4.K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
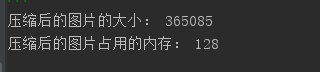
观察压缩图片的文件大小,占内存大小

压缩前图片:


压缩2后图片:

2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
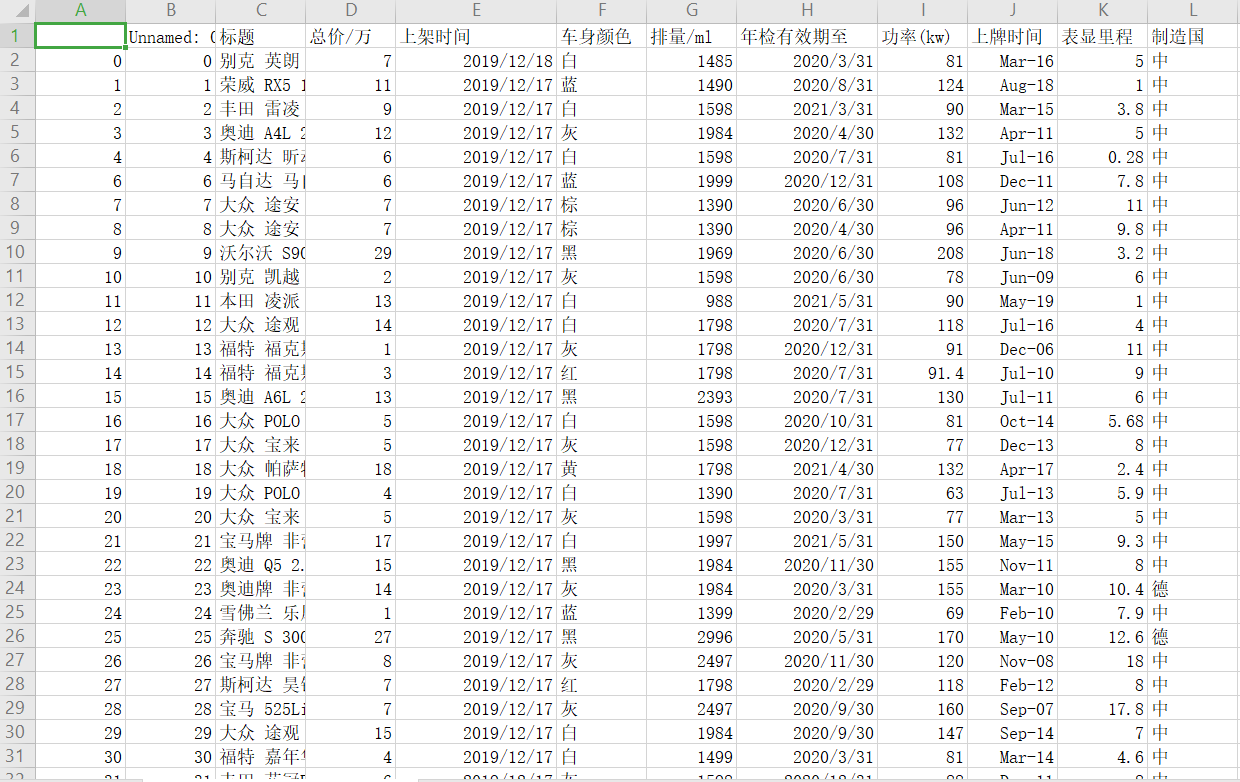
通过对汽车排量和功率来训练模型,然后按照总价进行划分,这样便于人们快速的知道汽车价格与功率的关系。
csv文件如图所示
源代码:

分类结果:
4.K均值算法--应用的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- iOS 内存分配与分区
RAM ROM RAM:运行内存,不能掉电存储. ROM:存储性内存,可以掉电存储,例如内存卡.Flash. 由于 RAM 类型不具备掉电存储能力(即一掉电数据消失),所以 app 程序一般存放于 R ...
- 用pymysql和Flask搭建后端,响应前端POST和GET请求
前言 这次作业不仅需要我建立一个数据库(详情请点击这里),还需要我基于这个数据库写后端接口(注册和登录)供前端访问,接收前端的POST和GET请求,并将登录.注册是否成功传给前端. 本文介绍如何用Fl ...
- MySQL出现的问题
错误展示 今天还是老样子照常启动MySQL WorkBench的时候出了错误,无法连接服务器 CMD登陆也不行 发现mysql的服务都没启动,于是点击启动,却又报这个错 cmd查看MySQL的日志,想 ...
- NKOJ3751 扫雷游戏
问题描述 有一款有趣的手机游戏.棋盘上有n颗地雷,玩家需要至少扫掉其中的k颗雷.每一步,玩家可以用手指在手机屏幕上划一条直线,该直线经过的地雷都会被扫除掉.问,最少需要划几次就能扫除k颗以上的地雷? ...
- P1343 地震逃生(最大流板题)
P1343 地震逃生 题目描述 汶川地震发生时,四川**中学正在上课,一看地震发生,老师们立刻带领x名学生逃跑,整个学校可以抽象地看成一个有向图,图中有n个点,m条边.1号点为教室,n号点为安全地带, ...
- SpringBoot整合Springfox-Swagger2
前言 不管Spring Boot整合还是SpringMVC整合Swagger都基本类似,重点就在于配置Swagger,它的精髓所在就在于配置. @ 目录 1.Swagger简介 2.整合前可能遇到的问 ...
- 如何优雅的将文件转换为字符串(环绕执行模式&行为参数化&函数式接口|Lambda表达式)
首先我们讲几个概念: 环绕执行模式: 简单的讲,就是对于OI,JDBC等类似资源,在用完之后需要关闭的,资源处理时常见的一个模式是打开一个资源,做一些处理,然后关闭资源,这个设置和清理阶段类似,并且会 ...
- 1043 Is It a Binary Search Tree (25分)(树的插入)
A Binary Search Tree (BST) is recursively defined as a binary tree which has the following propertie ...
- Elasticsearch 核心术语概念
Elasticsearch 相当于一个关系型数据库 索引 index 类型 type 文档 document 字段 fields 跟关系型数据库对比 Elasticsearch 相当于一个数据库 索引 ...
- Scratch 第2课淘气男孩儿
素材及视频下载 链接:https://pan.baidu.com/s/1qX0T2B_zczcLaCCpiRrsnA提取码:xfp8