Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习。
案例:
下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup、HttpClient、fastJson等。
正文:
1、分析是否可以获取到TOP500歌单
打开酷狗首页,查看TOP500,发现存在分页,每页显示22条歌曲,
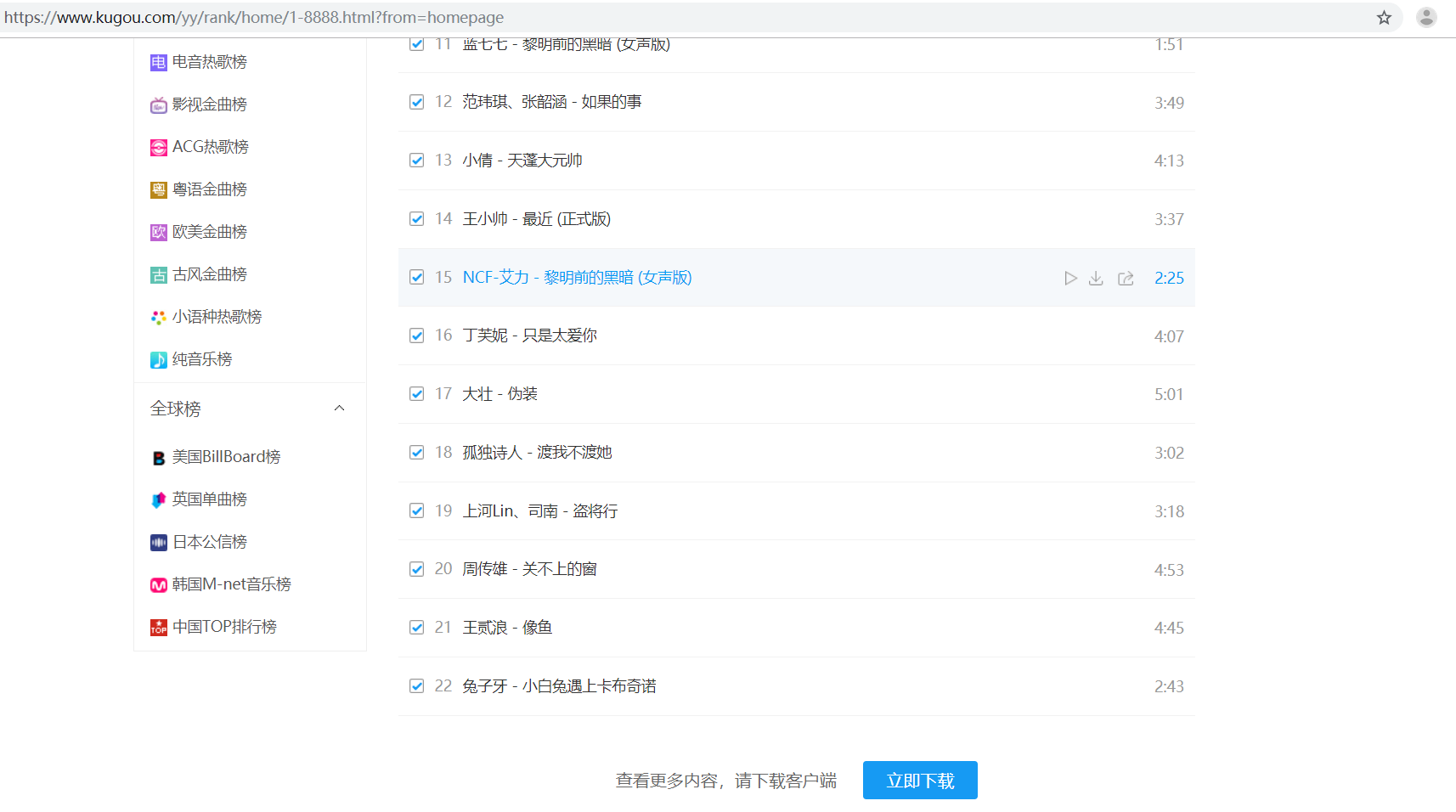
发现酷狗的链接如下:
https://www.kugou.com/yy/rank/home/1-8888.html?from=homepage
通过更改链接中的1可以进行分页,所以我们可以通过更改链接地址获取其余的歌曲。
2、分析找到正真的mp3下载地址
点一个歌曲进入播放页面,使用谷歌浏览器的控制台的Elements,搜一下mp3,很轻松就定位到了MP3的位置。
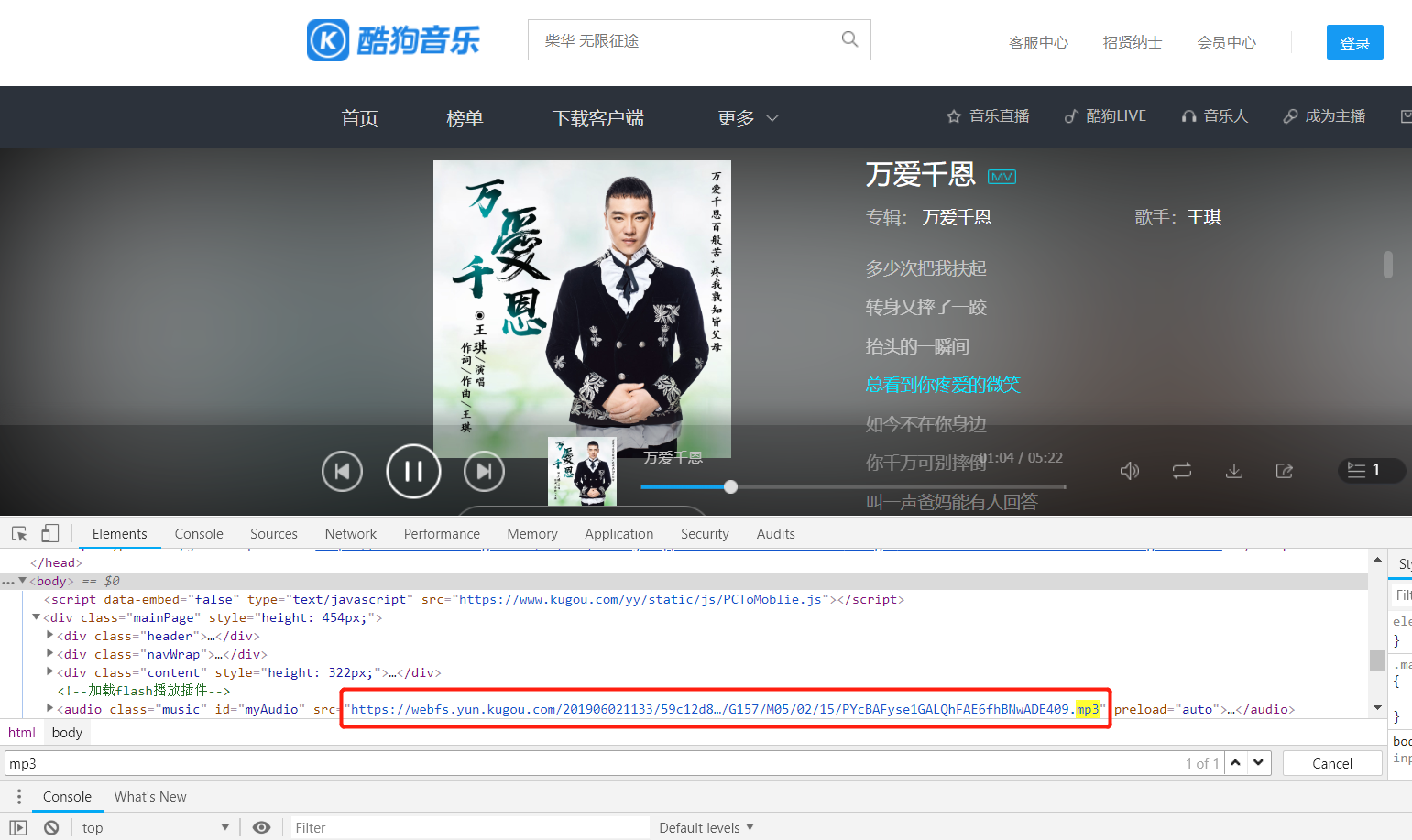
但是使用java访问的时候爬取的html里却没有该mp3的文件地址,那么这肯定是在该页面的位置使用了js来加载mp3,那么刷新下网页,看网页加载了哪些东西,加载的东西有点多,着重看一下js、php的请求,主要是看里面有没有mp3的地址。
最终在列表中找到:
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191044492686523157987_1559446927765&hash=458E9B9F362277AC37E9EEF1CB80B535&album_id=18712576&dfid=1ZxQbe0MiP8J09j5tR0Np9IA&mid=9393340fecff864a4d6c4e95099b2be1&platid=4&_=1559446927766
这个请求结果中发现了mp3的完整地址:

那这个js是怎么判断是哪首歌的呢,那么只可能是hash这个参数来决定歌曲的,然后到播放页面里找到这个hash的位置,是在下面的js里:
var dataFromSmarty = [{"hash":"667939C6E784265D541DEEE65AE4F2F8","timelength":"237051","audio_name":"\u767d\u5c0f\u767d - \u6700\u7f8e\u5a5a\u793c","author_name":"\u767d\u5c0f\u767d","song_name":"\u6700\u7f8e\u5a5a\u793c","album_id":0}],//当前页面歌曲信息
playType = "search_single";//当前播放
</script>
在去java爬取该网页,查看能否爬到这个hash,果然,爬取的html里有这段js,到现在mp3的地址也找到了,歌单也找到了,那么下一步就用程序实现就可以了。
3、代码实现

SpiderKugou.java
package com.billy.test; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* 爬取并下载酷狗的歌曲
*/
public class SpiderKugou { private static String filePath; //酷狗地址
private static String LINK; //mp3地址
private static String mp3; static {
filePath = "F:/music/";
LINK = "https://www.kugou.com/yy/rank/home/PAGE-8888.html?from=rank";
mp3 = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19103632090130122796_1558800325111&"
+ "hash=HASH&_=TIME";
} public static void main(String[] args) throws Exception { for(int i = 5 ; i < 23 ; i++){ String url = LINK.replace("PAGE", i + "");
downSong(url);
}
} /**
* 下载歌曲
* @param url
* @throws Exception
*/
private static void downSong(String url) throws Exception{ HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8");
HtmlManage html = new HtmlManage();
