图的广度优先遍历算法(BFS)
在上一篇文章我们用java演示了图的数据结构以及图涉及到的深度优先遍历算法,本篇文章将继续演示图的广度优先遍历算法。广度优先遍历算法主要是采用了分层的思想进行数据搜索。其中也需要使用另外一种数据结构队列,本篇文章为了使代码更加优雅,所有使用java中Linkedlist集合来进行模拟队列。因为该集合有在队列尾部添加元素和从队头取出元素的API。
算法思想:
1.先访问一个元素,然后放到队列中,并且标记已经访问过该元素。
2.然后判断队列是否为空,不为空则取出队头元素。
3.然后取出队头元素的第一个邻接节点并判断该元素是否存在。
4.如果存在再次判断该元素有没有被访问过。
5.如果没有访问过则标记为访问过。同时放到队列中。
6.如果访问过则以头节点为前驱节点,第一个邻接节点为第二个参数查找队头节点的下面的邻接节点
代码以下图为参考:
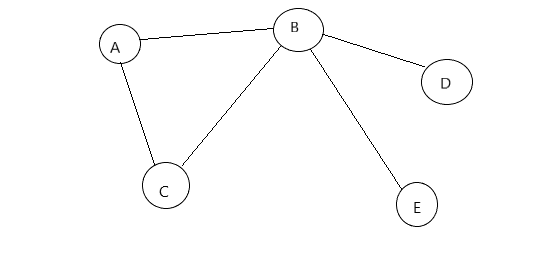
代码如下:


1 import java.util.ArrayList;
2 import java.util.Arrays;
3 import java.util.LinkedList;
4
5
6 public class Graph {
7
8 //创建一个集合用来存放顶点
9 private ArrayList<String> arrayList;
10 //创建一个二位数组来作为邻接矩阵
11 private int[][] TwoArray;
12 //边的数目
13 private int numOfEdges;
14 //使用一个数组记录节点是否被访问过
15 private boolean[] isVisted;
16 public static void main(String[] args) {
17 Graph graph = new Graph(5);
18 //测试
19 String[] ver={"A","B","C","D","E"};
20 //将节点放到集合中
21 for (String s : ver) {
22 graph.InsertVex(s);
23 }
24 //设置边
25 //A-B A-C B-C B-D B-E
26 graph.InsertEdeges(0,1,1);
27 graph.InsertEdeges(0,2,1);
28 graph.InsertEdeges(1,2,1);
29 graph.InsertEdeges(1,3,1);
30 graph.InsertEdeges(1,4,1);
31 //显示
32 graph.Show();
33 graph.BFS();
34 }
35
36 //初始化数据
37 public Graph(int n){
38 arrayList=new ArrayList<>(n);
39 TwoArray=new int[n][n];
40 numOfEdges=0;
41 isVisted=new boolean[n];
42 }
43
44 /**
45 * 根据节点的下标返回第一个邻接节点的下标
46 * @param index 节点的下标
47 * @return
48 */
49 public int getFirstVex(int index){
50 for (int i = 0; i < arrayList.size(); i++) {
51 if(TwoArray[index][i]!=0){
52 return i;
53 }
54 }
55 return -1;
56 }
57
58 /**
59 * 根据前一个节点下标获取下一个节点的下标
60 * @param v1 找到的第一个节点的
61 * @param v2 找到的第一个邻接节点并且被访问过的
62 * @return
63 */
64 public int getNextVex(int v1,int v2){
65 for (int i = v2+1; i < numEdges(); i++) {
66 if(TwoArray[v1][i]!=0){
67 return i;
68 }
69 }
70 return -1;
71 }
72
73 /**
74 * 广度优先遍历
75 * @param isVisted 记录是否被访问过的数组
76 * @param i 想要访问的节点下标
77 */
78 public void BFS(boolean[] isVisted,int i){
79 //表示队列头节点的下标
80 int u;
81 //用于存放队列头节点的第一个邻接节点
82 int w;
83 //定义一个队列用来存放节点
84 LinkedList<Object> queue = new LinkedList<>();
85 //访问该节点
86 System.out.print(getValue(i)+"->");
87 //在数组中标记为该下标已经被访问过了
88 isVisted[i]=true;
89 //把访问过的节点下标放到队列中,放到队列的尾部
