SIGAI机器学习第一集 机器学习简介
讲授机器学习的基本概念、发展历史与典型应用
大纲:
人工智能简介
机器学习简介
为什么需要机器学习
机器学习的发展历史
机器学习的典型应用
人工智能主要的公司
本课程讲授的算法
机器学习并不是人工智能一上来就采用的方法,而是发展到一定阶段之后的产物
这门课需要的参考书:(前面两本有点老,没有讲深度学习的东西,但神经网络讲的还是比较详细的)

人工智能简介:
定义:用计算机来实现人的智能。
1956年人工智能达特茅斯会议,2016年(AlphaG)人工智能大规模进入公众的视野。
图灵奖最多的方向:CPU的设计(CPU结构、精简指令计算机);编程语言的(包括编译器);操作系统;计算机网络;数据库;理论计算;AI(有6次图灵奖)。
AI是获得图灵奖最多的方向之一:
2011 Judea Pearl(概率图模型)
2010 Leslie Valiant(PAC理论)
1994 Edward Feigenbaum,Raj Reddy
1975 Allen Newell,Herbert A. Simon
1971 John McCarthy
1969 Marvin Minsky
1994年获奖还是和前几次一样,主要是传统的思路和方法,比如说专家系统、知识工程、逻辑推理等等一些套路。
2010、2011年就不一样了,这些成果是属于机器学习方向,所以说机器学习是人工智能发展到后来才出现的一类方法和理论,并不是上来就采用的一条路。
PAC理论可以导出Adaboost等其他一些方法,是一个非常基础的理论。
概率图模型典型的就是贝叶斯网络或其他的一些方法,如马尔科夫随机场、条件随机场、马尔科夫过程、隐马尔可夫模型等等。
机器学习逐渐成了人工智能解决很多实际问题一种主流的方法,所以说人工智能不等同于机器学习,人工智能中还有一些其他的方法还是可以使用的。
AI可以模拟人的智能,那么人有什么智能呢?
第一台真正意义上的计算机是1945年发明的,它发明的目的是用来计算炮弹飞行的弹道(根据初始和目标坐标计算导弹飞行的轨迹),二战期间军方作战需要,开始只是用它来做计算器使用,后来发挥的用武之地远远超出人们的想象,正在逼近人类智能的能力。
机器学习简介:
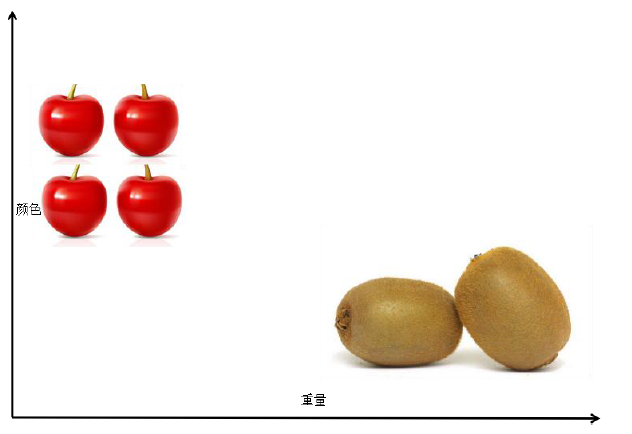
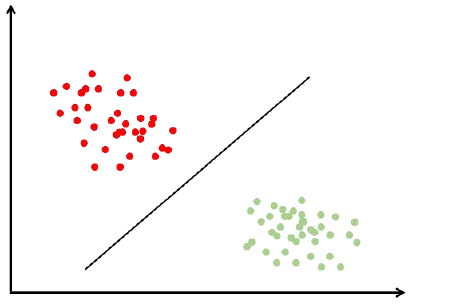
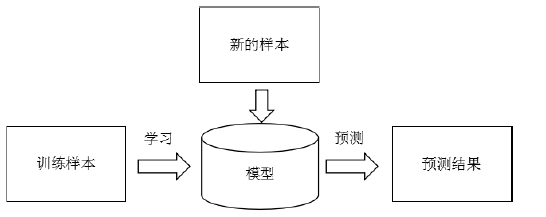
解决一般问题的流程:
对人的学习能力的一种模拟,
人工智能发展经历这么几个阶段:
第一个阶段,侧重于逻辑表达、知识推理的东西,比如根据一些基本的公理来证明一些数学定理和公式
第二个阶段,知识工程和专家系统,比如解决一个为人看病的问题,可以把医生的经验描述出来告诉计算机让计算机来判定,会面临问题:①不具有通用性,即对很多新的问题都要建立一个规则和专家系统来解决这样的问题,需要的成本很高也需要各个领域的专家。②有些问题可能用知识是不太好描述的,比如图像识别,什么样的图像是猫还是狗,最笨的方法就是暴力破解,如256*256的图像,共256256*256种可能,所以不可以实现。
根小孩学习相似,给计算机大量样本去学习,学习完了得到一个经验或者一个模型,后边可以根据这个模型去识别水果。显然这种方法具有很好的通用性,因为把训练样本一换就可以识别不同的水果了。不用直接把知识和经验归纳出来告诉计算机,也就解决了第二个问题一些知识难以描述的问题。
只要是有精确的数学模型和物理模型的一些问题,计算机他就远比人强,因为它能执行一个确定的计算,如果有些东西难以准确的描述出来,只可意会不可言传的问题计算机都不太去好求解,如什么样的东西是香蕉什么样的东西是苹果,没法建立很明确的数学模型来告诉它,而这类问题就是计算机里的机器学习技术所擅长的事情。总结起来,可以用一句话来概括机器学习,“授人以鱼,不如授人以渔”,这里人是指人工智能AI,渔是告诉计算机自己去学习,与其把经验和知识告诉计算机,那还不如让它自己去学习这些经验与知识去,这就是机器学习的一个核心的思想。
