利用Jsoup爬取新冠疫情数据并存至数据库
需要用到的jar包(用来爬取的jsoup,htmlunit-2.37.0-bin以及连接数据库中的mysql.jar)
链接:https://pan.baidu.com/s/1VlylWmlhjd8Ka8VTruQEnA 提取码:dxeq
爬取的原网站为:https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
Paqu.java
package control;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput; import Dao.AddService; public class Paqu { public static void main(String args[]) {
// TODO Auto-generated method stub
String sheng="";
String xinzeng="";
String leiji="";
String zhiyu="";
String siwang="";
String url = "https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1"; int i=0; try {
//构造一个webClient 模拟Chrome 浏览器
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//支持JavaScript
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(8000);
HtmlPage rootPage = webClient.getPage(url);
//设置一个运行JavaScript的时间
webClient.waitForBackgroundJavaScript(6000);
String html = rootPage.asXml();
Document doc = Jsoup.parse(html);
//System.out.println(doc);
Element listdiv1 = doc.select(".wrap").first();
Elements listdiv2 = listdiv1.select(".province");
for(Element s:listdiv2) {
Elements span = s.getElementsByTag("span");
Elements real_name=span.select(".item_name");
Elements real_newconfirm=span.select(".item_newconfirm");
Elements real_confirm=span.select(".item_confirm");
Elements real_dead=span.select(".item_dead");
Elements real_heal=span.select(".item_heal");
sheng=real_name.text();
xinzeng=real_newconfirm.text();
leiji=real_confirm.text();
zhiyu=real_heal.text();
siwang=real_dead.text();
//System.out.println(sheng+" 新增确诊:"+xinzeng+" 累计确诊:"+leiji+" 累计治愈:"+zhiyu+" 累计死亡:"+siwang);
Date currentTime=new Date();
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm");
String time = formatter.format(currentTime);//获取当前时间
AddService dao=new AddService();
dao.add("myinfo", sheng, xinzeng, leiji, zhiyu, siwang,time);//将爬取到的数据添加至数据库
} } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println("爬取失败");
}
} }
AddService.java:
package Dao; import java.sql.Connection;
import java.sql.Statement; import utils.DBUtils; public class AddService {
public void add(String table,String sheng,String xinzeng,String leiji,String zhiyu,String dead,String time) {
String sql = "insert into "+table+" (Province,Newconfirmed_num ,Confirmed_num,Cured_num,Dead_num,Time) values('" + sheng + "','" + xinzeng +"','" + leiji +"','" + zhiyu + "','" + dead+ "','" + time+ "')";
System.out.println(sql);
Connection conn = DBUtils.getConn();
Statement state = null;
int a = 0;
try {
state = conn.createStatement();
a=state.executeUpdate(sql);
} catch (Exception e) {
e.printStackTrace();
} finally {
DBUtils.close(state, conn);
}
}
}
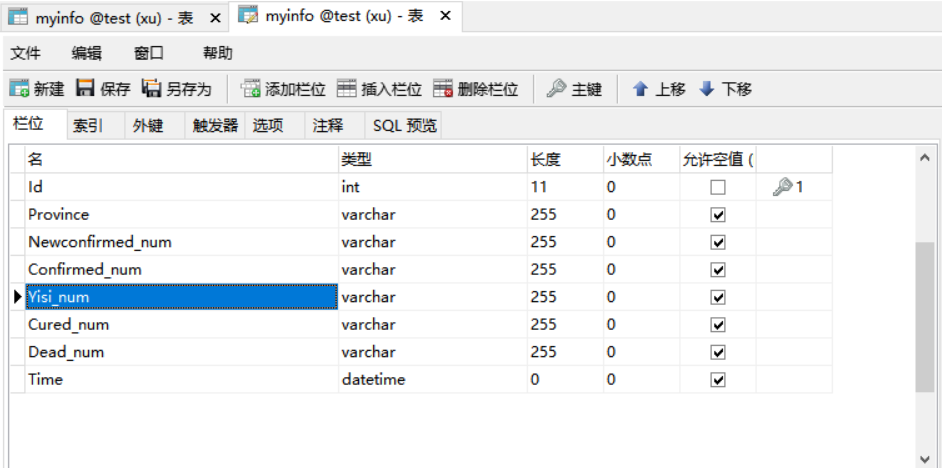
数据库建表如下:
遇到的问题
一开始的数据是动态加载的,无法获取确定的数据,最后在代码中添加了一段js内容来获取动态数据。
其中还尝试过爬取其他的网站上的数据,但doc并不能很好的输出,只能输出网站的大框架,无法获取具体到内容。
利用Jsoup爬取新冠疫情数据并存至数据库的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- 利用Crawlspider爬取腾讯招聘数据(全站,深度)
需求: 使用crawlSpider(全站)进行数据爬取 - 首页: 岗位名称,岗位类别 - 详情页:岗位职责 - 持久化存储 代码: 爬虫文件: from scrapy.linkextractors ...
