scrapy 在爬取过程中抓取下载图片
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了
最好是保存,在使用其他方法下载
我这个是在 https://blog.csdn.net/qq_41781877/article/details/80631942 看到的,可以稍微改改来讲解
文章不想其他文章说的必须在items.py 中建立 image_urls和image_path ,可以直接无视
只需要yield返回的item中有你需要的图片下载链接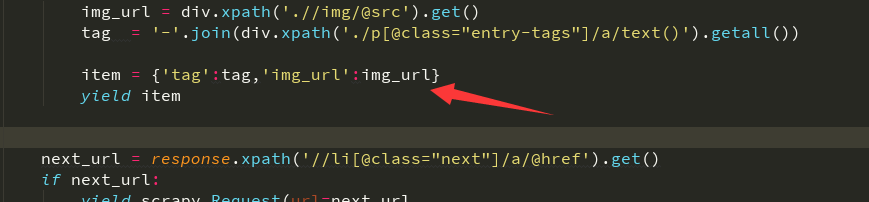
设置mid中的ua和ip,异常情况啥的,接下来是在pip中借用scrapy自带的图片下载类
ImagesPipeline 接下来基本是固定模板,创建一个类三个函数,都是固定的,除了方法可能根据需求改写 pip文件重写
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem import re
import scrapy class SaveImagePipeline(ImagesPipeline):
# 使用这个类,运行的第一个函数是这个get_media_requestsdef get_media_requests(self, item, info):# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
# yield Request(url=item['url'],meta={'name':item['title']}) # 这是我自己改的,根据yield给的tag和img_url切割得到一个图片名,传递给下一个函数
name = item['tag'] + item['img_url'].split('/')[-1]
yield scrapy.Request(url=item['img_url'], meta={'name':name}) # 第三个运行函数,判断有没有保存成功 ,我该写了没有保存成功者保存在本地文件中,以后进行抓取
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
with open('img_error.txt', 'a')as f:
error = str(item['tag']+' '+item['img_url'])
f.write(error)
f.write('\n')
raise DropItem('下载失败')
return item
# 第二个运行函数
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
# 我写的图片名
name = request.meta['name']
# 根据情况来选择,如果保存图片的名字成一个体系,那么可以使用这个
image_name = request.url.split('/')[-1]
# 清洗Windows系统的文件夹非法字符,避免无法创建目录
folder_strip = re.sub(r'[?\\*|“<>:/]', '', str(name))
# 分文件夹存储的关键:{0}对应着name;{1}对应着image_guid
# filename = u'{0}/{1}'.format(folder_strip, image_name) # 如果有体系,可以使用这个
filename = u'{0}'.format(folder_strip)
return filename
接下来在settings中设置文件放置在哪
IMAGES_STORE = ‘./meizi’ # meizi是放置图片的文件夹,随意设置名字
# 打开pip
ITEM_PIPELINES = {
'爬虫.pipelines.SaveImagePipeline': 300,
}
,如果图片有反爬,可以设置一个referer
我的如下 ,连同ua一起设置
import user_agent
class Girl13_UA_Middleware(object):
def process_request(self, request, spider):
request.headers['User_Agent'] = user_agent.generate_user_agent()
referer = request.url
if referer:
request.headers['Referer'] = referer
settings中将这个中间件mid设置为1
不过用这个还是很多下载出现错误404 ,虽然有一些下载下来了,五五开吧
要么一堆一次成功,要么一堆错误,有可能是ip访问频率问题吧,下次我再试试
github源码地址 https://github.com/z1421012325/girl13_spider
scrapy 在爬取过程中抓取下载图片的更多相关文章
- FETCH - 用游标从查询中抓取行
SYNOPSIS FETCH [ direction { FROM | IN } ] cursorname where direction can be empty or one of: NEXT P ...
- scrapy爬虫成长日记之将抓取内容写入mysql数据库
前面小试了一下scrapy抓取博客园的博客(您可在此查看scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据),但是前面抓取的数据时保存为json格式的文本文件中的.这很显然不满足我 ...