机器学习的发展历史:
虽然机器学习这个词在1950年就提出来了,但是它真正的作为一门独立的学科,成家立业从人工智能里面分出来,那是1980年左右的事情了,所以一般可以从1980年开始算起,因为第一届机器学习的会议和期刊是1980年开始做的。
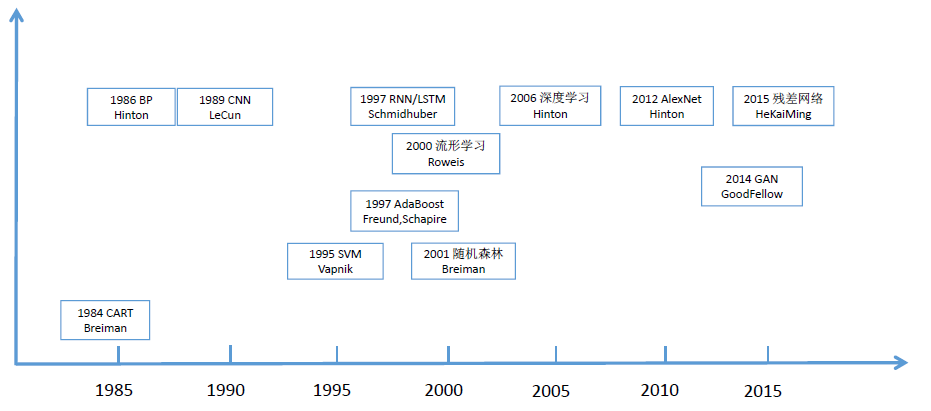
把整个机器学习划分为三个阶段:
早期阶段:1980-1990年
第二阶段:1990-2012年
第三阶段:2012年之后
早期,机器学习还处于探索之中,但是出现了一些比较经典的算法:BP反向传播算法,是用来训练多层神经网络的一种经典的算法,是Hinton等人发明的,Hinton不是第一作者因为后边他对深度学的影响是非常大的。然后另一个成果是决策树,这里只列举了CART分类与回归树,实际上还有ID3、C4.5等其他的算法,实际上是一种人工规则的方法用机器学习来实现的。1989年LeCun发明CNN,这个卷积神经网络就是我们现在深度卷积神经网络的鼻祖了,CNN、RNN是解决实际问题的两种主流的网络,一种是空间结构的卷积,一种是带有记忆功能的适合处理这种时间序列的数据。这个阶段总体来说成果还是比较偏少的,处于探索阶段。
第二阶段可谓是百家齐放、百家争鸣的阶段了,出现了很多的成果。强化学习、半监督学习、无监督学习在这里列出的偏少了,重点关注有监督学习,它是更多人需要掌握和了解的方向。Vapnik1995年发明SVM,在深度学习出现之前,它在和神经网络的较量中一直是处于上风的,在很多分类或者回归的问题上面取得当时最好的性能,比如做图像识别、文字识别、NLP中文本分类等等一些问题。AdaBoost算法是一个非常经典的算法,几乎可以与SVM并列的算法。1997年还出现一个算法LSTM,它是RNN的改进,后来被发扬光大,虽然1997年就出来了但当时并没有引起广泛的关注应用的也非常少。2000年出现流形学习,这是一类方法的统称,一种非线性的机器学习的技术,当时也是名噪一时,但是实际应用中成功的并不多。2001年随机森林RF也是一种非常经典的算法,它和CART发明的是同一个人(挺喜欢做树的,他已经去世了),目前还有很多公司在用的。2006年,Hinton写的一篇Science上的一篇文章,后来经常被人们提起,用来解决深度神经网络难以训练的问题,它是先用玻尔兹曼机训练神经网络的每一层得到一个初始权重值,然后再用它作为初始值把整个网络合起来再整体学一遍,用这种策略来解决这种问题,当时号称是深度学习的鼻祖,但是思想归思想,后边其实使用的是比较少的,目前用的最多的还是CNN和RNN这两个东西,在语音识别、图像识别、NLP等很多领域中都在广泛应用的。
最后一个阶段是一个最振奋人心的阶段:深度学习时代,真正大规模兴起是从2012年AlexNet在ImageNet的比赛中夺得好的名次发了一篇好论文开始的,从此以后整个CNN基本上席卷了整个CV领域,被发扬光大到图形学、NLP等等其他的领域。而这个时候,RNN也满血复活了,它在NLP的自动语音识别ASR也是大显神通碾压了其他传统经典的算法,从此我们就进入了深度学习时代。还有另外一些算法,比如说,深度强化学习AlphaGo采用的思想、生成对抗网络等等,它们作为深度学习时代的典型代表被计入史册。
