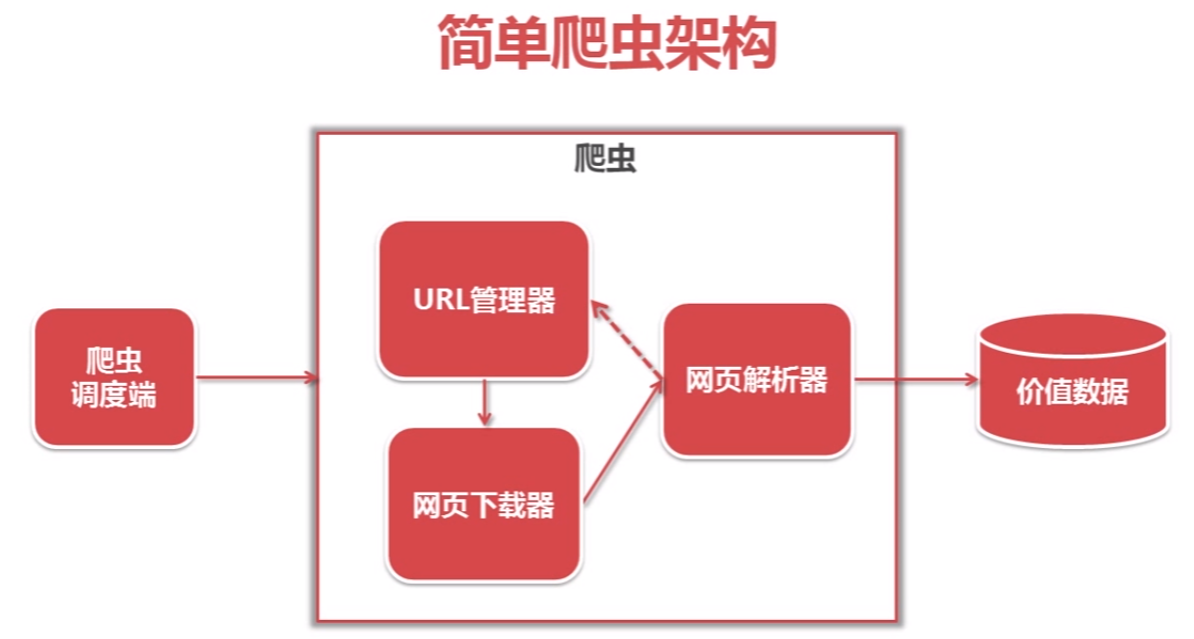
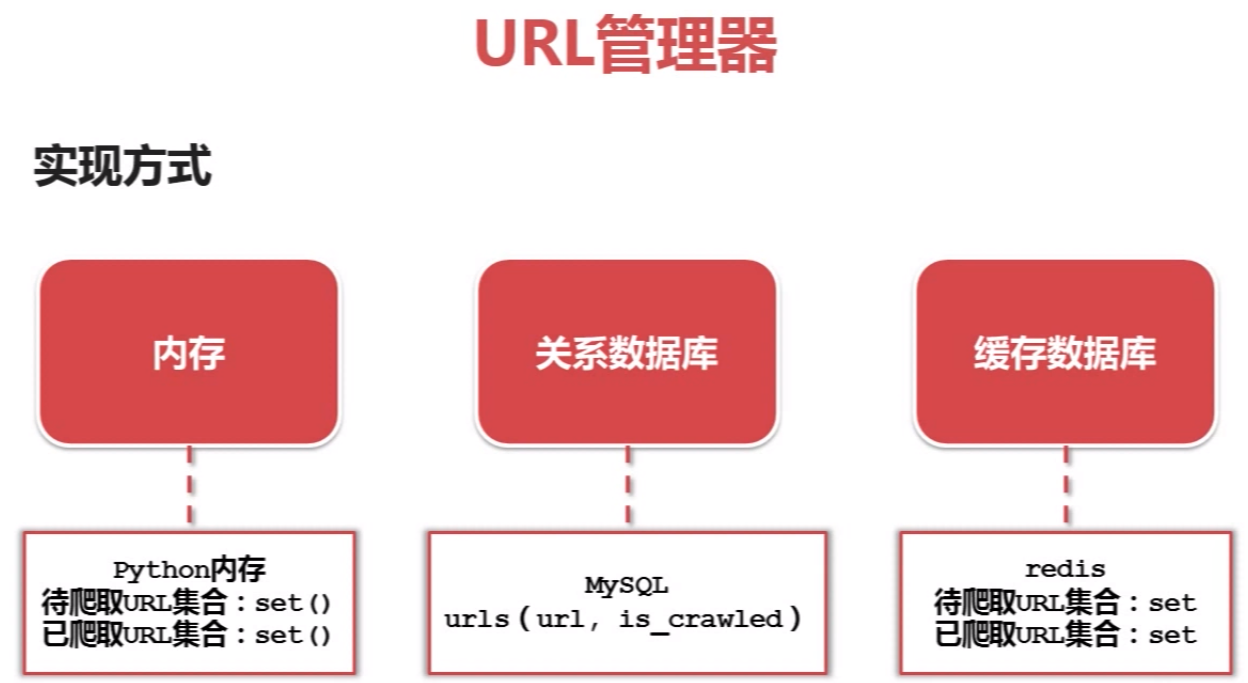
python爬虫简单架构原理及示例


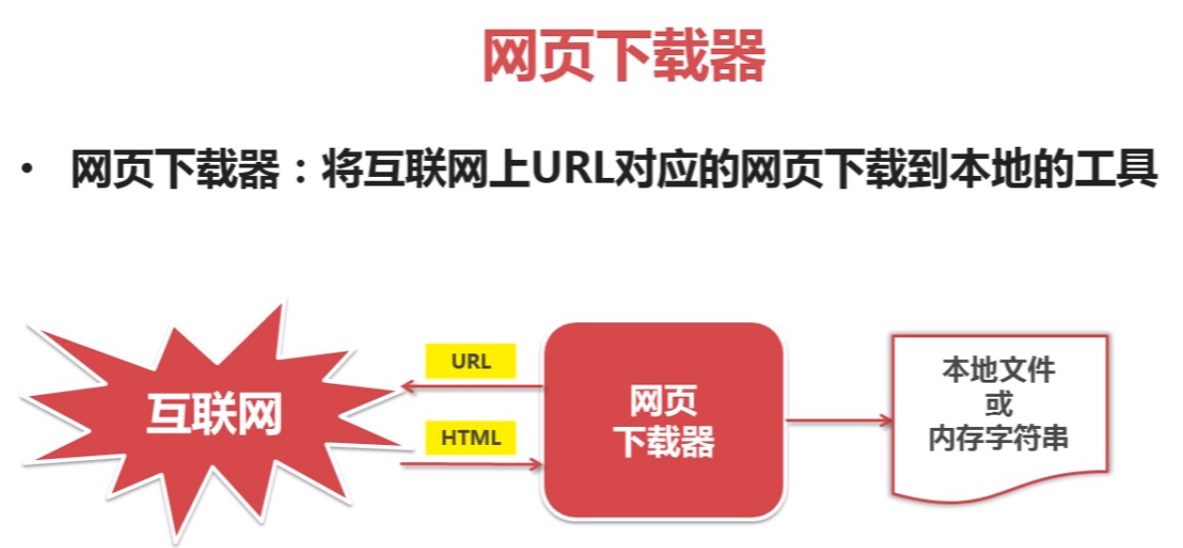

网页下载器示例:
# coding:utf-8
import urllib2
import cookielib
url = "http://www.baidu.com" print u"第一种方法"
# pip install urllib2
response1 = urllib2.urlopen(url)
print response1.getcode()
print len(response1.read()) print u"第二种方法"
request = urllib2.Request(url)
# 把爬虫伪装成浏览器
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read()) print u"第三种方法"
# pip install cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(request)
print response3.getcode()
