【HBase】通过Bulkload批量加载数据到Hbase表中
需求
将hdfs上面的这个路径 /hbase/input/user.txt 的数据文件,转换成HFile格式,然后load到myuser2表里面去
先清空一下myuser2表的数据 —— truncate 'myuser2'
步骤
一、开发MapReduce
定义一个main方法类——BulkloadMain
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class BulkloadMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
//获取Job对象
Job job = Job.getInstance(super.getConf(), "Bulkload");
//获取数据输入路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job,new Path("hdfs://node01:8020/hbase/input"));
//自定义Map逻辑
job.setMapperClass(BulkloadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
Connection connection = ConnectionFactory.createConnection(super.getConf());
Table table = connection.getTable(TableName.valueOf("myuser2"));
//通过 configureIncrementalLoad 设置增量添加
HFileOutputFormat2.configureIncrementalLoad(job,table,connection.getRegionLocator(TableName.valueOf("myuser2")));
//使用 HFileOutputFormat2 设置输出类型为HFile
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.setOutputPath(job,new Path("hdfs://node01:8020/hbase/output2"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
int run = ToolRunner.run(configuration, new BulkloadMain(), args);
System.exit(run);
}
}
自定义Map逻辑,定义一个Mapper类——BulkloadMapper
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class BulkloadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//以\t为分隔符分割拿到的v1
String[] split = value.toString().split("\t");
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable();
immutableBytesWritable.set(split[0].getBytes());
//创建Put对象
Put put = new Put(split[0].getBytes());
//往put中插入行数据
put.addColumn("f1".getBytes(),"name".getBytes(),split[1].getBytes());
put.addColumn("f1".getBytes(),"age".getBytes(), split[2].getBytes());
//转换为k2,v2输出
context.write(immutableBytesWritable,put);
}
}
二、打成Jar包放到linux执行
yarn jar day12_HBaseANDMapReduce-1.0-SNAPSHOT.jar cn.itcast.mr.demo4.BulkloadMain
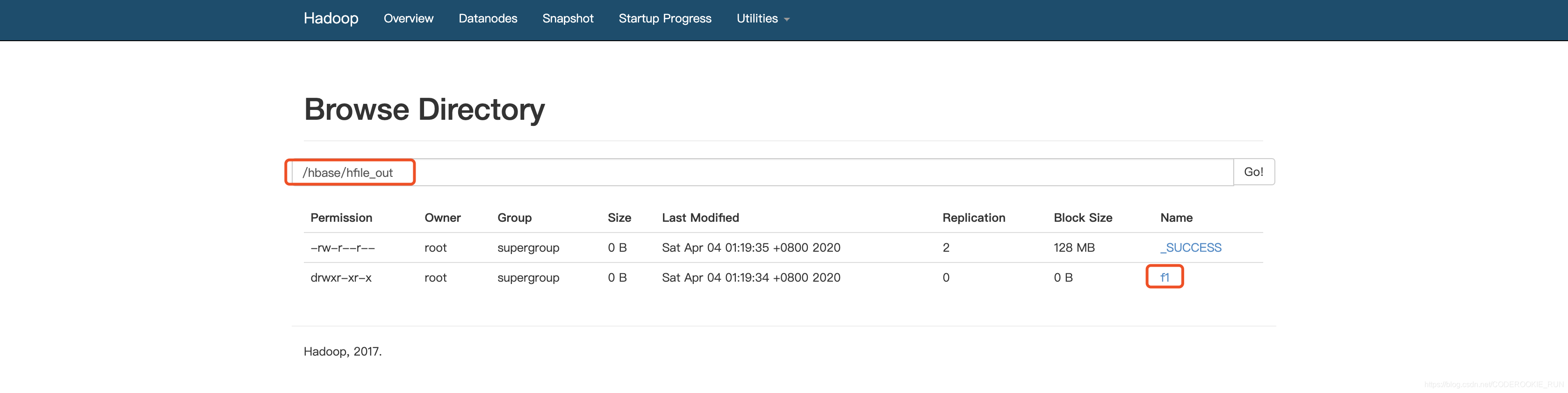
在HDFS可以看见成功输出的Hfile文件
三、有两种办法将HFile文件加载到HBase表中
开发代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
public class LoadData {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "node01,node02,node03");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
Table table = connection.getTable(TableName.valueOf("myuser2"));
LoadIncrementalHFiles load = new LoadIncrementalHFiles(configuration);
load.doBulkLoad(new Path("hdfs://node01:8020/hbase/hfile_out"), admin,table,connection.getRegionLocator(TableName.valueOf("myuser2")));
}
}
Hadoop命令运行
yarn jar /export/servers/hbase-1.2.0-cdh5.14.0/lib/hbase-server-1.2.0-cdh5.14.0.jar completebulkload /hbase/hfile_out myuser2
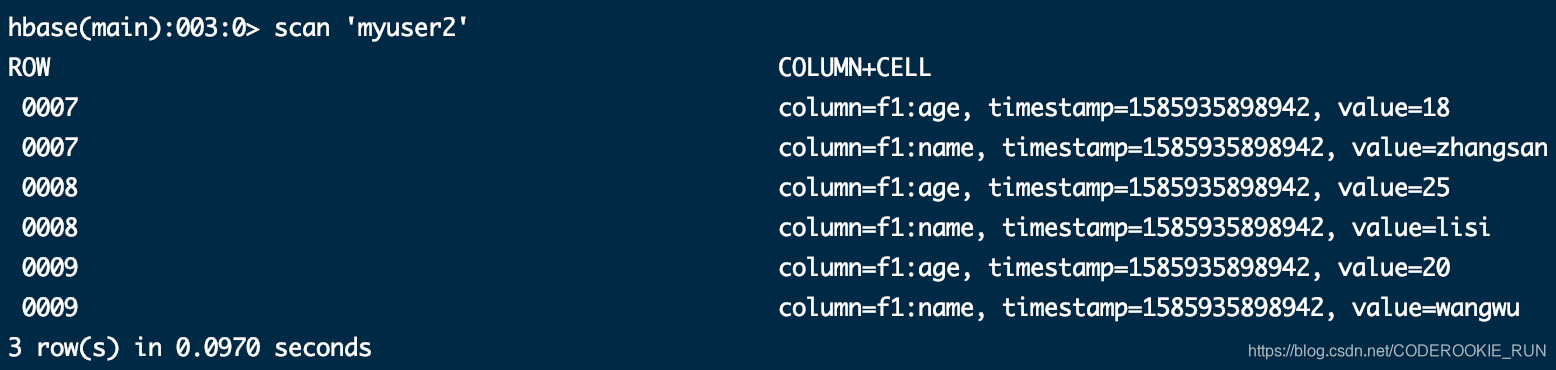
两种方法均能成功
【HBase】通过Bulkload批量加载数据到Hbase表中的更多相关文章
- Android学习笔记_37_ListView批量加载数据和页脚设置
1.在activity_main.xml布局文件中加入ListView控件: <RelativeLayout xmlns:android="http://schemas.android ...