从另外一个角度来看,产业界来看,第一个阶段1980-1990年之间机器学习在工业界真正实际应用的还是比较少的,直到1989年LeCun发明了卷计算机网络,才开始在邮政的支票识别分拣系统中开始用了,别的没有大规模使用,所以说这也是1990年划分阶段的一个重要原因,就是它没有真正大规模的使用。第二个阶段,1990-2012,这就大规模的使用化了,比如SVM、Adboost算法、随机森林等很多算法,在人脸识别、人脸检测、语音识别,高斯混合模型和HMM,一些数据的分析,搜索引擎,还有好多地方都在实际的使用这些机器学习算法了,它真正的走进了应用。第三个阶段2012年以后,就更不得了了,在产业界开始爆发了,引发了AI的一波浪潮了,从目前来看也不知道这个浪潮会持续多久,持乐观态度,毕竟深度学习它很好的解决了感知问题(视觉和听觉问题),从目前来看还是很振奋人心的,而且新方法和改进层次不穷的出来。
机器学习的典型应用:
机器学习是一种方法,而不是一些实际的应用问题。
用的最多的领域:机器视觉CV,如人脸识别,图像识别,图像检测,图像分割,跟踪等等;语音识别;NLP;数据挖掘。
①人脸检测:
找出图片中所有的人脸。面临的问题:人脸可能出现图片中任意位置,人脸可能有不同大小。可以用一个矩形框从上到下从左往右在图形中滑动,判断被框住区域是否是人脸,二分类问题,是否是人脸。因为人脸大小不同,所以可以缩放矩形框。
人脸检测会面临很多困难的因素:人脸有很多的姿态和表情非常复杂,最开始使用模板匹配的方法,用框住区域和人脸匹配看是否是人脸,这样是非常死板的效果非常差,后来用机器学习来做。人脸检测还会面临拍到的角度和姿态可能不同,人脸可能会有俯仰、偏转角三个自由度的旋转,加上呈像的时候光照会变化,遮挡物如眼睛头发等等,这个问题是相当复杂的,这也是机器学习机器视觉里边研究的比较透的一个问题,因为他有很强的实用价值。
人脸检测应用的地方:安装监控,监控场景里所有的人,肯定先把人脸先找出来,来判断他是谁。人脸识别,要识别出这个人是谁,首先要把人脸先找出来。数码相机或手机的自动对焦,会对焦到人脸上去框住人脸的那块区域,还有虚拟美颜如美图秀秀,首先要知道人脸在什么地方五官在什么地方。
而人脸检测算法辛辛苦苦做了这么多年,一直到2001年才产生第一次突破,当时有两个人,他们两个名字简写是VJ,发明了一个VJ框架,后来这个框架被广泛的使用,就是用1997年的AdaBoost分类器加上简单的Haar特征,来解决人脸检测的问题,速度非常高精度也还挺高的,比以前的算法进步很大,这是人脸检测历史上第一次有里程碑意义的突破,也带动这场技术最后走向实用,这也只是解决了正面或近似正面的人脸检测问题,如果是侧面的话会相当的复杂,所以也可能会训练几个不同的分类器合作来检测各个角度的人脸,总之它处理的还是不太好,而下一次真正有里程碑意义的突破是深度学习兴起之后,用卷计算机网络CNN来做人脸检测,从2014年、2015年以后大量的文章出现,才算真正比较好的把这个问题解决掉了,可以看FDDB的官网,是人脸检测的一个开源的数据库,上边有各种算法的测评结果用来比较,可以看他们的ROC曲线看哪一个算法好一些。
②行人检测
和人脸检测类似,目标是把图片中所有的行人给找出来,和人脸检测这个问题会复杂很多,人脸还近似是一个刚体不可能嘴巴跑到眼睛上边变化很大,人本身是一个有柔性的物体,他会有不同的姿态、穿的衣服发型、装饰物、背的行李拿的包、人的重叠、举手抬腿等等动作的干扰,造成这个问题会更复杂,给算法带来很大的挑战。行人检测是比人脸检测更难搞定的一个问题,但是它也有很多实用的价值。
用于视频监控,判断一个场景是否有人闯进来,如果有他会自动报警。自动驾驶中也需要这种技术,车需要知道路上路边有木有人走过来,他要把这些人给避开。客流统计系统,统计一个商场或超市进进出出有多少人,这也需要行人检测技术,它要通过摄像头把场景录下来,然后知道每个时刻有木有人、人出现在什么地方、并把这些人跟住。
行人检测它真正意义上有很大突破比人脸检测2001年要晚很多,2004、2005年提出一种算法,梯度方向直方图HoG+线性支持向量机SVM做行人检测,精度也不是很高,真正精度大规模提上去也是在深度学习出现以后,2014、2015年之后,用CNN做行人检测,做的非常准。
③语音识别