print cj
print len(response3.read())
# 运行结果

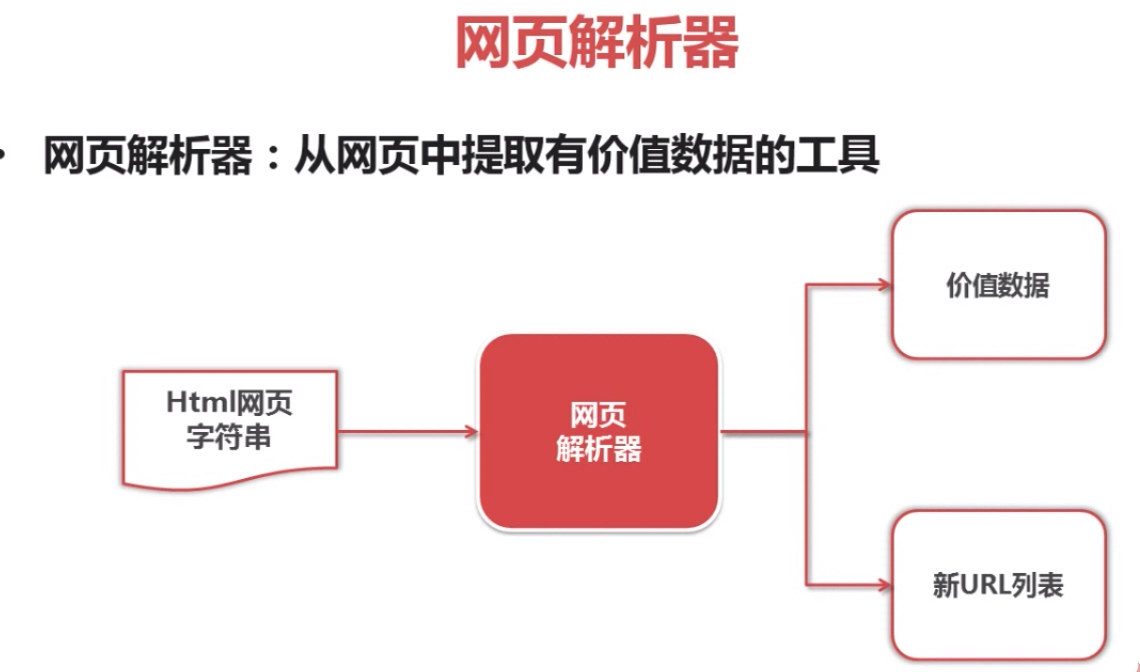

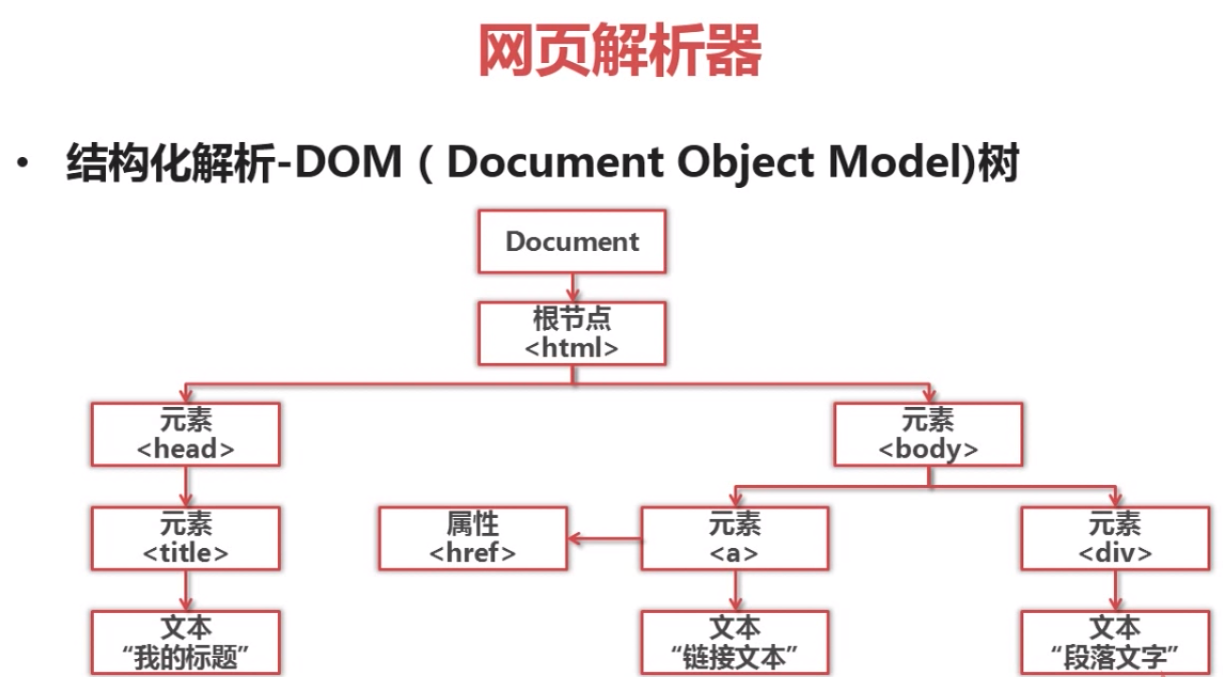
beautifulsoap使用示例
#coding:utf-8 # 安装beautifulsoap4 D:\Python27\Lib>pip install beautifulsoup4 from bs4 import BeautifulSoup
import re html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, 'html.parser', from_encoding='utf-8') print u'获取所有的链接'
links = soup.find_all('a') for link in links:
print link.name,link['href'], link.get_text() print u'获取lacie的链接'
link_node = soup.find('a', href='http://example.com/lacie')
print link_node.name, link_node['href'],link_node.get_text() print u'正则匹配'
link_node = soup.find('a', href=re.compile(r"ill"))
print link_node.name, link_node['href'],link_node.get_text() print u'获取p段落名字'
link_node = soup.find('p', class_="title")
print link_node.name, link_node.get_text()
python爬虫简单架构原理及示例的更多相关文章
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python爬虫简单入门及小技巧
刚刚申请博客,内心激动万分.于是为了扩充一下分类,随便一个随笔,也为了怕忘记新学的东西由于博主十分怠惰,所以本文并不包含安装python(以及各种模块)和python语法. 目标 前几天上B站时看到一 ...
