性的节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,列出一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //bookstore/* | 选取bookstore元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带属性的title元素。 |
选取若干路径
通过在路径表达式中使用"|"运算符,您可以选取若干个路径。
实例
在下面的表格中,列出一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取book元素的所有title和price元素。 |
| //title | //price | 选取文档中的所有title和price元素。 |
| /bookstore/book/title | //price | 选取属于bookstore元素的book元素的所有title元素,以及文档中所有的price元素。 |
使用技巧
在一般的爬虫实战中,XPath路径可以通过谷歌浏览器或火狐浏览器中复制得到,如下图:
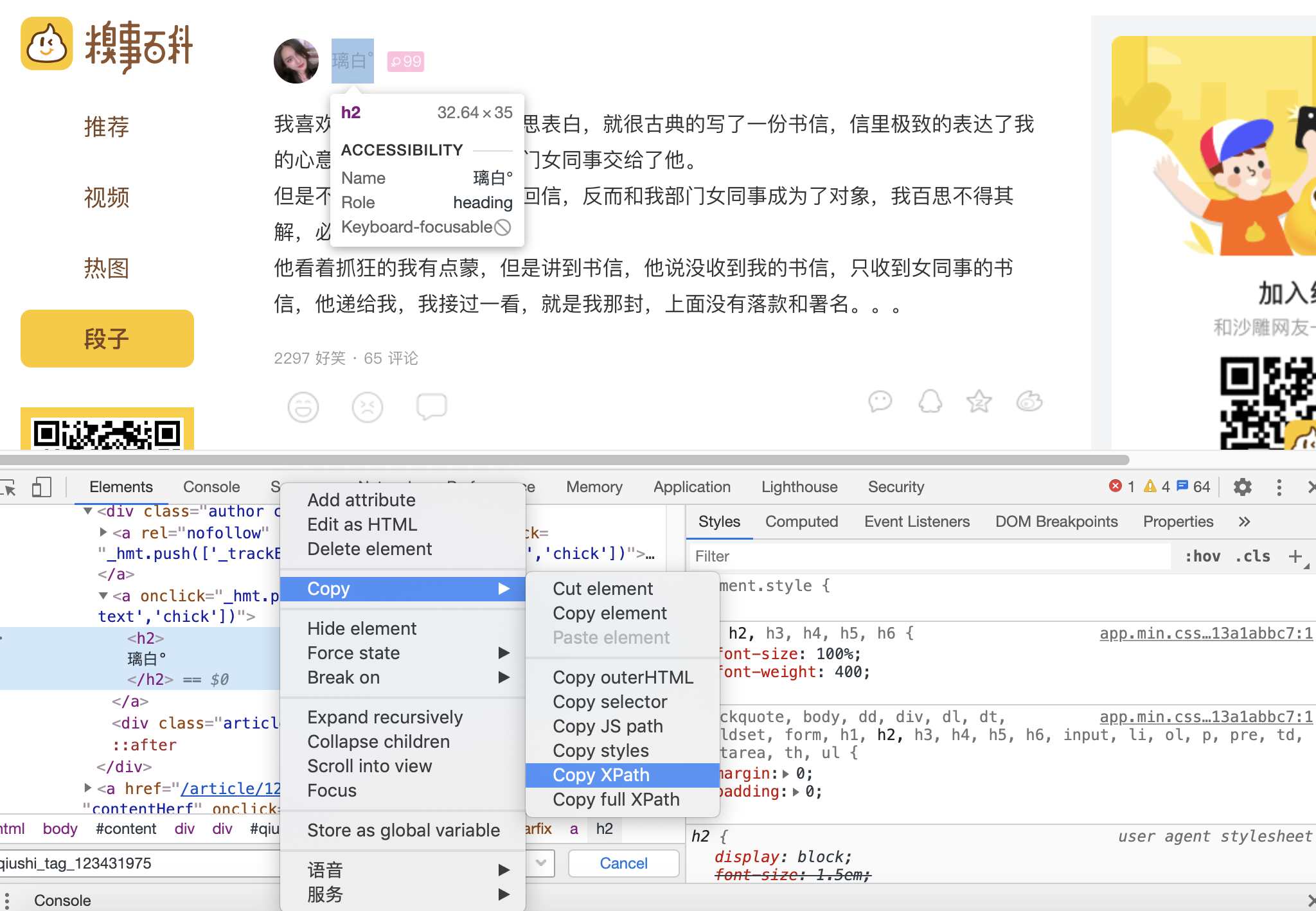
但是对于新手可以多多尝试自己写XPath路径,因为有时候复制获取的XPath路径过长,而自己写的更简洁写。
例子:
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
url = 'http://www.qiushibaike.com/text/'
res = requests.get(url, headers=headers)
selector = etree.HTML(res.text)
id = selector.xpath('//div[@class="article block untagged mb15 typs_long"]/div[1]/a[2]/h2/text()')