90 queue.addLast(i);
91 //判断队列是否为空
92 while (!queue.isEmpty()){
93 //队列不为空,那么取出队列的头节点的下标
94 u=(Integer) queue.removeFirst();
95 //获取头节点的第一个邻接节点的下标
96 w = getFirstVex(u);
97 //判断该节点是否存在
98 while (w!=-1){
99 //说明存在,在判断是否被访问过
100 if(!isVisted[w]){
101 //没有访问过,标记为已访问
102 isVisted[w]=true;
103 //输出
104 System.out.print(getValue(w)+"->");
105 //访问完加入队列中
106 queue.addLast(w);
107 }
108 //以u作为前驱节点,w作为u刚刚访问过的节点,来查找w的下一个邻接节点
109 w = getNextVex(u, w);
110 }
111 }
112 }
113
114 public void BFS(){
115 for (int i = 0; i < arrayList.size(); i++) {
116 if(!isVisted[i]){
117 BFS(isVisted,i);
118 }
119 }
120 }
121
122 /**
123 * 添加节点
124 * @param vex
125 */
126 public void InsertVex(String vex){
127 arrayList.add(vex);
128 }
129
130 /**
131 * 设置边
132 * @param v1 第一个节点对应的下标
133 * @param v2 第二节点对应的下标
134 * @param weight 两个节点对应的权值
135 */
136 public void InsertEdeges(int v1,int v2,int weight){
137 TwoArray[v1][v2]=weight;
138 TwoArray[v2][v1]=weight;
139 numOfEdges++;
140 }
141
142 /**
143 * 返回节点对应的个数
144 * @return
145 */
146 public int numVex(){
147 return arrayList.size();
148 }
149
150 /**
151 * 返回边的总个数
152 * @return
153 */
154 public int numEdges(){
155 return numOfEdges;
156 }
157
158 /**
159 * 显示邻接矩阵(图的展示)
160 */
161 public void Show(){
162 for (int[] ints : TwoArray) {
163 System.out.println(Arrays.toString(ints));
164 }
165 }
166
167 /**
168 * 根据下标获取对应的数据
169 * @param i 下标
170 * @return
171 */
172 public String getValue(int i){
173 return arrayList.get(i);
174 }
175
176 public int getWeight(int v1,int v2){
177 int weight=TwoArray[v1][v2];
178 return weight;
179 }
180 }
图的广度优先遍历算法(BFS)的更多相关文章
- 《图论》——广度优先遍历算法(BFS)
十大算法之广度优先遍历: 本文以实例形式讲述了基于Java的图的广度优先遍历算法实现方法,详细方法例如以下: 用邻接矩阵存储图方法: 1.确定图的顶点个数和边的个数 2.输入顶点信息存储在一维数组ve ...
- 数据结构与算法之PHP用邻接表、邻接矩阵实现图的广度优先遍历(BFS)
一.基本思想 1)从图中的某个顶点V出发访问并记录: 2)依次访问V的所有邻接顶点: 3)分别从这些邻接点出发,依次访问它们的未被访问过的邻接点,直到图中所有已被访问过的顶点的邻接点都被访问到. 4) ...
- 图的广度优先遍历(bfs)
广度优先遍历: 1.将起点s 放入队列Q(访问) 2.只要Q不为空,就循环执行下列处理 (1)从Q取出顶点u 进行访问(访问结束) (2)将与u 相邻的未访问顶点v 放入Q, 同时将d[v]更新为d[ ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- PTA 邻接表存储图的广度优先遍历(20 分)
6-2 邻接表存储图的广度优先遍历(20 分) 试实现邻接表存储图的广度优先遍历. 函数接口定义: void BFS ( LGraph Graph, Vertex S, void (*Visit)(V ...