- [python爬虫]简单爬虫功能
在我们日常上网浏览网页的时候,经常会看到某个网站中一些好看的图片,它们可能存在在很多页面当中,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材. 我们最常规的做法就是通过鼠标 ...
- Python爬虫--简单爬取图片
今天晚上弄了一个简单的爬虫,可以爬取网页的图片,现在现在做一下准备工作. 需要的库:urllib 和 re urllib库可以理解为是一个url下载器,其中有三个重要的方法 urllib.urlope ...
- python爬虫简单的添加代理进行访问
在使用python对网页进行多次快速爬取的时候,访问次数过于频繁,服务器不会考虑User-Agent的信息,会直接把你视为爬虫,从而过滤掉,拒绝你的访问,在这种时候就需要设置代理,我们可以给proxi ...
- Python爬虫简单介绍
相关环境: Python3 requests库 BeautifulSoup库 一.requests库简单使用 简单获取一个网页的源代码: import requests sessions = requ ...
- Python爬虫简单实现之Q乐园图片下载
根据需求写代码实现.然而跟我并没有什么关系,我只是打开电脑望着屏幕想着去干点什么,于是有了这个所谓的“需求”. 终于,我发现了Q乐园——到底是我老了还是我小了,这是什么神奇的网站,没听过啊,就是下面酱 ...
- 用python爬虫简单爬取 笔趣网:类“起点网”的小说
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供 ...
- Python爬虫--简单的单词查询
Refer to: https://github.com/gaopu/Python/blob/master/Dict.py 本程序参考自上面Github连接 该程序功能是输入一个单词可以给出这个单词的 ...
随机推荐
- jsonp 后台返回注意事项
前端代码 <script src="http://apps.bdimg.com/libs/jquery/1.9.1/jquery.min.js"></script ...
- [bzoj3530][Sdoi2014]数数_AC自动机_数位dp
数数 bzoj-3530 Sdoi-2014 题目大意:给你一个整数集合,求所有不超过n的正整数,是的它的十进制表示下不能再一段等于集合中的任意数. 注释:$1\le n \le 1200$,$1\l ...
- 第三篇:SpringBoot - 数据库结构版本管理与迁移
SpringBoot支持了两种数据库结构版本管理与迁移,一个是flyway,一个是liquibase.其本身也支持sql script,在初始化数据源之后执行指定的脚本,本章是基于 Liquibase ...
- I - Tunnel Warfare
I - Tunnel Warfare HDU - 1540 思路:原来以为自己已经完全理解了线段树,现在发现其实还差一些火候,做题的时候太拘泥于格式,思路不是很能放开. #include<cst ...
- 神经网络入门游戏推荐BugBrain
今天看到一款神经网络入门游戏.BugBrain.在游戏中,你能够通过连接神经元.设置神经元阈值等建造虫子的大脑,让瓢虫.蠕虫.蚂蚁等完毕各种任务.下载下来玩了玩,难度真不是入门级的= =! 真心佩服作 ...
- Visual Studio 2013 与 14
Visual Studio 2013 与 14 假设有曾经版本号的 Visual Studio.再想安装 Visual Studio 14 CTP,默认情况下是不行的. 假设一定要装,当然也是能够的. ...
- ajax传对象或者数组到后端
ajax是无法直接传送对象或者数组,有些人自己处理的话,能够把数据依照自己的标准连接成一个字符串,然后到后端处理.可是数据的不确定性.导致有可能会出错.并且麻烦 事实上有开源的包,能够直接解释成jso ...
- 国外物联网平台初探(一) ——亚马逊AWS IoT
平台定位 AWS IoT是一款托管的云平台,使互联设备可以轻松安全地与云应用程序及其他设备交互. AWS IoT可支持数十亿台设备和数万亿条消息,并且可以对这些消息进行处理并将其安全可靠地路由至 AW ...
- B1968 [Ahoi2005]COMMON 约数研究 数论
大水题,一分钟就做完了...直接枚举1~n就行了,然后在n中判断出现多少次. 题干: Description Input 只有一行一个整数 N(0 < N < 1000000). Outp ...
- JavaScript:DOM对象
ylbtech-JavaScript:DOM对象 1. HTML DOM Document 对象返回顶部 1. HTML DOM Document 对象 HTML DOM 节点 在 HTML DOM ...