利用Jsoup爬取新冠疫情数据并存至数据库
需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar)
链接:https://pan.baidu.com/s/1VlylWmlhjd8Ka8VTruQEnA 提取码:dxeq
爬取的原网站为:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
Paqu.java
package control;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput; import Dao.AddService; public class Paqu { public static void main(String args[]) {
// TODO Auto-generated method stub
String sheng="";
String xinzeng="";
String leiji="";
String zhiyu="";
String siwang="";
String url = "https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1"; int i=0; try {
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(8000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(6000);
String html = rootPage.asXml();
Document doc = Jsoup.parse(html);
//System.out.println(doc);
Element listdiv1 = doc.select(".wrap").first();
Elements listdiv2 = listdiv1.select(".province");
for(Element s:listdiv2) {
Elements span = s.getElementsByTag("span");
Elements real_name=span.select(".item_name");
Elements real_newconfirm=span.select(".item_newconfirm");
Elements real_confirm=span.select(".item_confirm");
Elements real_dead=span.select(".item_dead");
Elements real_heal=span.select(".item_heal");
sheng=real_name.text();
xinzeng=real_newconfirm.text();
leiji=real_confirm.text();
zhiyu=real_heal.text();
siwang=real_dead.text();
//System.out.println(sheng+" 新增确诊:"+xinzeng+" 累计确诊:"+leiji+" 累计治愈:"+zhiyu+" 累计死亡:"+siwang);
Date currentTime=new Date();
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm");
String time = formatter.format(currentTime);//获取当前时间
AddService dao=new AddService();
dao.add("myinfo", sheng, xinzeng, leiji, zhiyu, siwang,time);//将爬取到的数据添加至数据库
} } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("爬取失败");
}
} }
AddService.java:
package Dao; import java.sql.Connection;
import java.sql.Statement; import utils.DBUtils; public class AddService {
public void add(String table,String sheng,String xinzeng,String leiji,String zhiyu,String dead,String time) {
String sql = "insert into "+table+" (Province,Newconfirmed_num ,Confirmed_num,Cured_num,Dead_num,Time) values('" + sheng + "','" + xinzeng +"','" + leiji +"','" + zhiyu + "','" + dead+ "','" + time+ "')";
System.out.println(sql);
Connection conn = DBUtils.getConn();
Statement state = null;
int a = 0;
try {
state = conn.createStatement();
a=state.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
DBUtils.close(state, conn);
}
}
}
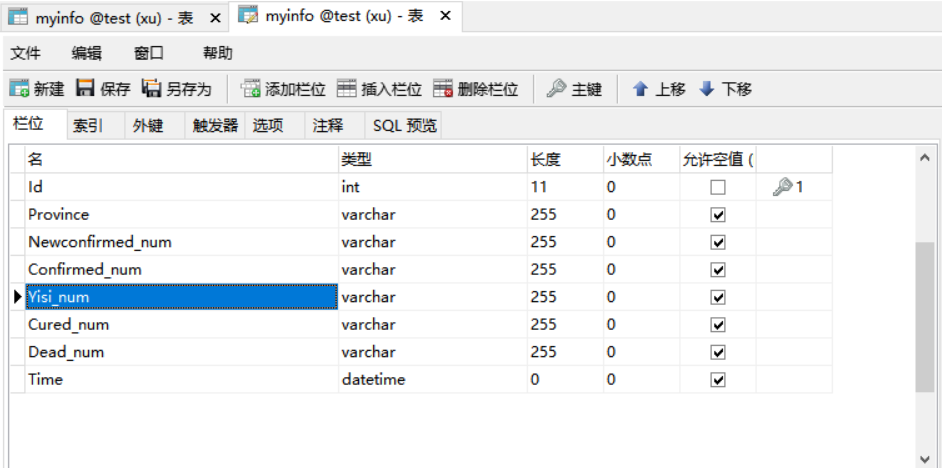
数据库建表如下:
遇到的问题
一开始的数据是动态加载的,无法获取确定的数据,最后在代码中添加了一段js内容来获取动态数据。
其中还尝试过爬取其他的网站上的数据,但doc并不能很好的输出,只能输出网站的大框架,无法获取具体到内容。
利用Jsoup爬取新冠疫情数据并存至数据库的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- 利用Crawlspider爬取腾讯招聘数据(全站,深度)
需求: 使用crawlSpider(全站)进行数据爬取 - 首页: 岗位名称,岗位类别 - 详情页:岗位职责 - 持久化存储 代码: 爬虫文件: from scrapy.linkextractors ...