Document doc = html.manage(content);
Element ele = doc.getElementsByClass("pc_temp_songlist").get(0);
Elements elements = ele.getElementsByTag("li");
for(int i = 0 ; i < elements.size() ; i++){ Element item = elements.get(i);
String title = item.attr("title").trim();
String link = item.getElementsByTag("a").first().attr("href");
downLoad(link,title);
Thread.sleep(1000);
}
} /**
* 下载
* @param url
* @param name
* @throws IOException
*/
private static void downLoad(String url,String name) throws IOException{ String hash = "";
HttpGetConnect connect = new HttpGetConnect();
String content = connect.connect(url, "utf-8"); String regEx = "\"hash\":\"[0-9A-Z]+\"";
// 编译正则表达式
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
hash = matcher.group();
hash = hash.replace("\"hash\":\"", "");
hash = hash.replace("\"", "");
} String item = mp3.replace("HASH", hash);
item = item.replace("TIME", System.currentTimeMillis() + "");
System.out.println("item:" + item); String mp = connect.connect(item, "utf-8");
mp = mp.substring(mp.indexOf("(") + 1, mp.length() - 3); JSONObject json = JSON.parseObject(mp);
if(Integer.parseInt(json.get("status") + "") != 0){ String playUrl = json.getJSONObject("data").getString("play_url");
FileDownload down = new FileDownload();
down.download(playUrl, filePath + name + ".mp3");
} } }
HttpGetConnect.java
package com.billy.test; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.HttpEntity;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.BasicHttpClientConnectionManager; import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader; /**
* httpclient 工具类
*/
public class HttpGetConnect { /**
* 获取html内容
* @param url
* @param charsetName UTF-8、GB2312
* @return
* @throws IOException
*/
public static String connect(String url,String charsetName) throws IOException{
BasicHttpClientConnectionManager connManager = new BasicHttpClientConnectionManager(); CloseableHttpClient httpclient = HttpClients.custom()
.setConnectionManager(connManager)
.build();
String content = ""; try{
HttpGet httpget = new HttpGet(url); RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000)