- windows中抓取hash小结(上)
我上篇随笔说到了内网中横向移动的几种姿势,横向移动的前提是获取了具有某些权限的用户的明文密码或hash,正愁不知道写点啥,那就来整理一下这个"前提"-----如何在windows系 ...
- java练习题(字符串类):显示4位验证码、输出年月日、从XML中抓取信息
1.显示4位验证码 注:大小写字母.数字混合 public static void main(String[] args) { String s="abcdefghijklmnopqrstu ...
- #在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat
#在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat子网和主机网络是同一网络,网络管理员要注 ...
- ListView与.FindControl()方法的简单练习 #2 -- ItemUpdting事件中抓取「修改后」的值
原文出處 http://www.dotblogs.com.tw/mis2000lab/archive/2013/06/24/listview_itemupdating_findcontrol_201 ...
- 【应用服务 App Service】App Service中抓取网络日志
问题描述 众所周知,Azure App Service是一种PaaS服务,也就是说,IaaS层面的所有内容都由平台维护,所以使用App Service的我们根本无法触碰到远行程序的虚拟机(VM), 所 ...
- windows中抓取hash小结(下)
书接上回,windows中抓取hash小结(上) 指路链接 https://www.cnblogs.com/lcxblogs/p/13957899.html 继续 0x03 从ntds.dit中抓取 ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
随机推荐
- LeetCode No.70,71,72
No.70 ClimbStairs 爬楼梯 题目 假设你正在爬楼梯.需要 n 阶你才能到达楼顶. 每次你可以爬 1 或 2 个台阶.你有多少种不同的方法可以爬到楼顶呢? 注意:给定 n 是一个正整数. ...
- 用go写爬虫服务并发请求,限制并发数
java写爬虫服务,思路是线程池,任务队列,限制并行线程数即可. go要用另一种设计思路,不能在线程层面限制,协程的异步请求,如果不作处理,并行发出所有网络请求,因网络请求数过多,会抛出异常 低版本的 ...
- highcharys去掉x轴,y轴轴线和刻度
x轴 xAxis: { lineWidth :,//去掉x轴线 tickWidth:,//去掉刻度 labels: { enabled: false },//去掉刻度数字 }, y轴 yAxis: { ...
- CAD安装未完成,某些产品无法安装的解决方法
CAD提示安装未完成,某些产品无法安装该怎样解决呢?,一些朋友在win7或者win10系统下安装CAD失败提示CAD安装未完成,某些产品无法安装,也有时候想重新安装CAD的时候会出现本电脑window ...
- Docker企业级镜像仓库harbor(vmware 中国团队)
第一步:安装docker和docker-compose 第二步:下载harbor-offline-installer-v1.3.0.tgz 第三步:上传到/opt,并解压 第四步:修改harbor.c ...
- js 实现排序算法 -- 选择排序(Selection Sort)
原文: 十大经典排序算法(动图演示) 选择排序(Selection Sort) 选择排序(Selection-sort)是一种简单直观的排序算法.它的工作原理:首先在未排序序列中找到最小(大)元素,存 ...
- 秒搭Kubernetes之使用Rancher
Rancher 在接触Docker和K8s的前阶段就耳闻目睹到Rancher,但是没有进一步接触过.直到将K8s搭建完成.才进一步了学习与实践Rancher. Rancher是简便易用的容器管理.其中 ...
- es6 转载
1.let命令 1)let和var的区别:let声明的变量只有所在的代码块有效. 2)没有变量的提升,一定要声明后使用.使用let命令声明变量之前,该变量都是不可用的.形成“暂时性死区”. 3)typ ...
- python基础函数、方法
python的函数和方法,通过def 定义: 函数的特性: 减少重复代码 使程序变的可扩展 使程序变得易维护 函数和方法的区别:函数有返回值.方法没有 语法定义: def sayhi():#函数名 p ...
- JAVA SE Lesson 1
1. 类是一种抽象的概念,对象是类的一种具体表示形式,是具体的概念.先有类,然后由类来生成对象(Object).对象又叫做实例(Instance).2. 类由两大部分构成:属性以及方法.属性一般用 ...