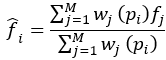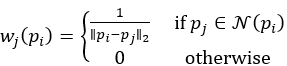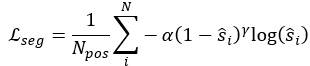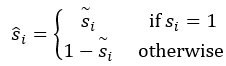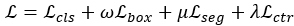作者:蒋天园
Date:2020-04-16
来自CVPR2020的研究工作,也是仅仅使用Lidar数据进行3D检测的文章,CVPR2020接收的几篇文章中,采用LiDar作为网络结构输入的已经已经多于采用图像和lidar的结合,从一方面讲,lidar数据由于包含了现实场景中的几何结构而比双目信息包含更加精确的信息。同时受到的外界条件的影响也相应的越小。
文章链接:http://www4.comp.polyu.edu.hk/~cslzhang/paper/SA-SSD.pdf
代码链接:https://github.com/skyhehe123/SA-SSD
核心创新与主要内容
本文核心创新是想要将二阶段方法独有精细回归运用在一阶段的的检测方法上,为此作者采用了SECOND作为backbone,添加了两项附加任务,使得backbone具有structureaware的能力,定位更加准确;此外在一阶段中存在预测框和clsmaps之间不匹配的问题,本文也设计了一种策略解决这个问题。
1.3D检测中的onestage的检测方法都是通过卷积逐步缩小fea-map,没有上采样过程,这样会导致空间信息的丢失,无法用几何结构,对定位精度降低比较明显.
2.本文中心在通过深度挖掘三维物体的几何信息来提高定位精度。
以前的研究工作都是point to tensor的,而这里作者为了将卷积得到的信息用点结构表达,设计了一个auxiliary network,用于将Tensor信息转化到point上,因为piont实际上是还保留着原始的几何结构,这里作者可能是想将语义信息和细节信息融合。
3.这个辅助网络和backbone是一同训练的,引导backbone感知object structure
这一点和pointnet的两个辅助网络也挺像的,pointnet中的作用是使得网络可以感知问题的刚体变换。
4.辅助网络在推理阶段不参与运算,可以和主干网络分离,因此不会增加额外运算量
5.作者提出第二个问题是:一阶段的方法会在cls置信度和对应的预测框之间存在不一致的问题,所以本文提出了一个方法将置信度和bbox对齐。
Introduction
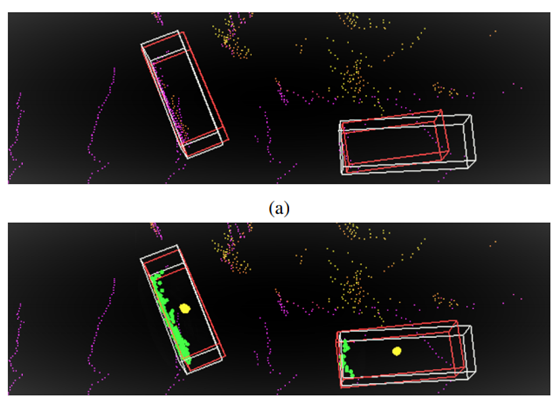
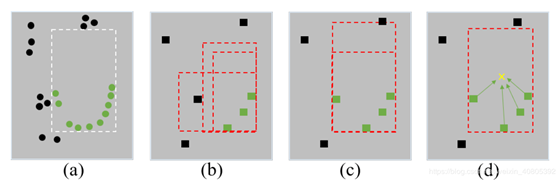
这是作者提出的解决的第一个问题,如下图的对比中,(a)图是SECOND检测出的bbox,可以看出在object 点比较少的时候虽然也可以检出,但是对应的框的定位效果就不如本文提出的(b)的实验效果。
这一问题仅仅在One-stage的检测方法中会出现,因为two-stage第一步提出proposals后,在第二步会精细的在fea map上进行精细的回归,所以在19年ICCV的文章主要的研究点则是 onestage的方法转two-stage,精度也是有很大的提升。但是不可避免的在时间消耗上增大,这也从侧面验证了利用细粒度信息对精细回归的重要性。
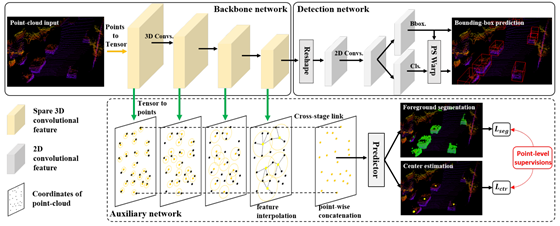
所以本文作者的核心第一个问题是将二阶段使用的精细回归的细粒度信息如何附加到一阶段信息中,也就是作者提出的如下的网络结构,可以看的出来作者的核心创新点在下面的auxiliary的网络结构中。该结构可以监督上层的tensor表达的学习到点云中的几何结构信息。
1.将feature 转化到point的上,得到point-wise的特征信息