- android 批量加载数据
public class MainActivity extends Activity { private ListView listView; private List<String> d ...
- 使用Spark加载数据到SQL Server列存储表
原文地址https://devblogs.microsoft.com/azure-sql/partitioning-on-spark-fast-loading-clustered-columnstor ...
- 第2节 hive基本操作:11、hive当中的分桶表以及修改表删除表数据加载数据导出等
分桶表 将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去 开启hive的桶表功能 set hive.enforce.bucketing= ...
- 巧力避免ViewPager的预加载数据,Tablayout+Fragment+viewPager
问题描述 最近在进行一个项目的开发,其中使用到了Tablayout+Fragment+viewPager来搭建一个基本的框架,从而出现了设置数据适配器的时候,item的位置错乱问题.我打印log日志的 ...
- SQLAlchemy加载数据到数据库
SQLAlchemy加载数据到数据库 最近在研究基于知识图谱的问答系统,想要参考网上分享的关于NLPCC 2016 KBQA任务的经验帖,自己实现一个原型.不少博客都有提到,nlpcc-kbqa训练数 ...
- 时间序列数据库——索引用ES、聚合分析时加载数据用什么?docvalues的列存储貌似更优优势一些
加载 如何利用索引和主存储,是一种两难的选择. 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储. 选择使用索引,然后用找到的row id去主存储加载数据 ...
- Caffeine批量加载浅析
最近项目中的本地缓存,看是从Guava改成了Caffeine,据说是性能更好,既然性能更好的话,那么就用起来吧.不过在使用过程中,发现了单个load和批量loadall方面的一些小设置,记录一下. 一 ...
- Bootstrap-Select 动态加载数据的小记
关于前端框架系列的可以参考我我刚学Bootstrap时候写的LoT.UI http://www.cnblogs.com/dunitian/p/4822808.html#lotui bootstrap- ...
随机推荐
- python高级特性之封包与解包
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:kwsy PS:如有需要Python学习资料的小伙伴可以加点击下方链接 ...
- L12 Transformer
Transformer 在之前的章节中,我们已经介绍了主流的神经网络架构如卷积神经网络(CNNs)和循环神经网络(RNNs).让我们进行一些回顾: CNNs 易于并行化,却不适合捕捉变长序列内的依赖关 ...
- 一行配置美化 nginx 目录 autoindex.html
demo
- [leetcode] 并查集(Ⅰ)
预备知识 并查集 (Union Set) 一种常见的应用是计算一个图中连通分量的个数.比如: a e / \ | b c f | | d g 上图的连通分量的个数为 2 . 并查集的主要思想是在每个连 ...
- union 的概念及在嵌入式编程中的应用
union 概念 union 在中文的叫法中又被称为共用体,联合或者联合体,它定义的方式与 struct 是相同的,但是意义却与 struct 完全不同,下面是 union 的定义格式: union ...
- JDK 14的新特性:更加好用的NullPointerExceptions
JDK 14的新特性:更加好用的NullPointerExceptions 让99%的java程序员都头痛的异常就是NullPointerExceptions了.NullPointerExceptio ...
- java在指定区间内生成随机数
Random对象生成随机数 首先需要导入包含Random的包 import java.util.Random; nextInt(int)方法将生成0~参数之间的随机整数但不包括参数. 例如生成0~99 ...
- 【Linux网络基础】上网原理流程
1. 局域网用户上网原理 上网过程说明: 确保物理设备和线路架构准备完毕,并且线路通讯状态良好 终端设备需要获取或配置上局域网(私有地址)地址,作为局域网网络标识 当终端设备想上网时,首先确认访问的地 ...
- 定了,这个vue.js开源项目,面试时,一定会考问
因为现在的网店,都是用的商城系统, 而实体店都是入座后,扫码打开网上商城进行选购(餐饮,超市等),所以,vue.js迅速开发网上购物商城系统成为了香饽饽, 本人开源2020年4月开发的购物商城系统, ...
- 更改 vsftpd 的端口号
2019独角兽企业重金招聘Python工程师标准>>> vsftpd启动后,默认的ftp端口是21,现在我想把ftp端口改成 801 ,修改后能保证用户上传下载不受影响 1.编辑 / ...