把声音的信号波形转化成文字,对于人来说是非常重要的,因为人最主要的两个直觉功能就是视觉和听觉,有非常强的实用价值。语音助手、翻译软件,它第一步就是把声音转化成文字识别出来。
语音识别原理:
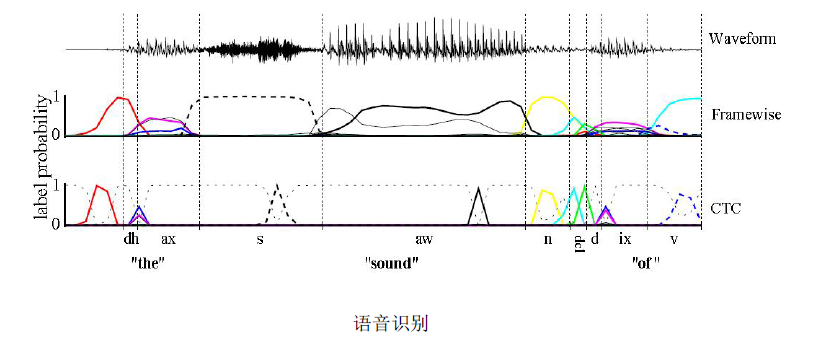
最上面是声音波形图,通过采样每个时间点上有一个振幅,串起来就是一段声音的信号,最后把它识别成文字。问题困难在,人可能发音不标准,不能拿一个标准的模板来匹配发音,不能指望每个人的发音像播音员那样标准,而且人还有方言和口音,可能还有不同的语言意会说中文一会说英文,还有背景噪声的干扰也会给算法带来挑战。本质上也是分类问题,确定每段波形它是属于哪一个文字,一般是把它切分成音节,如汉语中的一个韵母英文中的一个音标,再把这种音标片段组合成一个英文的单词或汉语的一个字或词。但是怎么知道每一个音标每一个音节它的起始位置在什么地方呢?在语音识别中这是一个对其问题,不太好解决的,用RNN来做语音识别。
语音识别在1980代就开始用机器学习来做了,最开始用的HMM,后来用HMM+高斯混合模型GMM(分别用来做声学建模和后边的处理),再后来全面导向了RNN深度学习框架,语音识别准确率被大幅度提高了,然后推动这种技术走向实用。
④自动驾驶
要知道道路在什么地方,车道线、车道、车道的边缘在什么地方。把路找出来,车道线找出来,再决定在哪个车道上面开,这是一个感知问题,图像识别的一个问题,可以用图像、激光雷达等手段来解决。找到路以后,路上可能有其他东西,如车和人,就要把车和人找出来,这就是刚才说的检测问题,行人检测、车辆检测问题,需要用机器学习来做。做完以后要知道各种交通标志和信号灯。这些问题解决掉之后,要判断前边车和后边车的行为,如往哪个方向开、速度多少。上边所有参数给出来以后,下面一步就是决定怎么控制这个车了,行驶的方向和速度等等,可以列举所有的情况,如十字路口怎么开前面2个人怎么开3个人怎么开,但是不可能把所有的情况穷举出来,因为所有的车的行驶距离、状态都是不一样的,把所有的情况列举出来是不可能的,所以不能用规则来做,一般来说还是用机器学习来做,现在有一种比较强大的手段叫深度强化学习,和AlphaGo思路有点类似,它能搞定这样的问题,效果还算不错,它就根据环境的一些输入决定下一步采取的动作是什么。
⑤人机对弈
AlphaGo,Go是围棋的意思。棋类游戏一直是检验AI发展水平的一个试金石,很早以前我们就搞定了五子棋和一些简单的棋类游戏,可以采用搜索树、剪枝等的算法可以简单的解决一个人机对弈的五子棋游戏。1997年IBM的深蓝DeepBlue,也是采用传统的算法如剪枝树搜索等,用人工的知识和规则来下棋,只不深蓝过电脑的运算能力非常强,那样也打败了(险胜)世界象棋冠军俄罗斯人拉斯卡洛夫,当时非常轰动,大家觉得AI的春天来了,但实际上紧接着又是冬天。一直到2016年AI才又一次大规模的走入公众的视野(AlphaGo引起的),虽然AlphaGo也是下棋,但它的套路和之前已经很不一样了,它是用机器学习的手段深度强化学习解决这样一个问题的,它是用大量的人类的棋谱或机器的棋局来训练,然后得到一个模型,这个模型的输入就是当时的棋局的状态如哪个地方有子哪地方没子,然后它的输出是下一步它该往哪个方向走最可能赢。
⑥机器翻译
机器翻译是一个非常困难的事情,人都不一定做的好,通过字典一个个翻译过来会显得非常生硬不流畅,早期的时候确实是用了这样的一些思想来做的人工规则来做,但后来转向了机器学习,现在深度学习用的非常多,像谷歌、搜狗、百度等机器翻译系统都是用深度神经网络来做的,准确的来说使用循环神经网络RNN来做的,这里边采用了一种技术叫Seq2Seq序列到序列的学习,可以把每种语言的话当作一个序列,先给它断句断开断成一个一个词,断开以后得到A这种语言的一个词序列,然后把它转化为另外一种语言的词序列就可以了,这又是机器学习要完成的一个任务。
人工智能主要的公司:
国外:
做搜索引擎起家的,他是最有动力也是天然适合做AI这件事情的。他也是全世界巨头里边最早大规模布局AI的一个公司。谷歌在AI方面有哪些建树呢?
①TensorFlow深度学习和机器学习的开源框架。②谷歌大脑,在2012年深度学习火以后就马上把深度学习的发明者Hinton挖到了谷歌,后来把吴恩达也挖过去了,但是后来吴恩达又去百度了,总之养了一帮牛逼的人在研究一些事情。
谷歌每次战略布局都非常高明,比如说它的移动互联时代他赶上了这波浪潮,他做了一个安卓系统,虽然安卓是他收购的,但是他收购之后又花重金去改进它,最后安卓成了一个主流的移动端的操作系统,微软就没赶上这次机会。在云计算时代他又赶上了,也可以说云计算就是他们搞出来的,虽然之前IBM这些公司做了一些概念如网格计算或者其他的一些概念,但真正意义上的云计算是谷歌弄出来的,包括云计算里面三驾马车:GFS、bigtable、MapReduce都是他们三篇论文发出来的,被业界纷纷效仿,像hadoop等都是仿照他们做的。
DeepMind
现在也是属于谷歌的,它是英国的一家公司后来被谷歌收购了,这个公司一共没有多少人,但收购价格非常高,每个人平均超过一千万英镑。这个公司做的AlphaGo,里边在做一些黑科技的东西,比较偏基础和理论的,还有比较前沿的研究,可以去他们官网看一下发表的论文和做出的成果。
MicroSoft
微软虽然已经落寞了,瘦死的骆驼比马大,但还是还是很强大的,里边养了一帮图灵奖得主,在AI方面也是有大量的人才储备技术储备的,可以去它的各个研究院官网上看一下,MSRA中国微软亚洲研究院是国内的第一阵营,美国那边的研究院等都是非常强大的。
Open AI
非盈利的公司,带有公益性质的,投资人比较多,特斯拉老总投过这个公司,里边也养了一帮牛人。
Facebook
AI做的也是有声有色的,有一个实验实叫FaceBook人工智能研究院FAIR,里边养了一帮牛人,如卷积神经网络之父YanLeCun,还有SVM的发明人,当时SVM火了好久神经网络不火现在轮到神经网络火起来了,国内知名度比较高的做目标检测各种机器视觉问题的何凯明也在里边。
Amazon
它的战略布局也是非常高明的,同样是卖书起家的,当当和亚马逊天壤之别,亚马逊的云也是搞的有声有色的,EC2、AWS、亚马逊的webservices、S3存储服务等都做得非常好,像国内的京东、阿里巴巴等也是在模仿它的一些东西。他在AI上面的建树是做了一个产品叫做Echo智能音箱,被国内很多公司在仿造,就是做一些语音命令的控制,比如说开灯关灯开门关门可以直接对音箱说一句话,它能理解你的意思然后把指令发送到要控制的设备上去然后执行这个动作。
Mobileye
是以色列的一个公司,犹太人国土面积很小人也没多少,但是他各方面非常强大,如军事方面,各种先进的武器军工,农业也非常强大,科技领域也诞生了很多牛逼的公司,Mobileye就是其中之一。Mobileye是1999年成立的,做的非常艰辛,他们的第一款产品到2007年才做出来,是做汽车的辅助驾驶系统的,特斯拉之前就是用的他们的辅助驾驶系统,中间融资融了好多人,融了十几轮,终于开始有收入了,前几年还上市了,在2017年被Intel收购了,154亿美元,非常高的价格,这公司人也不多。intel为什么收购该公司呢?英伟达NVIDIA做显卡GPU做的风生水起,然后AI时代来了,占了一把先机,Intel也不能落后,也要布局,所以他把Mobileye收购了想整合。Mobileye行人检测技术还是很强大的,2012年之前清华的BBS上就讨论他们的行人检测为什么做的这么准,那时深度学习没有火起来,可能有些公司偷偷的也在用卷积神经网络做行人检测这样的事情,但是工业界大规模使用的还是SVM和Adaboost加上运动目标的检测等那套思路来做的,检测率和误报率始终做不到一个很高的精度,但是Mobileye他们做的非常准,可能做了一些工程方面的优化,这也说明有些公司他有牛逼的技术但是他不会发论文也不会写专利而是偷偷自己在那用。
