爬虫再探之mysql简单使用
在爬取数据量比较大时,用EXCEL存取就不太方便了,这里简单介绍一下python操作mysql数据库的一些操作。本人也是借助别人的博客学习的这些,但是找不到原来博客链接了,就把自己的笔记写在这里,这里感谢博文原创者。
import MySQLdb # 打开数据库连接
mypwd = input("请输入数据库密码:")
# 这里只是避免代码中直接出现自己的密码
# 下面中 “db” 是指定要使用的数据库,“charset” 是指定编码
db = MySQLdb.Connect(host="localhost", user="root", passwd=mypwd, db="test", use_unicode=True, charset="utf8")
# 获取操作游标
cursor = db.cursor() # 使用execute方法执行SQL语句
cursor.execute("SELECT VERSION()") # 使用fetchone 方法获取一条数据库
data = cursor.fetchone() print("Database's version is %s"%data)
#关闭数据库连接
db.close()
输出结果如下图。

上面算是一个基本流程吧。下面介绍一些具体的用法。
关于数据表的创建:
import MySQLdb #打开数据库链接
mypwd = input("请输入数据库密码:")
db = MySQLdb.Connect(host="localhost",user="root",passwd=mypwd,db="blog_test",use_unicode=True, charset="utf8") cursor = db.cursor() #如果数据已经存在,使用excute()方法删除表
cursor.execute("DROP TABLE IF EXISTS employee") #创建数据表SQL语句,这里和mysql数据库的语法是一样的。
sql = """CREATE TABLE employee(
first_name CHAR(20) NOT NULL,
last_name CHAR(20),
age INT,
sex CHAR(1),
income FLOAT )""" cursor.execute(sql) #关闭数据库连接
db.close()
可以看到blog_test数据库中已经创建了表employee.
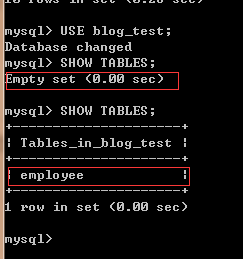
关于数据的插入
import MySQLdb
mypwd = input("请输入数据库密码:")
db = MySQLdb.Connect(host="localhost", user="root", passwd=mypwd,db="blog_test",use_unicode=True,charset="utf8")
cursor = db.cursor()
sql = """INSERT INTO employee(first_name,last_name,age,sex,income)\
VALUES('Mac','Mohan',20,"M",2000)"""
try:
cursor.execute(sql)
#提交到数据库执行,这里切记要commit提交事务,否则无法完成保存。
db.commit()
except:
#Rollback in case there is any error
db.rollback()
db.close()
数据库输出如下。
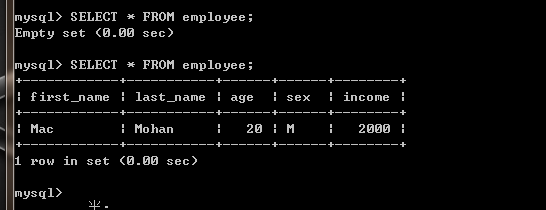
关于数据库的查询
import MySQLdb
mypwd = input("请输入数据库密码:")
db = MySQLdb.Connect(host="localhost", user="root", passwd=mypwd, db="blog_test", use_unicode=True, charset="utf8")
cursor = db.cursor()
sql = "SELECT * FROM employee"
try:
cursor.execute(sql)
results = cursor.fetchall()
print(results)
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
print("fname=%s,lname=%s,age=%d,sex=%s,income=%d"\
%(fname,lname,age, sex,income))
except:
print("Error, unable to fetch data")
db.close()
代码输出结果。

至此python操作数据库的一些基本操作算是说完了。。。
爬虫再探之mysql简单使用的更多相关文章
- 爬虫再探实战(三)———爬取动态加载页面——selenium
自学python爬虫也快半年了,在目前看来,我面临着三个待解决的爬虫技术方面的问题:动态加载,多线程并发抓取,模拟登陆.目前正在不断学习相关知识.下面简单写一下用selenium处理动态加载页面相关的 ...
- 爬虫再探实战(五)———爬取APP数据——超级课程表【四】——情感分析
仔细看的话,会发现之前的词频分析并没有什么卵用...文本分析真正的大哥是NLP,不过,这个坑太大,小白不大敢跳...不过还是忍不住在坑边上往下瞅瞅2333. 言归正传,今天刚了解到boson公司有py ...