print(''.join(id).strip())
# 注意:通过/text()可以获取标签中的文字信息。
# 结果为:璃白°
几种解析方式的性能对比
| 爬取方法 | 性能 | 使用难度 |
|---|---|---|
| 正则表达式 | 快 | 困难 |
| BeautifulSoup | 慢 | 简单 |
| Lxml | 快 | 简单 |
爬取豆瓣图书TOP250
爬取的例子直接输出到屏幕。
需求分析:
(1)要爬取的内容为豆瓣图书top250的信息,如下图所示:
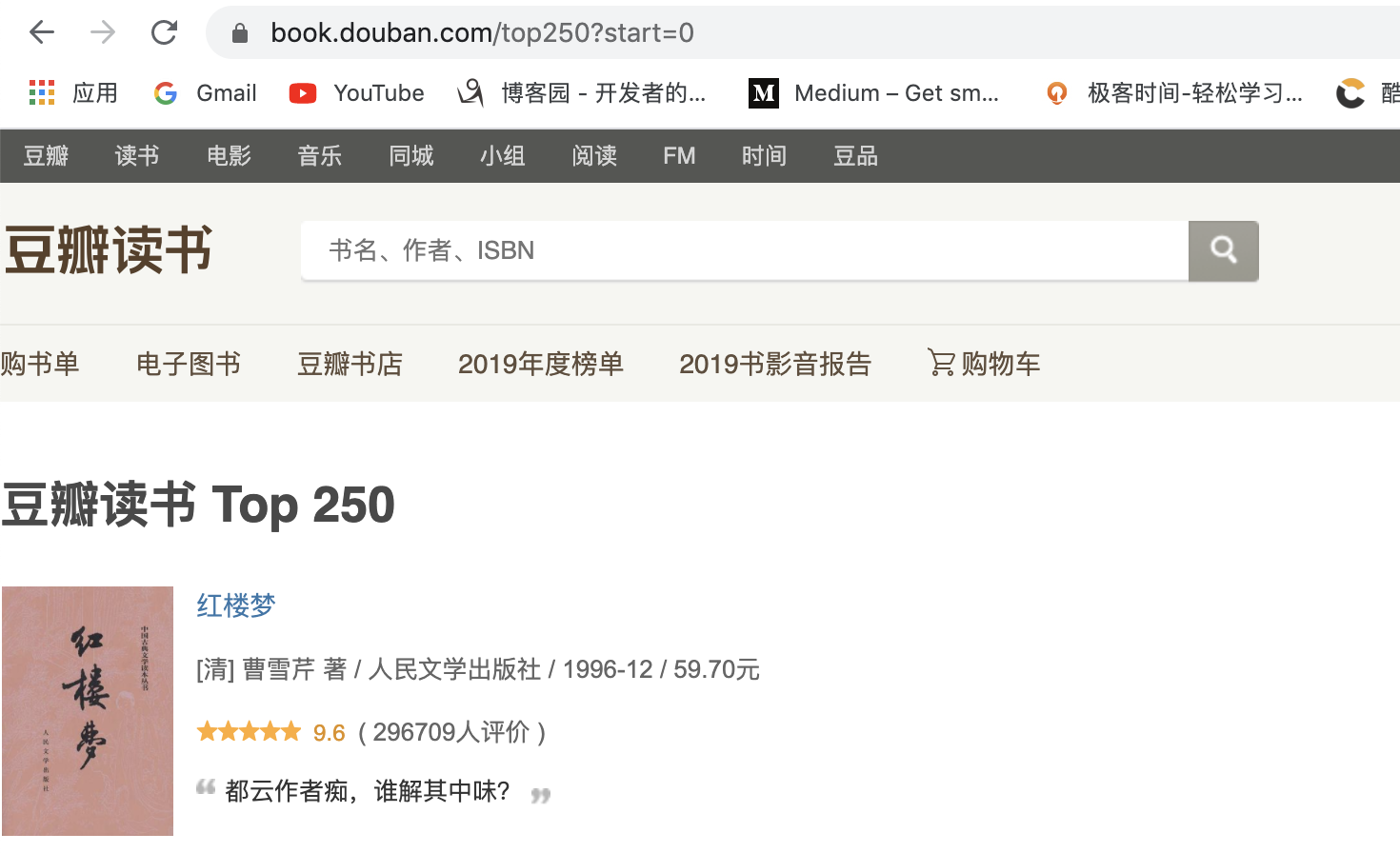
(2)所爬取的网页链接:https://book.douban.com/top250?start=0
(3)需要爬取的信息有:书名,书本的链接,作者,出版社,出版日期评分和评价。
具体代码如下:
# -*- encoding:utf8 -*-
# 爬取豆瓣图书TOP250。
import requests
from lxml import etree
# 请求头,用来模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
def get_info(url):
res = requests.get(url, headers=headers).text
# lxml库的etree解析html
selector = etree.HTML(res)
# 获取的是一页中所有的书本信息,每本的所以信息都在类为item的tr下面。
infos = selector.xpath("//tr[@class='item']")
for info in infos:
# 书名
name = info.xpath('td/div/a/@title')[0]
# 书的链接地址
book_url = info.xpath('td/div/a/@href')[0]
