阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
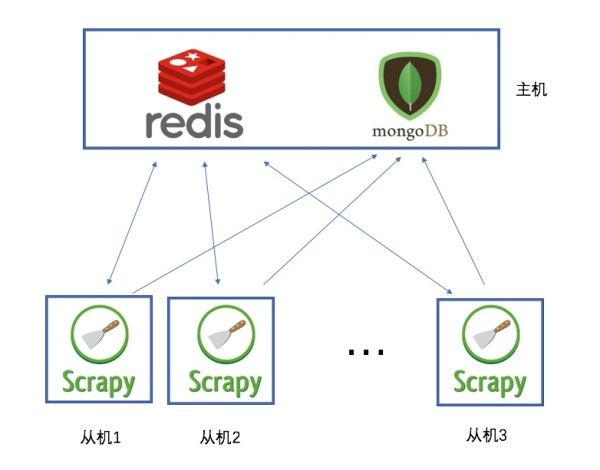
说白了,就是使用redis来维护一个url队列,然后scrapy爬虫都连接这一个redis获取url,且当爬虫在redis处拿走了一个url后,redis会将这个url从队列中清除,保证不会被2个爬虫拿到同一个url,即使可能2个爬虫同时请求拿到同一个url,在返回结果的时候redis还会再做一次去重处理,所以这样就能达到分布式效果,我们拿一台主机做redis 队列,然后在其他主机上运行爬虫.且scrapy-redis会一直保持与redis的连接,所以即使当redis 队列中没有了url,爬虫会定时刷新请求,一旦当队列中有新的url后,爬虫就立即开始继续爬
首先分别在主机和从机上安装需要的爬虫库
pip3 install requests scrapy scrapy-redis redis
在主机中安装redis
#安装redis
yum install redis 启动服务
systemctl start redis 查看版本号
redis-cli --version 设置开机启动
systemctl enable redis.service
修改redis配置文件 vim /etc/redis.conf 将保护模式设为no,同时注释掉bind,为了可以远程访问,另外需要注意阿里云安全策略也需要暴露6379端口
改完配置后,别忘了重启服务才能生效
systemctl restart redis
然后分别新建爬虫项目
scrapy startproject myspider
在项目的spiders目录下新建test.py
#导包
import scrapy
import os
from scrapy_redis.spiders import RedisSpider #定义抓取类
#class Test(scrapy.Spider):
class Test(RedisSpider): #定义爬虫名称,和命令行运行时的名称吻合
name = "test" #定义redis的key
redis_key = 'test:start_urls' #定义头部信息
haders = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.86 Chrome/73.0.3683.86 Safari/537.36'
} def parse(self, response):
print(response.url)
pass
然后修改配置文件settings.py,增加下面的配置,其中redis地址就是在主机中配置好的redis地址:
BOT_NAME = 'myspider' SPIDER_MODULES = ['myspider.spiders']
NEWSPIDER_MODULE = 'myspider.spiders' #设置中文编码
FEED_EXPORT_ENCODING = 'utf-8' # scrapy-redis 主机地址
REDIS_URL = 'redis://root@39.106.228.179:6379'
#队列调度
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#不清除缓存
SCHEDULER_PERSIST = True
#通过redis去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#不遵循robots
ROBOTSTXT_OBEY = False
最后,可以在两台主机上分别启动scrapy服务
scrapy crawl test
此时,服务已经起来了,只不过redis队列中没有任务,在等待状态
进入主机的redis
redis-cli
将任务队列push进redis
lpush test:start_urls http://baidu.com
lpush test:start_urls http://chouti.com
可以看到,两台服务器的爬虫服务分别领取了队列中的任务进行抓取,同时利用redis的特性,url不会重复抓取
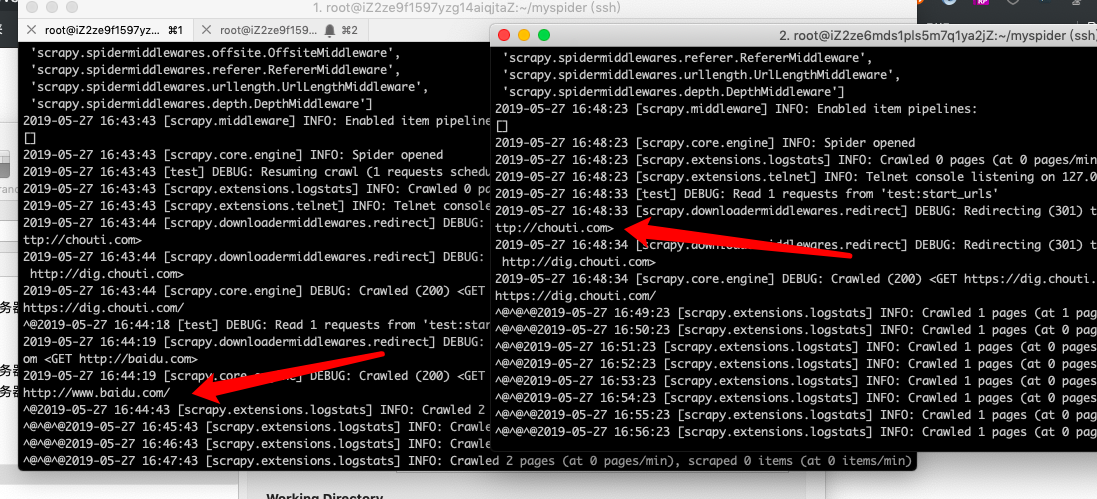
爬取任务结束之后,可以通过flushdb命令来清除地址指纹,这样就可以再次抓取历史地址了。
阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis的更多相关文章
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
- 在阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4
上次在网上找了一个在阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4的文档,可能是这个文档不是最新版的,安装的时候遇到了很多问题, 最后跟一个大神要了一 ...