2.前景分割,目的是使得该网络结构对边界敏感,同时point-wise的特征估计object 中心加大内点感知能力。
feature map warping method
这就是作者提出的第二个问题,在one-stage的方法中,由于没有精细的回归会导致最后分类时得到的分数不太好,这会影响后续的NMS工作,因此作者设计了一个Align的方法,使得输出的分类置信度更具有可信度。
前人研究
一阶段的方法从Voxelnet开始后续很多工作都是一阶段的,SECOND ,PointPillars都是经典的一阶段方法。
两阶段的方法可以从point-based和voxel-based的方法上进行分说。除去CVPR20的3D-SSD这篇文章,之前的基本所有的Pointbased的方法都是多阶段的,其中比较出名的工作有CVPR18的F-pointnet,这篇工作是先通过二维检测得到检出的目标,再通过视锥投影到三维点云中,最后采用pointnet的变体结构进行定位和分类,实际上算作是三阶段的方法;后续的IROS19的F-ConvNet在F-pointnet的基础上将投影出来的视锥中的点云根据距离划分为多个序列。在同年的CVPR19上Point-Rcnn也是point-based的目标检测方法,不过是Lidar-only的方法,以每一个点为anchor预测和回归目标框,计算消耗比较大。针对Voxel-based的方法,在19年上后半段有挺多著名的工作,Fast-Point-RCNN,STD,PartA^2等等工作,也就是在前人的单阶段的基础上加入了refine的网络模块,进一步优化了定位。除此之外,融合图像信息和Lidar信息在19年及之前是很流行的,不过最新的方法几乎都是LIDAR-only的方法了,比较近的有AAAI20的PIRCNN,这一篇也是一个两阶段的方法,通过lidar预测出的框和图像特征融合做二阶段的回归。
1.这个子话题的主要思想是:通过附加任务使得backbone具有某种特征倾向的能力。作者在本文中添加了两个point-wise prediction tasks目的是提高3D检测的结果,如上图展示的那样,增加了前景分割和中心预测两个任务;但是本文的附加任务在推理阶段是可以被舍弃的,不增加额外的计算量。
2.Point-wise feature representation
如上图所示的那样,本文中需要把Backbone的tensor特征转化到point为载体上,表示坐标为 的点的特征为,由于在最开始原始点云转化为tensor输入时会丢失一些局部点(后文讲到),所以从tensor-到point时是一对多的特征,如果采用retrail的方式,那么相邻点的特征都是一样的,作者这里采用的是FP层,即是插值的方式,表示为经过FP层的特征信息,采用以下公式得到插值后的特征:
从上式插值的方式可以看出,采用距离作为权重进行加权。这里的设置为0.05的球体,这也和后面的point到tensor的设置对应,采用的是(0.05,0.05,0.1)的尺度划分voxel。最后再将多层voxel到point的特征concat一起。
object中心预测loss:如上式采用的是smooth-l1损失函数,对残差进行回归。
网络结构
以前的onestage的方法采用对整个场景进行volize化,但是这个过程是一个很消耗时间的,作者为了简化这个过程,采用了如下的方法:
输入的点云可以表示为
%3Ai%3D1%2C%E2%80%A6N%7D)
,为了量化点云,作者假设点云场景的单位长度为

,所以量化后的点云输入为:
)
这里表示的是向下取整。并且如果遇到不同的点采用了同样的索引,那么更新为最新的输入就可以了,在实验中作者设置的尺度大小为d=[0.05m,0.05m,0.1m]