国内:
国内的一些公司虽然整体实力和美国来比还是有一定差距的,但是我们也是做的风生水起,可以说这一波国内的AI还是很有建树的。
百度:
百度也是和谷歌对标的一个公司,他也是做搜索引擎起家的,也天然适合做AI这个事情的。在深度学习出现以前,做NLP、数据挖掘等各种算法的人也非常多,用在搜索和相关的产品上边。然后2012年深度学习火起来之后,百度李彦宏马上就成立了研究院叫IDL挖了一些牛人过来如余凯,后来美国建立研究院把吴恩达挖过来掌管这些部门,做了很多工作,现在又在上边加大了力度,AI被进一步强化了。百度AI做了哪些成果出来呢?
①阿波罗,和阿波罗登月(总统说过:我们做这件事不是因为它很简单,而是因为它很难)是同一个名字,阿波罗现在是开源的一个自动驾驶平台,很多厂商已经挤进来的,可以去官网看一下它的源代码和模型。②另一个被广泛宣传的东西叫DuerOS,类似一个语音助手一样的东西,它可以识别你的声音转化为文字并且理解你的意图,是一个很复杂的系统。
科大讯飞
也是1999年成立,BAT也是1999年左右,一直到2012年深度学习火之后它的业务才大规模铺开,把语音的识别率一下提升了很多,国内这些做AI创业的人应该拿出一部分钱分给Hinton这样的人,没有他们的话就没有这些公司的今天。科大讯飞专业做语音的,现在也在做一些其他的东西,可以去官网看一下,科大讯飞股票这几年涨的很多。
face++、商汤
他们都是做机器视觉起家的。face++2011年成立的,清华那帮人搞的,公司也是在清华东门外边。商汤2014年成立的,香港中文大学的汤晓鸥他们实验室的出来搞的,汤晓鸥是做人脸识别算法的,做的非常好的一个。这两个公司现在估值都非常高,融资额也非常巨大,经常会被拿出来宣传,两个公司2017、2018年分别融了一笔巨资,发展的非常好。
依图
做图像识别的。
思必驰
在苏州,主力很多是在上海交大毕业的,也是做一些有特色的语音识别的产品。
第四范式
创始人是戴文渊,做各种商业智能的,做数据挖掘数据分析的。
深鉴、寒武纪
比较有特色的,是做芯片的,深度学习好用,但是很多算法得在很强大的CPU、GPU上边才能跑的起来,而好的CPU、GPU功耗很大,占体积也很大,散热各方面都是问题,而且成本极高,nvidia显卡很多都上万,如果把这些芯片装到智能手机或智能终端上边,比如说智能家居产品上边,这显然是不现实的,所以我们要对神经网络做一些优化,做一些压缩、剪枝等,能加速它的运行速度,然后减少它占用的存储空间,这是非常有意义的一件事情,这些公司在做这些事情。
应该来说,我们国内整个AI产业链布局是非常完整的,从芯片到技术的算法平台一直到应用,包括更上层的一些垂直领域的应用,比如智能医疗自动诊断疾病,到工业上面、商业方面的应用,做的都是非常完善的、成体系化,所以说,以后我们国家的AI,整个实力还是会非常强劲的。
本课程讲授的算法:
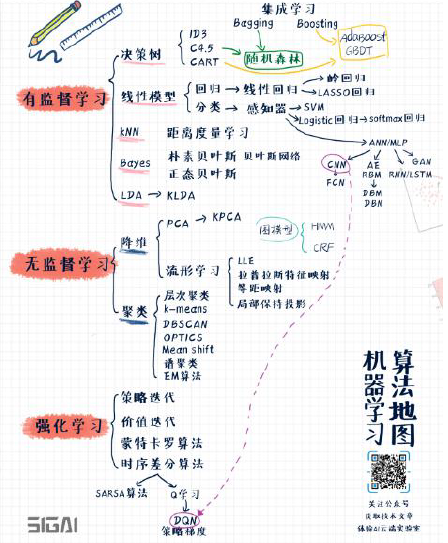
分为几类:有监督学习、无监督学习、强化学习。
有监督学习分为分类和回归两大类,主体是分类算法。
无监督学习分为数据降维、聚类算法这两大类。
强化学习是一个很独特的分支。
①有监督学习算法
决策树家族:重点讲CART。集成学习是机器学习里面的一种思想,它的总体想法是把多个模型集成起来形成一个更强大的模型进行预测。集成学习里面有两种主要的实现手段,第一类叫Bagging,第二类叫Boosting,如果是Bagging和决策树相结合的话,就诞生一种算法叫随机森林,Boosting如果和决策树相结合,就诞生一种叫AdaBoost算法,除此之外还有另外一种提升树叫GBDT。