.setConnectTimeout(50000)
.setConnectionRequestTimeout(50000)
.build();
httpget.setConfig(requestConfig);
httpget.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
httpget.setHeader("Accept-Encoding", "gzip,deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("Upgrade-Insecure-Requests", "1");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
httpget.setHeader("cache-control", "max-age=0"); httpget.setHeader("Referer","https://www.kugou.com/song/"); //设置cookie
httpget.setHeader("Cookie", "kg_mid=9393340fecff864a4d6c4e95099b2be1;"); CloseableHttpResponse response = httpclient.execute(httpget); int status = response.getStatusLine().getStatusCode();
if (status >= 200 && status < 300) { HttpEntity entity = response.getEntity();
InputStream instream = entity.getContent();
BufferedReader br = new BufferedReader(new InputStreamReader(instream,charsetName));
StringBuffer sbf = new StringBuffer();
String line = null;
while ((line = br.readLine()) != null){
sbf.append(line + "\n");
} br.close();
content = sbf.toString();
} else {
content = "";
} }catch(Exception e){
e.printStackTrace();
}finally{
httpclient.close();
}
log.info("content is " + content);
return content;
} private static Log log = LogFactory.getLog(HttpGetConnect.class);
}
HtmlManage.java
package com.billy.test; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; /**
* html manage 工具类
*/
public class HtmlManage { public Document manage(String html) {
Document doc = Jsoup.parse(html);
return doc;
} public Document manageDirect(String url) throws IOException {
Document doc = Jsoup.connect(url).get();
return doc;
} public List<String> manageHtmlTag(Document doc, String tag) {
List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByTag(tag);
for (int i = 0; i < elements.size(); i++) {
String str = elements.get(i).html();
list.add(str);
}
return list;
} public List<String> manageHtmlClass(Document doc, String clas) {
List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByClass(clas);
for (int i = 0; i < elements.size(); i++) {
String str = elements.get(i).html();