# 获取的是书本的基本信息,有作者和出版社,和出版日期...
book_infos = info.xpath('td/p/text()')[0]
# 作者
author = book_infos.split('/')[0]
# 出版社
publisher = book_infos.split('/')[-3]
# 出版日期
date = book_infos.split('/')[-2]
# 价格
price = book_infos.split('/')[-1]
# 书本的评分
rate = info.xpath('td/div/span[2]/text()')[0]
# 下面的评论
comments = info.xpath('td/p/span/text()')
# 这里单行的if语句是:如果comments的长度不为0时,则把comments的第1个元素给comment,否则就把"空"赋值给comment
comment = comments[0] if len(comments) != 0 else "空"
print(name + " " + book_url + " " + book_infos + " " + author + " " + publisher + " " + date + " " + price + " " + rate + " " + comment)
print()
# 获取下一页的url
if selector.xpath("//span[@class='next']/a"):
next_pag = selector.xpath("//span[@class='next']/a/@href")
get_info(''.join(next_pag))
if __name__ == "__main__":
url = 'https://book.douban.com/top250'
get_info(url)
部分结果如下图所示:

python爬虫:XPath语法和使用示例的更多相关文章
- python爬虫xpath的语法
有朋友问我正则,,okey,其实我的正则也不好,但是python下xpath是相对较简单的 简单了解一下xpath: XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML ...
- Python爬虫 XPath语法和lxml模块
XPath语法和lxml模块 什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. X ...
- python爬虫xpath
又是一个大晴天,因为马上要召开十九大,北京地铁就额外的拥挤,人贴人到爆炸,还好我常年挤地铁早已练成了轻功水上漂,挤地铁早已经不在话下. 励志成为一名高级测试工程师的我,目前还只是个菜鸟,难得有机会,公 ...
- python爬虫简单架构原理及示例
网页下载器示例: # coding:utf-8 import urllib2 import cookielib url = "http://www.baidu.com" print ...
- python爬虫----XPath
1.知道本节点元素,如何定位到兄弟元素 详情见博客 XML代码见下 bt1在文档中只出现一次,所以很容易获取到bt1中内容,那怎么根据<td class='bt1'>来获取bt2中的内容 ...
- Python爬虫 | xpath的安装
错误信息:程序包无效.详细信息:“Cannot load extension with file or directory name . Filenames starting with "& ...
- python爬虫前提技术
1.BeautifulSoup 解析html如何使用 转自:http://blog.csdn.net/u013372487/article/details/51734047 #!/usr/bin/py ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
随机推荐
- .NET Core CLI 的性能诊断工具介绍
前言 开发人员的.NET Core项目上线后,经常会出现各种问题,内存泄漏,CPU 100%,处理时间长等, 这个时候就需要快速并准确的发现问题,并解决问题, 除了项目本身的日志记录外,NET Cor ...
- static关键字真能提高Bean的优先级吗?答:真能
生命太短暂,不要去做一些根本没有人想要的东西.本文已被 https://www.yourbatman.cn 收录,里面一并有Spring技术栈.MyBatis.JVM.中间件等小而美的专栏供以免费学习 ...
- scrapy shell 遇到的问题
有时候用scrapy shell来调试很方便,但是有些网站有防爬虫机制,所以使用scrapy shell会返回403,比如下面 有两种解决方法: (1):第一种方法是在命令上加上-s USER_AGE ...
- Ethical Hacking - NETWORK PENETRATION TESTING(8)
WEP Cracking Basic case Run airdump-ng to log all traffic from the target network. airodump-ng --cha ...
- 关于ES6的let和const
变量 var存在的问题 可以重复声明 无法限制修改 没有块级作用域 (在全局范围内有效) 存在变量提升 const/let 不可以重复声明 let a = 1; let a = 2; var b = ...
- 小程序开发全栈1.2/3/4组件、flex布局、样式
1.2 组件 1.2.1 text组件 编写文本信息,类似于HTTP中的span 1.2.2 view组件 容器,类似于HTTP中的div 1.2.3 image组件 图片显示组件 1.3 页面fle ...
- P4547 [THUWC2017]随机二分图(状压,期望DP)
期望好题. 发现 \(n\) 非常小,应该要想到状压的. 我们可以先只考虑 0 操作. 最难的还是状态: 我们用 \(S\) 表示左部点有哪些点已经有对应点, \(T\) 表示右部点有哪些点已经有对应 ...
- 题解 CF585F 【Digits of Number Pi】
考虑用数位 \(DP\) 来统计数字串个数,用 \(SAM\) 来实现子串的匹配. 设状态 \(f(pos,cur,lenth,lim,flag)\),表示数位的位数,在 \(SAM\) 上的节点,匹 ...
- js判断字符串中是否包含特殊字符、中文
/** * @author:xc * @desc: 特殊字符校验 除了下划线 */ containSpecial(str) { var containSpecial = RegExp( /[(\ )( ...
- Python灰帽子:黑客与逆向工程师的Python编程之道PDF高清完整版免费下载|百度云盘
百度云盘免费下载:Python灰帽子:黑客与逆向工程师的Python编程之道PDF高清完整版免费下载 提取码:8nki 目录 · · · · · · 第1章 搭建开发环境 11.1 操作系统要求 1 ...