和SECOND1.5后我们知道,SECOND1.5是采用的尺度信息也是这么大,不过SECOND架构为了实现更多的框架,设置的在每一个voxel中最大的点个数只有5,就类似本文中作者设置1一个意思。在SECOND1.5中对每一个voxel实际上也没有沿用VoxelNet中的那样采用MLP进行特征提取,而是直接取平均值;所以本文作者这样做实际上效果是一样的,只是预处理会更快。
本文作者的backobne实际上和SECONDE的一脉相承,不过本文作者在to point的表示上的时候采用的multi-level特征连接,采用稀疏卷积到BEV feamap,最后也采用标准的二维卷积预测最后的anchor,本文采用的是ancor_based head。
也就是在前文中笔者提到的两个问题,第一点,目前的onestage的方法一直下采样会导致空间信息的模糊和丢失,会导致后面的detection过程的定位不准,这里如下图中的含义,其中a表示最原始的bbox,背景点和前景点;通过多次卷积stride过程会导致如图(b)所示的问题,有些比较偏远的前景点特征融合为了背景信息。作者针对第一个问题提出了辅助网络,将从Muti-level的voxel特征融合在监督训练,使得backbaone的网络结构具有structureaware的能力。下图中的图©表示的是在添加了前景分割的附加任务,但是不添加中心点预测的检测结果,进一步的图(d)表示添加上述两项附加任务后的检测结果。
这里是为了解决作者所提出的第二个问题,the misalignment between the predictedbounding boxes and corresponding confidence maps。这也是one stage 都会存在的一个问题。具体操作如下:
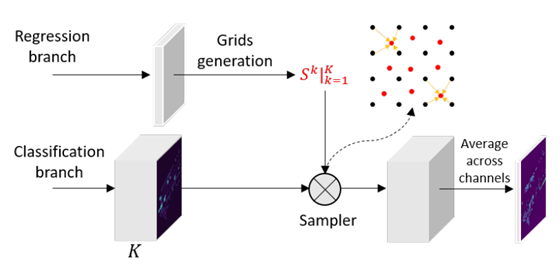
(1)首先修改分类的最后一层用于生成K个 part-sensitive 的 cls maps,记做

,这里边的每一块包含着object的部分信息,例如K=4时的信息可以理解为{upper-left, upper-right, bottom-left,bottom-right},同时对Bbox的每一个fea map 都划分为K个子窗口,并且选择每个窗口的中心为采样点。这样作者就得到了K个采样的格点记做

,分别对用这上述的clsmap。
(2)步骤(1)中的得到的cls map和格点一同送入PSWarp结构,如下图,该sampler的输出是格点对应的cls map的特征
(3)最终的输出是多个采样后的cls maps的平均值
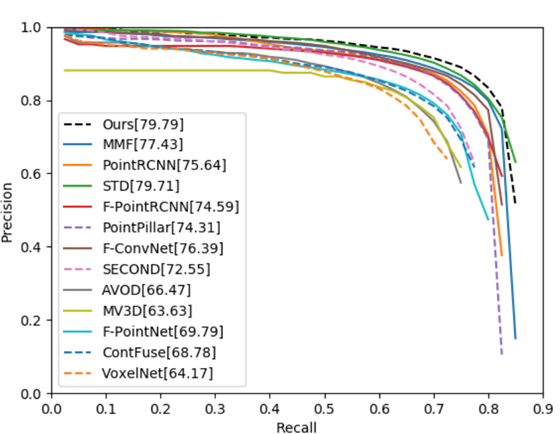
损失函数
本文采用的是anchor -based的方法,其损失函数和以往的voxel-based的方法一致,只是多了上述提到的附加任务的两项损失。如下:
实验
笔者只提一下本文使用的数据增广方案,也是采用的先将所有object收集起来再随机变换后放置在训练集中,都是源自SECOND的方法。
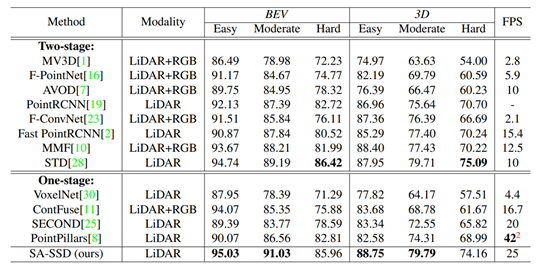
附加任务参数影响
上文中的总损失函数的权衡参数对整个实验的影响如下:
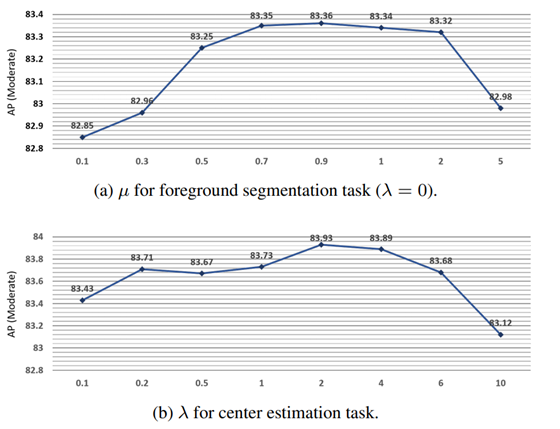
precision-recall
在KIITI的test数据集上,作者画出了对应的精度-召回率曲线(在KITTI官网上有)
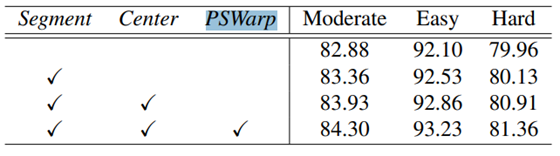
消融实验
作者本文中主要有两点创新,分别是附加任务(前景分割和中心预测),cls和box匹配的PSWarp,作者做了如下的实验:
- 阿里云在云栖大会发布RPA最新3.4版本,将与达摩院联合探索人工智能领域
9月26日,在2019年杭州云栖大会上,阿里云发布了RPA最新V3.4版本,全新升级了增加诸如录屏审计.JAVA应用录制能力.达摩院OCR内置组件.语法检查与智能提示能力增强等功能. RPA全名称Ro ...
