python爬虫+正则表达式实例爬取豆瓣Top250的图片
- 直接上全部代码
新手上路代码风格可能不太好
import requests
import re
from fake_useragent import UserAgent #### 用来伪造爬头部信息
ua = UserAgent()
kv = {'user-agent': ua.random}
url = 'https://movie.douban.com/top250?start=0&filter='
index = 0 ####标记爬取图片的数量与命名
for i in range(0, 10):
sum_page = i*25
new_url = re.sub('start=\d+', 'start=%d'%sum_page, url, re.S)
r = requests.get(new_url, headers=kv)
r.encoding = 'utf-8'
text = r.text
#### 以上是一个分页爬取的操作 ####
pictures_part = re.findall('<div class="pic">(.*?)</div>', text, re.S)
for picture in pictures_part:
img = re.findall('src="(.*?)" class', picture, re.S)
pic = requests.get(img[0], headers=kv)
fp = open('imgs\\' + str(index) + '.jpg', 'wb') ####这里选用wb以二进制形式写入文件
fp.write(pic.content)
fp.close()
print('picture' + str(index) + ' has been dawnload')
index += 1
代码部分的解释
- 需要对爬虫的请求头部加以修改,引入fake_useragent库来进行轻微的伪造
- 利用了index在标记爬取图片数量的同时方便为爬取的图片命名
- 关于re库中的sub翻页,利用sub方法进行分页爬取
- 图片保存要以二进制形式写入
- 需要提前在和代码同目录下创建imgs文件夹
- 爬取时不无聊加了这个东西
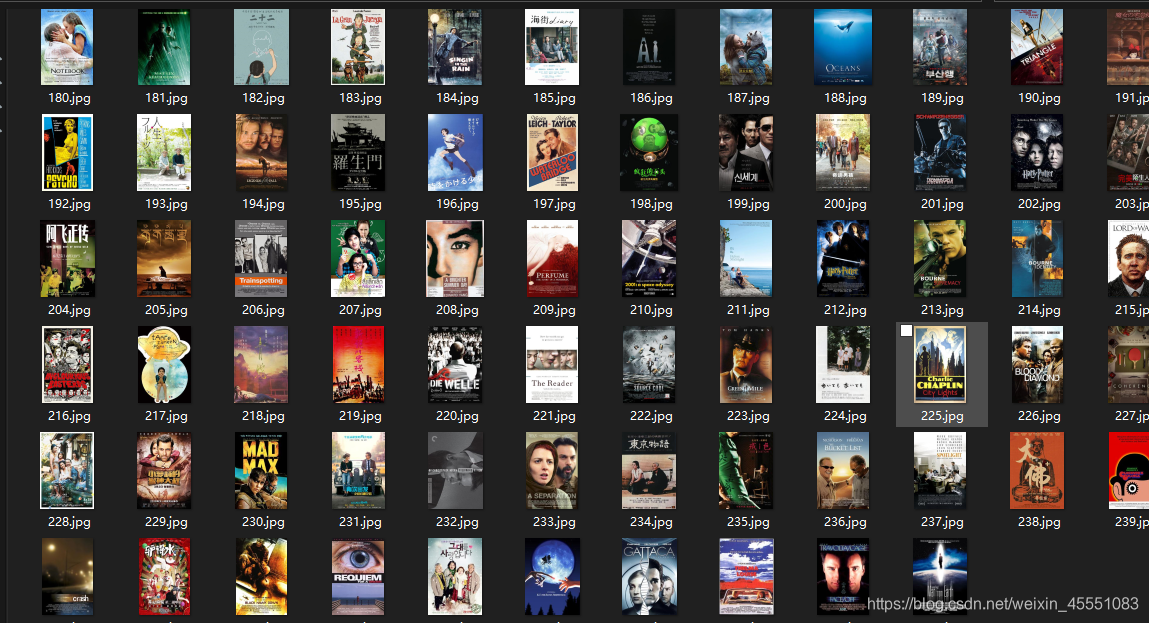
- 爬取的图片
python爬虫+正则表达式实例爬取豆瓣Top250的图片的更多相关文章
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 爬虫学习--MOOC爬取豆瓣top250
scrapy框架 scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片. scrapy E ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- iOS 内置图片瘦身
一.iOS 内置资源的集中方式 1.1 将图片存放在 bundle 这是一种很常见的方式,项目中各类文件分类放在各个 bundle 下,项目既整洁又能达到隔离资源的目的.采用 bundle 的加载方式 ...
- iOS App的启动过程
一.mach-O Executable 可执行文件 Dylib 动态库 Bundle 无法被连接的动态库,只能通过 dlopen() 加载 Image 指的是 Executable,Dylib 或者 ...
- [vijos1880]选课<树形dp>
题目链接:https://www.vijos.org/p/1180 这是一道树形dp的裸题,唯一的有意思的地方就是用到了多叉树转二叉树 然后本蒟蒻写这一道水题就是因为以前知道这个知识点但是没有怎么去实 ...
- java单元/集成测试中使用Testcontainers
1.Testcontainers介绍: Testcontainers是一个Java库,它支持JUnit测试,提供公共数据库.SeleniumWeb浏览器或任何可以在Docker容器中运行的轻量级.一次 ...
- (C#、JavaScript)面向对象的程序设计
面向对象(OOP)的理解 喜欢程序的朋友们,大家应该都听过一句话"万物皆对象",感觉老牛X了. 面向对象的程序设计,它是围绕真实世界来设计程序的. 面向对象三要素:封装.继承.多态 ...
- .net core 跨平台开发 微服务架构 基于Nginx反向代理 服务集群负载均衡
1.概述 反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客 ...
- ssl & ike/ipsec
SSL/TLS
- NS网络仿真,小白起步版,模拟仿真之间注意的事项
FTP是基于TCP的,所以FTP应用不可以绑定UDP发送代理 FTP和CBR属于应用流,他们用来绑定TCP和UDP发送代理 TCP用于发送代理时,接收代理为TCPSink,可以绑定FTP应用.CBR流 ...
- 22.3 Extends 构造方法的执行顺序
/** 1.有子父类继承关系的类中,创建父类对象未调用,执行父类无参构造* 2.有子父类继承关系的类中,创建子类对象未调用,执行顺序:默认先调用 父类无参构造---子类无参构造* 在子类的构造方法的第 ...
- POj3017 dp+单调队列优化
传送门 解题思路: 大力推公式:dp[i]=min(dp[k]+max(k+1,i)){k>=0&&k<i},max(j,i)记为max(a[h]){h>k& ...