线性模型的家族:分成两类,分别是回归问题和分类问题。对于回归问题就是线性回归,为了避免过拟合,会给线性回归加上正则化项,如果加上L2正则化的话就得到了岭回归算法,如果加上L1正则化的话就是LASSO回归算法。对于分类问题的处理,最简单的就是感知器模型,一种非常古老的算法在1950-1960年就已经诞生了,因为这种算法简单,就不过多对它阐述;从感知器算法里面得到一种新的算法,按照最大化分类间隔思想,就是SVM;感知器的另外一个分支是Logistic,它是直接把线性预测器改装了一下,然后用Logistic函数映射一下得到一个0到1之间的概率值用来解决二分类问题,可以把Logistic推广到多分类问题的版本也就是著名的softmax回归,对于多分类问题很多时候神经网络最后一层就是接的softmax它在预测的时候使用;从感知器里边诞生的另一种分支,叫人工神经网络ANN(或叫全连接神经网络或多层感知器模型MLP),从全连接神经网络里面又诞生了一些新的算法,比如CNN、CNN的改进型全卷积神经网络FCN,自动编码器AE、玻尔兹曼机RBM,生成对抗网络GAN,循环神经网络RNN等等,会在深度学习里边讲解。
K近邻家族:非常简单的一类算法,里边要依赖一个距离函数的定义,由此引出了另外一种机器学习算法叫距离度量学习算法。
贝叶斯家族:贝叶斯分类器分为两种类型,朴素贝叶斯和正态贝叶斯。
线性投影技术LDA:它是有监督学习的投影,它的思想是最大化类间差异,最小化类内差异,它有它的非线性版本,加上核函数、核映射以后得到一个叫KLDA的算法,KLDA不做重点介绍。
②无监督学习
降维算法:最经典的就是主成分分析PCA以及它的改进版本核主成分分析KPCA,这种算法会在很多地方大规模使用的,它是一种线性的降维技术。非线性的降维技术典型的代表是流形学习,对于数学知识要求稍微高一点点,会讲述四种有代表性的算法,分别叫局部先行嵌入LLE、拉普拉斯特征映射、等距映射、局部保持投影这四中国算法。
聚类算法:是无监督学习里面用的最广的一类算法,会介绍这么几种算法,分别是层次聚类算法、K均值算法K-means、基于密度的聚类(有三种类型,分别是DBSCAN、OPTICS、均值漂移Mean shift算法)、谱聚类算法(是一种基于图论的算法)、EM算法(基于概率的算法)
以上,常用的机器学习算法介绍完了,唯一要补充的就是概率图模型:典型代表是贝叶斯网络、隐马尔可夫模型HMM、条件随机场CRF等等。
③强化学习
强化学习算法是一类非常特殊的机器学习算法,主要用在策略和控制类的问题里面,它要解决的问题就是让智能体根据环境的输入来决定某一个动作,如自动驾驶的汽车就是一个典型的例子,它要根据当前的路况决定往哪个方向开。在强化学习里边,首先介绍马尔可夫随机场的概念,然后会介绍这么一些算法,分别是,策略迭代算法、价值迭代算法,这两种是有模型的算法,就是说他们依赖于一个精确的环境模型;无模型的算法分为蒙特卡罗算法、时序差分算法这两类来进行介绍。时序差分算法又分为两种算法,Q学习和SARSA算法(是五个字母的简写)。
本集总结:
SIGAI机器学习第一集 机器学习简介的更多相关文章
- SIGAI深度学习第一集 机器学习与数学基础知识
SIGAI深度学习课程: 本课程全面.系统.深入的讲解深度学习技术.包括深度学习算法的起源与发展历史,自动编码器,受限玻尔兹曼机,卷积神经网络,循环神经网络,生成对抗网络,深度强化学习,以及各种算法的 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 吴恩达《深度学习》-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-第一周 机器学习(ML)策略(1)(ML strategy(1))-课程笔记
第一周 机器学习(ML)策略(1)(ML strategy(1)) 1.1 为什么是 ML 策略?(Why ML Strategy?) 希望在这门课程中,可以教给一些策略,一些分析机器学习问题的方法, ...