- TOP100summit 2017:投资千亿成立达摩院,揭秘阿里在人工智能领域的探索
今天上午,阿里巴巴云栖大会在杭州开幕,第一条重磅消息是阿里首席技术官张建锋宣布成立达摩院,在全球各地建立实验室,3年内投入千亿在全球建立实验室.和高校建立研究所.建立全球研究中心等事务. 该院由全球实 ...
- 邀您共赴数据库学术顶会ICDE 2019——阿里云专场 零距离接触达摩院数据库“最强大脑”
摘要: 当学术大家遇到技术大拿,会碰撞出怎样的火花?为进一步加深产学研学术交流,阿里云将于ICDE 2019大会期间(4月9日)举办以“云时代的数据库”为主题的技术专场(Workshop) 作为全球数 ...
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- android大牛高焕堂最新力作-android架构师之路
android大牛高焕堂 个人介绍: Android专家顾问,台湾Android论坛主席,现任亚太地区Android技术大会主席,台湾Android领域框架开发联盟总架构师.发表100多篇Androi ...
- 阿里云CentOS 7系统挂载SSD云盘的教程_Linux
一.查看SSD云盘 sudo fdisk -l Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors Units = sectors ...
- thinkphp使用阿里云OSS最新SDK,文件部署
这文章是建立在你已经注册号阿里云的OSS,和创建好Bucket前提下: 其实阿里云的帮助与文档写的很详细,这里只说一下源码方式 1.phpsdk下载地址(摘自阿里云OSS的帮助与文档)(也有我自己下载 ...
- 2015年度精品 最新力作32位和64位xp,win7,win8,win10系统下载(电脑城专用版)
一.系统主要特点 1.安装维护方便快速 - 全自动无人值守安装,采用万能GHOST技术,安装系统过程只需3-5分钟,适 合新旧各种机型. - 集成常见硬件驱动,智能识别+预解压技术,绝大多数硬件可以快 ...
- 加盟阿里!贾扬清被曝从Facebook离职,任阿里硅谷研究院VP
3 月 2 日傍晚,知乎上爆出一则 AI 人事变动大消息——Caffe 作者贾扬清将从 Facebook 离职. 短短数小时,就有近 10 万人浏览这个问题.不仅如此,据 AI 前线爆料,贾扬清离开 ...
随机推荐
- java 泛型简介(转载)
原文出处: absfree 1. Why ——引入泛型机制的原因 假如我们想要实现一个String数组,并且要求它可以动态改变大小,这时我们都会想到用ArrayList来聚合String对象.然而,过 ...
- search(3)- elastic4s-QueryDSL
elastic4s是elasticsearch一个第三方开发的scala语言终端工具库(Elastic4s is a concise, idiomatic, reactive, type safe S ...
- Spring Cloud 系列之 Netflix Hystrix 服务监控
Actuator Hystrix 除了可以实现服务容错之外,还提供了近乎实时的监控功能,将服务执行结果和运行指标,请求数量成功数量等等这些状态通过 Actuator 进行收集,然后访问 /actuat ...
- 文本编辑器之kindeditor
摘要:最近在自己学习搭建网站的时候,突然要搭建网站的时候发现了一个好东西,那就是kindeditor这个文本编辑器,这个编辑器简单好用,而且很小,并且是开源的. 文本编辑器介绍 KindEditor ...
- JDK下载、安装、卸载
学习java的朋友,第一课就是安装JDK,如果你连他都不会安装,那就非常尴尬,如果面试的时候如果问到这个问题,就Game over了,下面来看看怎么弄吧! 了解JDK JDK的全称是JavaSE De ...
- npm git 常用命令行 记录
1. 推出node命令行: 两次ctrl+C或者一次ctrl+D 退出终端:exit; 2.npm 常用 npm install <name> 安装包 npm install &l ...
- 强化学习之六:Deep Q-Network and Beyond
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- ——JAVA基础部分
1. 我们能不能声明main()方法为非静态?√ 不能,main()方法必须声明为静态的,这样JVM才可以调用main()方法而无需实例化它的类. 如果从main()方法去掉“static”这个声明, ...
- 第 k 小的数
一.寻找两个有序数组的中位数 1.1 问题描述 给定两个大小为 m 和 n 的不同时为空的有序数组 nums1 和 nums2.找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m ...
- NSArray、NSDictionary
一.NSDictionary 1.1 使用自定义对象 key Dictionaries manage pairs of keys and values. A key-value pair within ...