list.add(str);
}
return list;
} public List<String> manageHtmlKey(Document doc, String key, String value) {
List<String> list = new ArrayList<String>(); Elements elements = doc.getElementsByAttributeValue(key, value);
for (int i = 0; i < elements.size(); i++) {
String str = elements.get(i).html();
list.add(str);
}
return list;
} private static Log log = LogFactory.getLog(HtmlManage.class);
}
FileDownload.java
package com.billy.test; import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream; import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients; /**
* 文件下载工具类
*/
public class FileDownload { /**
* 文件下载
*
* @param url 链接地址
* @param path 要保存的路径及文件名
* @return
*/
public static boolean download(String url, String path) { boolean flag = false; CloseableHttpClient httpclient = HttpClients.createDefault();
RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(2000)
.setConnectTimeout(2000).build(); HttpGet get = new HttpGet(url);
get.setConfig(requestConfig); BufferedInputStream in = null;
BufferedOutputStream out = null;
try {
for (int i = 0; i < 3; i++) {
CloseableHttpResponse result = httpclient.execute(get);
System.out.println(result.getStatusLine());
if (result.getStatusLine().getStatusCode() == 200) {
in = new BufferedInputStream(result.getEntity().getContent());
File file = new File(path);
out = new BufferedOutputStream(new FileOutputStream(file));
byte[] buffer = new byte[1024];
int len = -1;
while ((len = in.read(buffer, 0, 1024)) > -1) {
out.write(buffer, 0, len);
}
flag = true;
break;
} else if (result.getStatusLine().getStatusCode() == 500) {
continue;
}
} } catch (Exception e) {
e.printStackTrace();
flag = false;
} finally {
get.releaseConnection();
try {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
} catch (Exception e) {
e.printStackTrace();
flag = false;
}
}
return flag;
} private static Log log = LogFactory.getLog(FileDownload.class);
}
Java爬取并下载酷狗音乐的更多相关文章
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Python 应用爬虫下载酷狗音乐
应用爬虫下载酷狗音乐 首先我们需要进入到这个界面 想要爬取这些歌曲链接,然而这个是一个假的网站,虽然单机右键进行检查能看到这些歌曲的链接,可进行爬取时,却爬取不到这些信息. 这个时候我们就应该换一种思 ...
