python爬虫+正则表达式实例爬取豆瓣Top250的图片
- 直接上全部代码
新手上路代码风格可能不太好
import requests
import re
from fake_useragent import UserAgent #### 用来伪造爬头部信息
ua = UserAgent()
kv = {'user-agent': ua.random}
url = 'https://movie.douban.com/top250?start=0&filter='
index = 0 ####标记爬取图片的数量与命名
for i in range(0, 10):
sum_page = i*25
new_url = re.sub('start=\d+', 'start=%d'%sum_page, url, re.S)
r = requests.get(new_url, headers=kv)
r.encoding = 'utf-8'
text = r.text
#### 以上是一个分页爬取的操作 ####
pictures_part = re.findall('<div class="pic">(.*?)</div>', text, re.S)
for picture in pictures_part:
img = re.findall('src="(.*?)" class', picture, re.S)
pic = requests.get(img[0], headers=kv)
fp = open('imgs\\' + str(index) + '.jpg', 'wb') ####这里选用wb以二进制形式写入文件
fp.write(pic.content)
fp.close()
print('picture' + str(index) + ' has been dawnload')
index += 1
代码部分的解释
- 需要对爬虫的请求头部加以修改,引入fake_useragent库来进行轻微的伪造
- 利用了index在标记爬取图片数量的同时方便为爬取的图片命名
- 关于re库中的sub翻页,利用sub方法进行分页爬取
- 图片保存要以二进制形式写入
- 需要提前在和代码同目录下创建imgs文件夹
- 爬取时不无聊加了这个东西
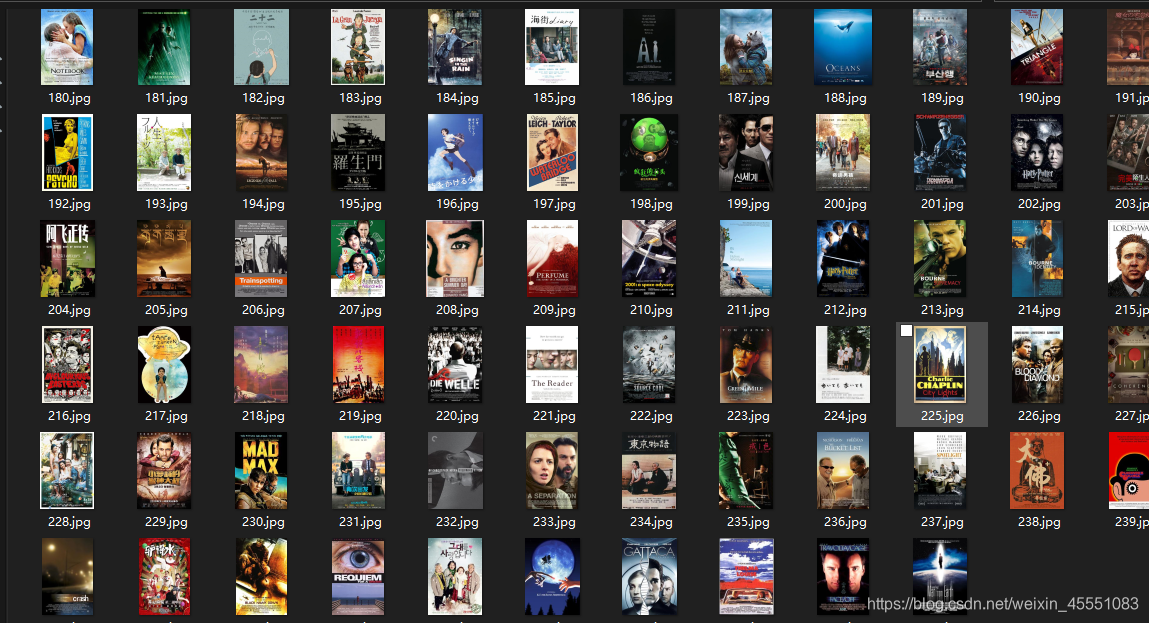
- 爬取的图片
python爬虫+正则表达式实例爬取豆瓣Top250的图片的更多相关文章
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 爬虫学习--MOOC爬取豆瓣top250
scrapy框架 scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片. scrapy E ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- Win10远程桌面发生身份验证错误,要求的函数不受支持
昨儿个使用远程桌面,意外发的发现连不上测试环境了.身边的同事也有连不上的.一开始以为是远程机器可能出了问题,但是而后排查确认是自个儿机器问题.原因在与机器前天晚上自动升级了系统补丁,也有部分网友反映了 ...
- MATLAB 图像打开保存
一.图片读取保存 (1)读取 clear all [filename,pathname]=uigetfile({'*.jpg';'*.bmp';'*.gif'},'选择图片'); if isequal ...
- .Net微服务实践(三):Ocelot配置路由和请求聚合
目录 配置 路由 基本配置 占位符 万能模板 优先级 查询参数 请求聚合 默认聚合 自定义聚合 最后 在上篇.Net微服务实践(二):Ocelot介绍和快速开始中我们介绍了Ocelot,创建了一个Oc ...
- linux 访问windows 共享文件
用到的方法是 CIFS (Common Internet File System)windows自己的网络文件系统 操作系统: Linux为 debian. Windows 为 windows 8 ...
- P1345 [USACO5.4]奶牛的电信(点拆边 + 网络最小割)
题目描述 农夫约翰的奶牛们喜欢通过电邮保持联系,于是她们建立了一个奶牛电脑网络,以便互相交流.这些机器用如下的方式发送电邮:如果存在一个由c台电脑组成的序列a1,a2,-,a©,且a1与a2相连,a2 ...
- centos8系统下docker安装jenkins
前提是已经安装好docker 1.下载jenkins(最新版本) docker pull jenkins/jenkins 2.创建用于存放jenkins的文件夹 mkdir /home/var/jen ...
- Nginx-高性能的反向代理服务器
Nginx Nginx作为一款反向代理服务器,现在大多数网站都有使用,自己在项目中几乎都有用到,自己的网站也使用到了它. 了解Nginx 上面图可以直观的看出Nginx的用处,可以将请求转发至Web服 ...
- Java第十六天,list接口
List接口 1.三大特点: ① 有序.② 有索引. ③ 允许存在重复元素. 注意: ① 利用list接口的索引执行操作时,要防止索引越界引起的程序错误. 2.基本使用: 针对List接口有索引的特点 ...
- Spring Cloud 系列之 Consul 注册中心(二)
本篇文章为系列文章,未读第一集的同学请猛戳这里:Spring Cloud 系列之 Consul 注册中心(一) 本篇文章讲解 Consul 集群环境的搭建. Consul 集群 上图是一个简单的 Co ...
- spark本地开发环境搭建及打包配置
在idea中新建工程 删除新项目的src,创建moudle 在父pom中添加spark和scala依赖,我们项目中用scala开发模型,建议scala,开发体验会更好(java.python也可以) ...