- python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系. 注:未使用接口,仅爬虫学习,不做任何违法操作. """ 新浪财经,爬取历史股票数据 ""&q ...
- Java爬取丁香医生疫情数据并存储至数据库
1.通过页面的url获取html代码 // 根URL private static String httpRequset(String requesturl) throws IOException { ...
- java 利用jsoup 爬取知乎首页问题
今天学了下java的爬虫,首先要下载jsoup的包,然后导入,导入过程:首先右击工程:Build Path ->configure Build Path,再点击Add External JARS ...
- 利用jsoup爬取百度网盘资源分享连接(多线程)
突然有一天就想说能不能用某种方法把百度网盘上分享的资源连接抓取下来,于是就动手了.知乎上有人说过最好的方法就是http://pan.baidu.com/wap抓取,一看果然链接后面的uk值是一串数字, ...
- Python:爬取全国各省疫情数据并在地图显示
代码: import requests import pymysql import json from pyecharts import options as opts from pyecharts. ...
- 5分钟python爬虫案例,手把手教爬取国内外最新疫情历史数据
俗话说的好,“授之以鱼不如授之以渔”,所以小编今天就把爬疫情历史数据的方法分享给你们. 基本思路:分析腾讯新闻“抗肺炎”版块,采用“倒推法”找到疫情数据接口,然后用python模拟请求,进而保存疫情历 ...
随机推荐
- web notification api
Web Notifications API 使页面可以发出通知,通知将被显示在页面之外的系统层面上(通常使用操作系统的标准通知机制,但是在不同的平台和浏览器上的表现会有差异) 要显示一条通知,你需要先 ...
- C#各类集合介绍
集合(Collection)类是专门用于数据存储和检索的类.这些类提供了对栈(stack).队列(queue).列表(list)和哈希表(hash table)的支持.大多数集合类实现了相同的接口. ...
- ASP.NET Core3.1使用Identity Server4建立Authorization Server-2
前言 建立Web Api项目 在同一个解决方案下建立一个Web Api项目IdentityServer4.WebApi,然后修改Web Api的launchSettings.json.参考第一节,当然 ...
- Database Identifiers - SID
These options include your global database name and system identifier (SID). The SID is a unique ide ...
- pyinstall打包资源文件
相关代码 main.py import sys import os #生成资源文件目录访问路径 #说明: pyinstaller工具打包的可执行文件,运行时sys.frozen会被设置成True # ...
- Laravel 5.4 使用 Mail 发送邮件获取验证码功能(使用的配置邮箱为126邮箱)
<?php namespace App\Modules\Liveapi\Http\Controllers\Personnel; use App\Modules\Liveapi\Http\Cont ...
- Ubuntu查看和设置Root账户
前言: 要在Linux中运行管理任务,必须要具有root(也称为超级用户)访问权限.在大多数Linux发行版中,拥有一个单独的root账户是很常见的,但是Ubuntu默认禁用root账户.这可以防止用 ...
- set自动排序去重 stringstream流分割字符
链接:https://vjudge.net/problem/UVA-10815#author=0 题意:给几段句子,按字典序筛选出单词. 题解:用C的话太麻烦,不如用自动去重并排序的set容器.有个地 ...
- CentOS7 安装nginx部署vue项目
简单描述:代码开发完了,需要环境来运行测试.服务器上没有nginx,搞起搞起. 在Centos下,yum源不提供nginx的安装,可以通过切换yum源的方法获取安装.也可以通过直接下载安装包的方法 ...
- apache配置Directory目录权限的一些配置
可以使用<Directory 目录路径>和</Directory>这对语句为主目录或虚拟目录设置权限,它们是一对容器语句,必须成对出现,它们之间封装的是具体 的设置目录权限语句 ...