Pytest(16)随机执行测试用例pytest-random-order
前言
通常我们认为每个测试用例都是相互独立的,因此需要保证测试结果不依赖于测试顺序,以不同的顺序运行测试用例,可以得到相同的结果。
pytest默认运行用例的顺序是按模块和用例命名的 ASCII 编码顺序执行的,这就意味着每次运行用例的顺序都是一样的。
app 测试里面有个 monkey 测试,随机在页面点点点,不按常理的点点点能找到更多的不稳定性 bug。那么我们在写pytest用例的时候,既然每个用例都是相互独立的,
那就可以打乱用例的顺序随机执行,用到 pytest 的插件 pytest-random-order 可以实现此目的,github 地址https://github.com/jbasko/pytest-random-order
说明
pytest-random-order是一个pytest插件,用于随机化测试顺序。这对于检测通过的恰好是有用的,因为它恰好在不相关的测试之后运行,从而使系统处于良好状态。
该插件使用户可以控制要引入的随机性级别,并禁止对测试子集进行重新排序。通过传递先前测试运行中报告的种子值,可以按特定顺序重新运行测试。
快速开始
安装
pip3 install pytest-random-order
注意
从v1.0.0开始,默认情况下,此插件不再将测试随机化。要启用随机化,您必须以下列方式之一运行pytest:
pytest --random-order
pytest --random-order-bucket=<bucket_type>
pytest --random-order-seed=<seed>
配置方式
如果要始终随机化测试顺序,请配置pytest。有很多方法可以做到这一点,我最喜欢的一种方法是addopts = --random-order在pytest选项(通常是[pytest]或[tool:pytest]部分)下添加特定
# pytest.ini文件内容
[pytest]
addopts = --random-order
案例演示
# test_random.py
def test_1():
print("用例1")
def test_2():
print("用例2")
def test_3():
print("用例3")
# test_random2.py
def test_4():
print("用例4")
def test_5():
print("用例5")
def test_6():
print("用例6")
执行命令
pytest -s --random-order
执行结果
Using --random-order-bucket=module
Using --random-order-seed=63275
collecting ...
case/random_case/test_random2.py::test_5 ✓ 17% █▋
case/random_case/test_random2.py::test_6 ✓ 33% ███▍
case/random_case/test_random2.py::test_4 ✓ 50% █████
case/random_case/test_random.py::test_3 ✓ 67% ██████▋
case/random_case/test_random.py::test_1 ✓ 83% ████████▍
case/random_case/test_random.py::test_2 ✓ 100% ██████████
Results (0.04s):
从运行的结果可以看出,默认使用--random-order-bucket=module,模块下的用例会被打乱随机执行,每次运行会重新生成--random-order-seed=63275,seed值不一样,用例的顺序也会不一样
更改重新排序与范围
要更改重新排序与范围,运行pytest --random-order-bucket=选项,其中可以是global,package,module,class,parent,grandparent:
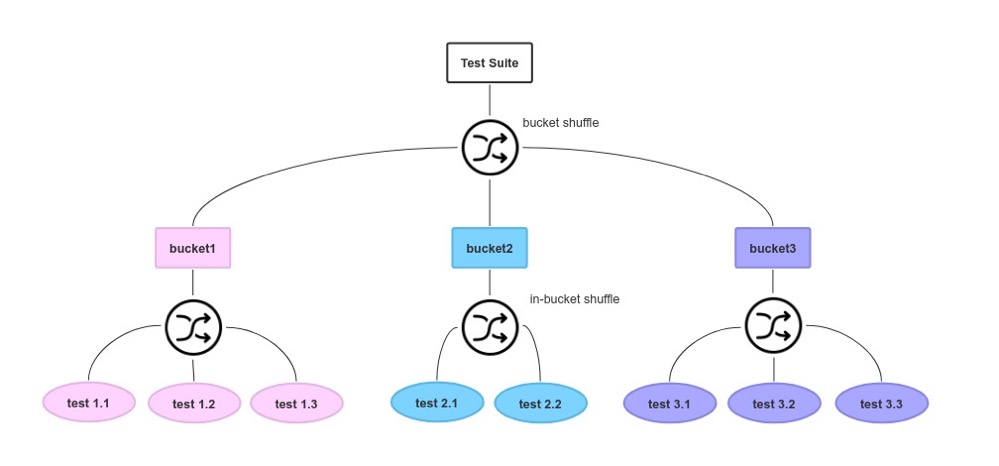
插件组在存储桶中进行测试,在存储桶中进行混洗,然后对存储桶进行混洗,设计原理如图
给定上面的测试套件,以下是一些可能生成的测试顺序中的两个:
可以从以下几种类型的存储桶中进行选择:
class 测试将在一个类中进行混洗,而各类将被混洗,但是来自一个类的测试将永远不会在其他类或模块之间运行来自其他类的测试。
- module 模块级别。如果仅使用--random-order运行pytest,同时带上参数--random-order-seed=。