- 机器学习入门 - Google机器学习速成课程 - 笔记汇总
机器学习入门 - Google机器学习速成课程 https://www.cnblogs.com/anliven/p/6107783.html MLCC简介 前提条件和准备工作 完成课程的下一步 机器学 ...
- python学习第一讲,python简介
目录 python学习第一讲,python简介 一丶python简介 1.解释型语言与编译型语言 2.python的特点 3.python的优缺点 二丶第一个python程序 1.python源程序概 ...
- web安全之机器学习入门——2.机器学习概述
目录 0 前置知识 什么是机器学习 机器学习的算法 机器学习首先要解决的两个问题 一些基本概念 数据集介绍 1 正文 数据提取 数字型 文本型 数据读取 0 前置知识 什么是机器学习 通过简单示例来理 ...
- NanUI for Winform 使用示例【第一集】——山寨个代码编辑器
NanUI for Winform从昨天写博客发布到现在获得了和多朋友的关注,首先感谢大家的关注和支持!请看昨天本人的博文<NanUI for Winform发布,让Winform界面设计拥有无 ...
- 第一章 C++简介
第一章 C++简介 1.1 C++特点 C++融合了3种不同的编程方式:C语言代表的过程性语言,C++在C语言基础上添加的类代表的面向对象语言,C++模板支持的泛型编程. 1.2 C语言及其编程 ...
- Windows Phone开发(43):推送通知第一集——Toast推送
原文:Windows Phone开发(43):推送通知第一集--Toast推送 好像有好几天没更新了,抱歉抱歉,最近"光荣"地失业,先是忙于寻找新去处,唉,暂时没有下文.而后又有一 ...
随机推荐
- hadoop常见问题收集
hadoop 搭建 常用命令记录 快捷键安装在/user/local/bin目录下 nano 文件名 ctrl + k 剪切一行 ctrl + o 保存并重命名,不重命名直接enter ctrl + ...
- 创建线程的三种方式(Thread、Runnable、Callable)
方式一:继承Thread类实现多线程: 1. 在Java中负责实现线程功能的类是java.lang.Thread 类. 2. 可以通过创建 Thread的实例来创建新的线程. 3. 每个线程都是通过某 ...
- C++语法笔记(上)
客观事物中任何一个事物都可以看成一个对象,对象是由一组属性和一组行为构成的. c++中,每个对象都是由数据与函数这两部分构成,数据就是对象的属性,函数就是对象的行为. c++中对象的类型称为类,类是一 ...
- Python29之字符str与字节bytes
详解见这位大神:https://www.cnblogs.com/xiaobingqianrui/p/9870480.html 实际上字符串和字节之间的转换过程,就是编码解码的过程,我们必须显示的指定编 ...
- The Preliminary Contest for ICPC Asia Xuzhou 2019 E XKC's basketball team [单调栈上二分]
也许更好的阅读体验 \(\mathcal{Description}\) 给n个数,与一个数m,求\(a_i\)右边最后一个至少比\(a_i\)大\(m\)的数与这个数之间有多少个数 \(2\leq n ...
- GoAccess 视图化access.log 日志
1.安装GoAccess 工具可以直接使用 apt-get install goaccess 2.使用goaccess命令将日志生成html文件 goaccess 日志路径 -o 输出HTML的路径 ...
- Linux查找文件之Find命令
Linux系统文件中常用属性包括以下内容:名称,大小,权限,属主,属组,修改时间,访问时间等.在庞大的Linux系统中查询文件,需要借助查找工具来实现,依此可以查询相同或指定属性的文件,本文所讲的查询 ...
- English-培训1-Phonetic symbols
- 2019年6月车型数据Access数据库+缩略图 更新于2019年6月5日.
工作需要才来采集的, 数据来源某卡汽车网, 分享出来给需要的人吧, 本着分享的精神, 我就不猥琐的放到csdn下载了 本来是sql server的, 我导出到access了, 也方便大家查看. 顺手抓 ...
- CI,CD理解
一.什么是CI,CD 当我们在谈论现代的软件编译和发布流程的时候,经常会听到CI 和CD这样的缩写短语.CI很容易理解,就是持续集成. 但是CD既可以指代码持续交付,也可理解为代码持续部署.C ...