- python3爬虫再探之豆瓣影评数据抓取
一个关于豆瓣影评的爬虫,涉及:模拟登陆,翻页抓取.直接上代码: import re import time import requests import xlsxwriter from bs4 imp ...
- 爬虫再探实战(四)———爬取动态加载页面——请求json
还是上次的那个网站,就是它.现在尝试用另一种办法——直接请求json文件,来获取要抓取的信息. 第一步,检查元素,看图如下: 过滤出JS文件,并找出包含要抓取信息的js文件,之后就是构造request ...
- python3爬虫再探之EXCEL
在爬取数据之后,数据的保存就成为一个新的问题,一般不太大的的数据存储到EXCEL就可以了.这里介绍一个python的第三方库——xlsxwriter. 这个库的安装就不介绍了,pip就可以,不用FQ. ...
- python3爬虫再探之EXCEL(续)
上篇介绍了xlsxwriter的用法,本来想写一下xlrd和xlwt的用法,看到这篇文章——http://blog.csdn.net/wangkai_123456/article/details/50 ...
- Node.js 网页爬虫再进阶,cheerio助力
任务还是读取博文标题. 读取app2.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // cheerio模块, ...
- 【再探backbone 02】集合-Collection
前言 昨天我们一起学习了backbone的model,我个人对backbone的熟悉程度提高了,但是也发现一个严重的问题!!! 我平时压根没有用到model这块的东西,事实上我只用到了view,所以昨 ...
- 再探jQuery
再探jQuery 前言:在使用jQuery的时候发现一些知识点记得并不牢固,因此希望通过总结知识点加深对jQuery的应用,也希望和各位博友共同分享. jQuery是一个JavaScript库,它极大 ...
随机推荐
- css--block formatting context
block formatting context(块级格式化上下文) 如何产生BFC:当一个HTML元素满足下面条件的任何一点,都可以产生Block Formatting Context: float ...
- C++继承与派生(原理归纳)
1. C++继承与java不同,java遵循单继承,但java的接口为其不足做了很好的弥补了. C++则是灵活的多,为多继承.即一个C++类可以同时继承N个类的属性. 2. 对于继承方式 : 有三 ...
- mysql的小知识点(关于数据库的导入导出 对于windows)
对于,一个存在的数据,我们该如何去打包成.sql属性的文件呢? 直接进行这两条语句: D:\Program Files\MySQL\mysql\bin>mysqldump -u root -p ...
- long型转日期型
//时分秒格式//不知为何,出来的时间有点差别 public class Test { public static void main(String[] args) throws Exception ...
- 【转】Session ID/session token 及和cookie区别
Session + Cookie 知识收集! cookie机制采用的是在客户端保持状态的方案.它是在用户端的会话状态的存贮机制,他需要用户打开客户端的cookie支持.cookie的作用就是为了解决 ...
- mybatis使用
mybatis网站:http://mybatis.github.io/spring/zh/ mybatis spring下载网址:https://github.com/mybatis/spring/r ...
- 使用SoundPool播放音效
针对应用程序经常需要播放密集.短促的音效,因为MediaPlayer存在如下缺点: 1.资源占用量较高.延迟时间较长. 2.不支持多个音效同时播放. SoundPool使用音效池的概念来管理多个短促的 ...
- 从问题域出发认识Hadoop生态系统
近些年来Hadoop生态系统发展迅猛,它本身包含的软件越来越多,同时带动了周边系统的繁荣发展.尤其是在分布式计算这一领域,系统繁多纷杂,时不时冒出一个系统,号称自己比MapReduce或者Hive高效 ...
- Hadoop Hello World
Hadoop单机环境配置OK后,需要找个例子测试一下Mapreduce功能.因此从Hadoop源代码中找到一个例子:WordCount.java,来验证. 编译过程如下: cd hadoop-exam ...
- 主机无法访问虚拟机上的elasticsearch服务器
问题: es在linux上搭建好,通过curl -XGET ip:port可以获得服务器信息展示,但是主机在浏览器上无法访问. 原因: 主机通过telnet访问linux的80端口,发现是不通的.可以 ...