- package 程序包级别。请注意,属于package的模块(以及这些模块内的测试)x.y.z不属于package x.y,因此在对存储package桶类型进行随机分配时,它们将落入不同的存储桶中。
- parent 如果使用的是不属于任何模块的自定义测试项,则可以使用此项将测试项的重新排序限制在它们所属的父级中。对于正常测试函数,父级是声明它们的模块。
- grandparent 类似于上面的parent,但是使用测试项的父级作为bucket key。
- global 所有测试属于同一存储桶,完全随机,测试可能需要更长的时间才能运行。
- none (已弃用) 禁用混洗。自1.0.4起不推荐使用,因为此插件默认不再重做测试,因此没有禁用的功能。
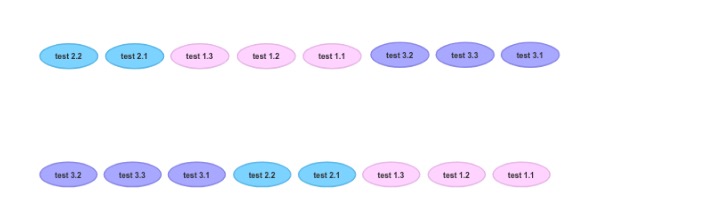
如果你有测试三个桶A,B和C三个测试1和2,并3在他们每个人,那么许多潜在的排序的一个非全局随机化可以产生可能是:
c2,c1,c3,a3,a1,a2,b3,b2,b1
运行示例,带上参数--random-order-bucket=global,所有的用例都会被打乱。
Using --random-order-bucket=global
Using --random-order-seed=784641
collecting ...
case/random_case/test_random2.py::test_5 ✓ 17% █▋
case/random_case/test_random.py::test_3 ✓ 33% ███▍
case/random_case/test_random2.py::test_6 ✓ 50% █████
case/random_case/test_random2.py::test_4 ✓ 67% ██████▋
case/random_case/test_random.py::test_2 ✓ 83% ████████▍
case/random_case/test_random.py::test_1 ✓ 100% ██████████
Results (0.04s):
6 passed
模块或类中禁用随机
如果我们在一个模块或类中,不想让里面的用例随机,可以设置 disabled=True 来禁用随机参数
模块中禁用随机
# 写在.py文件最上面即可
import pytest
pytestmark = pytest.mark.random_order(disabled=True)
def test_1():
print("用例1")
def test_2():
print("用例2")
def test_3():
print("用例3")
类中禁用随机
import pytest
class TestRandom():
pytestmark = pytest.mark.random_order(disabled=True)
def test_1(self):
print("用例1")
def test_2(self):
print("用例2")
def test_3(self):
print("用例3")
这样在执行的时候,TestRandom里面的用例顺序就是test_1,test_2,test_3不会被打乱
重现测试结果:--random-order-seed 随机种子
如果由于重新排序测试而发现测试失败,则可能希望能够以相同的失败顺序重新运行测试。为了允许重现测试订单,该插件报告其与伪随机数生成器一起使用的种子值:
============================= test session starts ==============================
..
Using --random-order-bucket=module
Using --random-order-seed=36775
...
现在,您可以使用该--random-order-seed=...位作为下一次运行的参数以产生相同的顺序:
pytest -v --random-order-seed = 36775
禁用插件
如果你觉得这个插件不好用,或者对你的其它功能会有影响,则可以将其禁用
pytest -p no:random_order
注意
默认情况下禁用随机化。通过传递,-p no:random_order您将阻止插件的注册,因此其钩子将不会被注册,并且命令行选项也不会
Pytest(16)随机执行测试用例pytest-random-order的更多相关文章
- pytest多进程/多线程执行测试用例
前言: 实际项目中的用例数量会非常多,几百上千:如果采用单进程串行执行的话会非常耗费时间.假设每条用例耗时2s,1000条就需要2000s $\approx$ 33min:还要加上用例加载.测试前/后 ...