- 阿里云Centos7.6中部署nginx1.16+uwsgi2.0.18+Django2.0.4
当你购买了阿里云的ecs,涉及ecs的有两个密码,一定要搞清楚,一个密码是远程链接密码,也就是通过浏览器连接服务器的密码,另外一个是实例密码,这个密码就是ecs的root密码,一般情况下,我们经常用到 ...
- 【Docker】 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二)
系列目录: [Docker] CentOS7 安装 Docker 及其使用方法 ( 一 ) [Docker] 使用Docker 在阿里云 Centos7 部署 MySQL 和 Redis (二) [D ...
- 新手之首次部署阿里云centos7+mysql+asp.net mvc core应用之需要注意的地方
先来几个字,坑坑坑. 自己业余爱好者,签名一直捣鼓net+mssql,前阵买了阿里云esc,自己尝试做个博客,大体架子都打好了,本地安装了mysql,测试了也没问题. 部署到阿里云centos7,结果 ...
- 阿里云CentOS7部署ASP.NET Core
本文主要介绍了阿里云CentOS7下如何成功的发布ASP.Core应用并使用nginx进行代理, 并对所踩的坑加以记录; 环境.工具.准备工作 服务器:阿里云64位CentOS 7.4.1708版本; ...
- 阿里云服务器安装Docker并部署nginx、jdk、redis、mysql
阿里云服务器安装Docker并部署nginx.jdk.redis.mysql 一.安装Docker 1.安装Docker的依赖库 yum install -y yum-utils device-map ...
- 阿里云CentOS7部署MySql8.0
本文主要介绍了阿里云CentOS7如何安装MySql8.0,并对所踩的坑加以记录; 环境.工具.准备工作 服务器:阿里云CentOS 7.4.1708版本; 客户端:Windows 10; SFTP客 ...
- 阿里云CentOS7.3服务器通过Docker安装Nginx
前言 小编环境: 阿里云CentOS7.3服务器 docker 下面分享一次小编在自己的阿里云CentOS7.3服务器上使用Docker来安装Nginx的一次全过程 温馨小提示: 如果只是希望单纯使用 ...
随机推荐
- 与运算(&)、或运算(|)、异或运算(^)、右移运算符(>>>)本质介绍
按位与运算符(&) 参加运算的两个数据,按二进制位进行"与"运算. 运算规则:0&0=0; 0&1=0; 1&0=0; 1&1= ...
- 【POJ 1845】Sumdiv——数论 质因数 + 分治 + 快速幂
(题面来自luogu) 题目描述 输入两个正整数a和b,求a^b的所有因子之和.结果太大,只要输出它对9901的余数. 输入格式 仅一行,为两个正整数a和b(0≤a,b≤50000000). 输出格式 ...
- Java基础教程——Set
Set·无序,不重复 HashSet 特点:没有重复数据,数据不按存入的顺序输出. HashSet由Hash表结构支持.不支持set的迭代顺序,不保证顺序. 但是Hash表结构查询速度很快. 创建集合 ...
- 网络篇:朋友面试之TCP/IP,回去等通知吧
前言 最近和一同学聊天,他想换工作,然后去面了一家大厂.当时,他在简历上写着精通TCP/IP,本着对TCP协议稍有了解,面试官也不会深问的想法,就写了精通二字.没想到,大意了 关注公众号,一起交流,微 ...
- python - os.sep用法
python是跨平台的.在Windows上,文件的路径分隔符是'\',在Linux上是'/'.为了让代码在不同的平台上都能运行,那么路径应该写'\'还是'/'呢?使用os.sep的话,就不用考虑这个了 ...
- Spring Cloud 学习 (三) Feign
新建 spring-cloud-eureka-feign-client Module pom <parent> <artifactId>spring-cloud-parent& ...
- NOIp2020游记
Day 1 考点还是在南航,第三次去已经没有什么新鲜感了,满脑子都是NOIp能不能考好.考前奶了一波这次必考最短路,于是在试机的时候打了一遍Dij和SPFA的板子,信心满满的上场了. 考试右后方是Ki ...
- 第3.8节 Python百分号占位符的字符串格式化方法
一. 概念 格式化字符串就是将一些变量转换为字符串并按一定格式输出字符串,包括指定字符的位置.对齐方式.空位补充方式等.Python提供了多种字符串格式设置方法.本节先介绍一种简 ...
- 第三十八章、PyQt输入部件:QKeySequenceEdit快捷键输入部件使用案例
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一.功能简介 Key Sequence Edit输 ...
- PyQt(Python+Qt)学习随笔:QDockWidget停靠窗toggleViewAction方法的作用
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 toggleViewAction方法返回一个动作对象,该动作对象通过点 ...