- python爬取新浪股票数据—绘图【原创分享】
目标:不做蜡烛图,只用折线图绘图,绘出四条线之间的关系. 注:未使用接口,仅爬虫学习,不做任何违法操作. """ 新浪财经,爬取历史股票数据 ""&q ...
- Java爬取丁香医生疫情数据并存储至数据库
1.通过页面的url获取html代码 // 根URL private static String httpRequset(String requesturl) throws IOException { ...
- java 利用jsoup 爬取知乎首页问题
今天学了下java的爬虫,首先要下载jsoup的包,然后导入,导入过程:首先右击工程:Build Path ->configure Build Path,再点击Add External JARS ...
- 利用jsoup爬取百度网盘资源分享连接(多线程)
突然有一天就想说能不能用某种方法把百度网盘上分享的资源连接抓取下来,于是就动手了.知乎上有人说过最好的方法就是http://pan.baidu.com/wap抓取,一看果然链接后面的uk值是一串数字, ...
- Python:爬取全国各省疫情数据并在地图显示
代码: import requests import pymysql import json from pyecharts import options as opts from pyecharts. ...
- 5分钟python爬虫案例,手把手教爬取国内外最新疫情历史数据
俗话说的好,“授之以鱼不如授之以渔”,所以小编今天就把爬疫情历史数据的方法分享给你们. 基本思路:分析腾讯新闻“抗肺炎”版块,采用“倒推法”找到疫情数据接口,然后用python模拟请求,进而保存疫情历 ...
随机推荐
- picker-view、微信小程序自定义时间选择器(非官方)
picker-view自定义时间选择器 官网的自定义时间选择器比较简陋.日期不准 下面是我自己写的一个demo <view class="baseList"> < ...
- bzoj3062[Usaco2013 Feb]Taxi*
bzoj3062[Usaco2013 Feb]Taxi 题意: Bessie在农场上为其他奶牛提供出租车服务,她必须赶到这些奶牛的起始位置,并把他们带到它们的目的地.Bessie的车很小,所以她只能一 ...
- Json对象,Json数组,Json字符串的区别
Json对象: var str = {"姓名":"张三","性别":"男","年龄":"2 ...
- sql多表语句
多条件查询条件判空 最优写法 3三表带条件查询
- react中实现可拖动div
把拖动div功能用react封装成class,在页面直接引入该class即可使用. title为可拖动区域.panel为要实现拖动的容器. 优化了拖动框超出页面范围的情况,也优化了拖动太快时鼠标超出可 ...
- 第三章:View的事件体系
3.1 View的基础知识 主要有:View的位置参数,MotionEvent和TouchSlop对象,VelocityTracker,GestureDetector和Scroller对象 3.1.1 ...
- 导出Telegram贴纸
如何导出Telegram的贴纸1.在Telegram中 @StickerSetBot 机器人2.输入 /newpack 开启机器人,会提示 OK now send me stickers or sti ...
- GitHub 热点速览 Vol.29:程序员资料大全
作者:HelloGitHub-小鱼干 摘要:有什么资料比各种大全更吸引人的呢?先马为敬,即便日后"挺尸"收藏夹,但是每个和程序相关的大全项目都值得一看.比如国内名为小傅哥整理的 J ...
- [日常摘要] -- ThreadLocal篇
简介 ThreadLocal,即线程变量,是一个以ThreadLocal对象为键.任意对象为值的存储结构.这个结构被附带在线程上,也就是说一个线程可以根据一个ThreadLocal对象查询到绑定在这个 ...
- 感知机算法(PLA)代码实现
目录 1. 引言 2. 载入库和数据处理 3. 感知机的原始形式 4. 感知机的对偶形式 5. 多分类情况-one vs. rest 6. 多分类情况-one vs. one 7. sklearn实现 ...