- Python单元测试框架之pytest 1 ---如何执行测试用例
From: https://www.cnblogs.com/fnng/p/4765112.html 介绍 pytest是一个成熟的全功能的Python测试工具,可以帮助你写出更好的程序. 适合从简 ...
- pytest文档58-随机执行测试用例(pytest-random-order)
前言 通常我们认为每个测试用例都是相互独立的,因此需要保证测试结果不依赖于测试顺序,以不同的顺序运行测试用例,可以得到相同的结果. pytest默认运行用例的顺序是按模块和用例命名的 ASCII 编码 ...
- pytest测试框架 -- skip跳过执行测试用例
跳过执行测试用例 1.@pytest.mark.skip(reason=" ") -- 跳过执行测试函数 可传入一个非必须参数reason表示原因 import pytest@ ...
- 『德不孤』Pytest框架 — 6、Mark分组执行测试用例
目录 1.Pytest中的Mark介绍 2.Mark的使用 3.Mark的注册和使用 4.使用Mark完成失败重试 5.扩展 1.Pytest中的Mark介绍 Mark主要用于在测试用例/测试类中给用 ...
- Pytest命令行执行测试
Pytest命令行执行测试 from collections import namedtuple Task = namedtuple('Task', ['summary','owner','done' ...
- pytest(10)-常用执行参数说明
pytest单元测试框架中可以使用命令行及代码pytest.main()两种方式执行测试,且可以加入各种参数来组织执行测试.接下来我们来了解常用的执行参数的含义及其用法. pytest中的执行参数根据 ...
- MOOC(7)- case依赖、读取json配置文件进行多个接口请求-执行测试用例(16)
执行测试用例 # -*- coding: utf-8 -*- # @Time : 2020/2/12 22:56 # @File : run_test_16.py # @Author: Hero Li ...
- Python单元测试框架之pytest---如何执行测试用例
介绍 pytest是一个成熟的全功能的Python测试工具,可以帮助你写出更好的程序. 适合从简单的单元到复杂的功能测试 l 模块化parametrizeable装置(在2.3,持续改进) l 参 ...
随机推荐
- Promise入门到精通(初级篇)-附代码详细讲解
Promise入门到精通(初级篇)-附代码详细讲解 Promise,中文翻译为承诺,约定,契约,从字面意思来看,这应该是类似某种协议,规定了什么事件发生的条件和触发方法. Pr ...
- 【Azure Redis 缓存】Azure Redis功能性讨论
关于使用Azure Redis服务在以下九大方面的功能性的解说: 高可用 备份可靠性 配置自动化 部署多样性 快速回档功能 数据扩容 SLA稳定性 数据安全性 监控系统 一:高可用 Azure Cac ...
- 借助window.performance实现基本的前端基础性能监控日志
借助window.performance实现基本的前端基础性能监控日志并二次重写console方法方便日常前端console日志的调试 npm install sn-console
- 【Java基础】Eclipse 和数组
Eclipse 和数组 Eclipse 安装和使用 ... 数组的概述 数组(Array):是多个相同类型数据按一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行统一管理. 数组相 ...
- java调用js代码
jdk8里使用脚本引擎调用js 1.定义一个js方法: function getRouteInfo(province){ //注意,参数不要带var..在java里执行会报错.. if (provin ...
- 按装parallels tool的失败之路
这是一篇对于其他人来说没什么意义的博客.单纯的可以被看作是日记. 首先,我想安装parallels tool. 但是照着网上很多教程(如www.cnblogs.com/artwalker/p/1323 ...
- java8 stream api流式编程
java8自带常用的函数式接口 Predicate boolean test(T t) 传入一个参数返回boolean值 Consumer void accept(T t) 传入一个参数,无返回值 F ...
- 【Java】网络编程之NIO
简单记录 慕课网-解锁网络编程之NIO的前世今生 & 一站式学习Java网络编程 全面理解BIO/NIO/AIO 内容概览 文章目录 1.[了解] NIO网络编程模型 1.1.NIO简介 1. ...
- libnum报错问题解决
之前在使用python libnum库时报错 附上报错内容 Traceback (most recent call last) : File" D:/python file/ctf/RSA共 ...
- 【开源】我和 JAP(JA Plus) 的故事
JA Plus 故事 程序员的故事如此简单之绕不过去的开源情结 我们准备做一件伟大的事,也可以说是一件真真正正普惠的事. 絮 是的,你没有看错,就是"絮"而非"序&quo ...