- 饥饿的小易(枚举+广度优先遍历(BFS))
题目描述 小易总是感觉饥饿,所以作为章鱼的小易经常出去寻找贝壳吃.最开始小易在一个初始位置x_0.对于小易所处的当前位置x,他只能通过神秘的力量移动到 4 * x + 3或者8 * x + 7.因为使 ...
- PTA 邻接表存储图的广度优先遍历
试实现邻接表存储图的广度优先遍历. 函数接口定义: void BFS ( LGraph Graph, Vertex S, void (*Visit)(Vertex) ) 其中LGraph是邻接表存储的 ...
- 算法学习 - 图的广度优先遍历(BFS) (C++)
广度优先遍历 广度优先遍历是非经常见和普遍的一种图的遍历方法了,除了BFS还有DFS也就是深度优先遍历方法.我在我下一篇博客里面会写. 遍历过程 相信每一个看这篇博客的人,都能看懂邻接链表存储图. 不 ...
- 怎样实现广度优先遍历(BFS)
BFS过程: 一:訪问顶点V,并标记V为已经訪问 二:顶点V入队列 三:假设队列非空.进行运行,否则算法结束 四:出队列取得对头顶点u,假设顶点未被訪问,就訪问该顶点,并标记该顶点为已经訪问 五:查找 ...
随机推荐
- Netty tcnative boringssl windows 32-bit 编译
1 问题 在使用Netty SSL时,我们往往会采用netty-tcnative-boringssl组件.但是netty-tcnative-boringssl在Windows上仅有64位版本的,没有3 ...
- app逆向万能的md5加密hook破解入参方法(其他加密用通用方法原理差不多,小白推荐)
一.原理 安卓开发调用md5加密时候都会调用到系统类java.security.MessageDigest 加密时候会会调用里面2个关键方法update以及digest 根据这个原理我们开始写代码吧 ...
- Head First 设计模式 —— 05. 单例模式
全局变量的缺点 如果将对象赋值给一个全局变量,那么必须在程序一开始就创建好对象 P170 和 JVM 实现有关,有些 JVM 的实现是:在用到的时候才创建对象 思考题 Choc-O-Holic 公司使 ...
- #1使用html+css+js制作网站教程 准备
#1使用html+css+js制作网站教程 准备 本系列链接 0 准备 0.1 IDE编辑软件 0.2 浏览器 0.3 基础概念 0.3.1 html 0.3.2 css 0.3.3 js 0.4 文 ...
- Viser报错:dodge is not support linear attribute, please use category attribute!
遇到这样的问题是因为x轴数据不能为为连续性的日期(日期格式为:YYYY-MM-DD),需要设置为分类属性(cat),有一些可能设置为timeCat,看具体情况 scale 参数支持以下类型 • ide ...
- Flutter 基础组件:文本、字体样式
// 文本.字体样式 import 'package:flutter/material.dart'; class TextFontStyle extends StatelessWidget { // ...
- Linux学习笔记 | 常见错误之账户密码正确但是登录不进去系统
前言: 笔者今日由于Linux版本的原因,需要Linux内核版本不能太高的系统,而日常使用的ubuntu系统不能满足需求,于是新建了一个虚拟机,选用的系统是Ubuntu16的,配置了一下午的各种依赖环 ...
- CAN总线采样点测试
采样点是什么? 采样点是接受节点判断信号逻辑的位置,CAN通讯属于异步通讯.需要通过不断的重新同步才能保证收发节点的采样准确. 若采样点太靠前,则因为线缆原因,DUT外发报文尚未稳定,容易发生采样错误 ...
- 利用vbs隐藏dos窗口
方法一: option explicitdim wshshellset wshshell=wscript.createobject("wscript.shell")wshshell ...
- Hadoop2.7.7阿里云安装部署
阿里云的网络环境不需要我们配置,如果是在自己电脑上的虚拟机,虚拟机的安装步骤可以百度.这里是单机版的安装(也有集群模式的介绍)使用Xshell连接阿里云主机,用命令将自己下载好的安装包上传到服务器 # ...