Spark文档阅读之一:Spark Overview
1. spark的几种执行方式
1)交互式shell:bin/spark-shell
2)python: bin/pyspark & bin/spark-submit xx.py
3)R:bin/sparkR & bin/spark-submit xx.R
2. 任务的提交
bin/spark-submit \
--class <main-class> \ # 任务入口
--master <master-url> \ # 支持多种cluster manager
--deploy-mode <deploy-mode> \ # cluster / client,默认为client
--conf <key>=<value> \
... # other options,如--supervise(非0退出立即重启), --verbose(打印debug信息), --jars xx.jar(上传更多的依赖,逗号分隔,不支持目录展开)
<application-jar> \ # main-class来自这个jar包,必须是所有节点都可见的路径,hdfs://或file://
[application-arguments] # 入口函数的参数 bin/spark-submit \
--master <master-url> \
<application-python> \
[application-arguments]
3. cluster模式
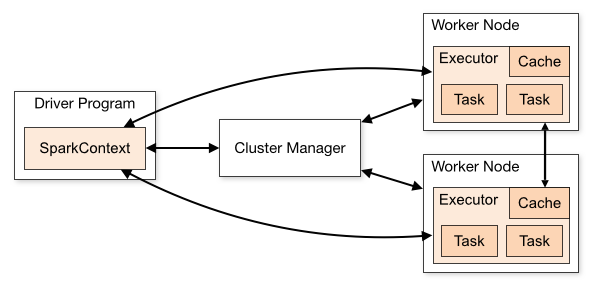
术语表
|
术语
|
含义
|
|
Application
|
任务,用户的spark程序,包含位于集群的一个driver和多个executors
|
|
Application jar
|
一个包含用户spark任务和依赖的jar包,不应包含hadoop或spark库
|
|
Driver program
|
任务main()函数和SparkContext所在的进程
|
|
Cluster manager
|
获取集群资源的外部服务
|
|
Deploy mode
|
用来区分driver进程在cluster还是client(即非cluster机器)上执行
|
|
Worker node
|
任何可以跑任务代码的节点
|
|
Executor
|
在worker node上载入并运行了用户任务的一个进程,它执行了tasks并且在内存或存储中保存数据,每个application独占它自己的executors
|
|
Task
|
一组被发送到一个executor的工作
|
|
Job
|
一个多tasks的并行计算单元,对应一个spark操作(例如save, collect)
|
|
Stage
|
每个job可以划分成的更小的tasks集合,类似MapReduce中的map/reduce,stages相互依赖
|


Spark文档阅读之一:Spark Overview的更多相关文章
- Spark文档阅读之二:Programming Guides - Quick Start
Quick Start: https://spark.apache.org/docs/latest/quick-start.html 在Spark 2.0之前,Spark的编程接口为RDD (Resi ...
- 转:苹果Xcode帮助文档阅读指南
一直想写这么一个东西,长期以来我发现很多初学者的问题在于不掌握学习的方法,所以,Xcode那么好的SDK文档摆在那里,对他们也起不到什么太大的作用.从论坛.微博等等地方看到的初学者提出的问题,也暴露出 ...
- Django文档阅读-Day1
Django文档阅读-Day1 Django at a glance Design your model from djano.db import models #数据库操作API位置 class R ...
- Django文档阅读-Day3
Django文档阅读-Day3 Writing your first Django app, part 3 Overview A view is a "type" of Web p ...
- Node.js的下载、安装、配置、Hello World、文档阅读
Node.js的下载.安装.配置.Hello World.文档阅读
- 我的Cocos Creator成长之路1环境搭建以及基本的文档阅读
本人原来一直是做cocos-js和cocos-lua的,应公司发展需要,现转型为creator.会在自己的博客上记录自己的成长之路. 1.文档阅读:(cocos的官方文档) http://docs.c ...
- Keras 文档阅读笔记(不定期更新)
目录 Keras 文档阅读笔记(不定期更新) 模型 Sequential 模型方法 Model 类(函数式 API) 方法 层 关于 Keras 网络层 核心层 卷积层 池化层 循环层 融合层 高级激 ...
- Django文档阅读-Day2
Django文档阅读 - Day2 Writing your first Django app, part 1 You can tell Django is installed and which v ...
- Spark Streaming + Flume整合官网文档阅读及运行示例
1,基于Flume的Push模式(Flume-style Push-based Approach) Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Stre ...
随机推荐
- java导入web项目httpservlet报错
于是开始了,调错之路. 解决方法:鼠标右击项目工程——>Build Path——>点击comfigure Build Path进入----->选择java Bulid Path--- ...
- 如何为Form表单的多个提交按钮指定不同的Action地址?
这是我很久以前看到的一个技巧,但我忘记在哪里了,当时遇到这样的需求,做了笔记,现在整理成文章分享出来,因为我感觉这个小技巧还是挺有用的,这种应用场景也算比较常见,比如一个表单有"保存&quo ...
- 关于mantisBT2.22安装插件Inline column configuration 2.0.0时提示缺少依赖jQuery UI Library 1.8
1.首先直接下载最新的那个1.12即可 https://github.com/mantisbt-plugins/jQuery-UI/releases 2.上传到mantis的插件目录下:……manti ...
- 读Pyqt4简介,带你入门Pyqt4 _001
PyQt是用来创建GUI应用程序的工具包,它把Python和成功的Qt绑定在一起,Qt库是这个星球上最强大的库之一,如果不是最强大的话. PyQt作为一组Python模块的实现.有超过300个类和超过 ...
- BZOJ1003 物流运输 题解
发现\(n,m\)很小,我们可以先把任意\(2\)天的最短路都给求出来,考虑\(DP\),设\(f[i][j]\)表示\(j+1\)~ \(i\)这几天内走的是最短路线的最优方案,显然最优情况下\(j ...
- Docker: GUI 应用,Ubuntu 上如何运行呢?
操作系统: Ubuntu 18.04 运行镜像: continuumio/anaconda3, based on debian Step 1) 安装 Docker # update the apt p ...
- win10和centos7双系统双磁盘引导的实现
win10和centos7双系统双磁盘引导的实现1.背景:dell5460笔记本电脑M2-120G固态盘无法在bios中引导,新装了M360G固态盘后,考虑把120G固态盘安装centos7.5系统做 ...
- JavaScript 引用数据类型
目录 1. 问题描述 2. 原因分析 3. React 中的引用数据类型 4. 业务场景 5. 参考资料 1. 问题描述 今天在写一个代码题时候, 有一个BUG 导致自己停滞好久, 该BUG 可以描述 ...
- ES6背记手册
ES6规范 阮一峰的ES6在线教程 在线图书--Exploring ES6 ES6 tutorials babel在线教程--https://babeljs.io/docs/en/learn.html ...
- 一:HTTP协议解析
一:HTTP协议解析 1.HTTP协议即超文本传输协议,是一种详细规定了浏览器和万维网服务器之间互相通信的规则,他是万维网交换信息的基础,它允许将HTML(超文本标记语言)文档从web服务器传送到we ...