- Python爬虫下载酷狗音乐
目录 1.Python下载酷狗音乐 1.1.前期准备 1.2.分析 1.2.1.第一步 1.2.2.第二步 1.2.3.第三步 1.2.4.第四步 1.3.代码实现 1.4.运行结果 1.Python ...
- 【Python3爬虫】下载酷狗音乐上的歌曲
经过测试,可以下载要付费下载的歌曲(n_n) 准备工作:Python3.5+Pycharm 使用到的库:requests,re,json,time,fakeuseragent 步骤: 打开酷狗音乐的官 ...
- Python代码搜索并下载酷狗音乐
运行环境: Python3.5+Pycharm 实例代码: import requests,re keyword = input("请输入想要听的歌曲:") url = " ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载
上次学了jsoup之后,发现一些动态生成的网页内容是无法抓取的,于是又学习了htmlunit,下面是抓取酷狗音乐与qq音乐链接的例子: 酷狗音乐: import java.io.BufferedInp ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
随机推荐
- koa 项目实战(三)创建测试接口和用户模型
1.创建测试接口,并引入用户模型 根目录/routes/api/users.js const Router = require('koa-router'); const router = new Ro ...
- PHP AJAX返回 "TEXT"
例子:通过AJAX间接访问数据库,查出Nation表显示在页面上,并添加删除按钮 //首先在外层添加一个按钮,并造好表头 <div><input type="button& ...
- java 百度地图判断两点距离2
package baiduApi; public class BaiDuMap { static double DEF_PI = 3.14159265359; // PI static double ...
- [eclipse]如何修改Eclipse编辑器的字体
步骤如下, 菜单->"Window"->“Preference”->“General”->“Appearance”->“Colors & Fo ...
- JNI知识扩展
JNI(Java Native Interface,JAVA原生接口) 使用JNI可以使Java代码和其他语言写的代码(如C/C++代码)进行交互. 问:为什么要进行交互? |- 首先,Java语言提 ...
- .NET GC简单理解
内存分配 计算对象大小. 添加对象指针和同步索引块. 从内存指针处开始,分配对象内存. 问题:内存不能无限制增长. 垃圾回收 从应用程序实例出发,标记所有的引用对象. 将标记对象移动到低地址端,修正实 ...
- 七十九:flask.Restful之flask-Restful蓝图与渲染模板
1.flask-Restful与蓝图结合使用如果要在蓝图中使用flask-Restful,那么在创建Api对象的时候,就不应该使用app,而是蓝图,如果有多个蓝图,则需在每一个蓝图里面创建一个Api对 ...
- 1、puppet基础
Puppet:IT基础设施自动化管理工具 参考文章: https://yq.aliyun.com/articles/120228 http://www.51niux.com/?id=105 http: ...
- Redis ==> 集群的三种模式
一.主从同步/复制 通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据. 但是由于数据是存储在一台服务器 ...
- 能详细说一下action:=cafree这句吗?好多书都没说清楚!
关闭一个窗口有几种方式:最小化这个窗口,隐藏这个窗口,释放这个窗口,这句话就是说但这个窗口关闭的时候释放这个窗口,它应该是在form的onclose事件里面的 就是form.onclose() beg ...