大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce
你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃。
MapReduce方法则是:
1.给在座的所有玩家中分配这摞牌
2.让每个玩家数自己手中的牌有几张是黑桃,几张是红桃,然后把这两组数目汇报给你
3.你把所有玩家告诉你的两组数字分别加起来,得到最后的结论
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题. MapReduce是分布式运行的,由两个阶段组成:Map和Reduce,Map阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。Reduce阶段是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据【在这先把reduce理解为一个单独的聚合程序即可】。
MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参和返回值都是<key、value>,使用的时候一定要注意构造<k,v>。
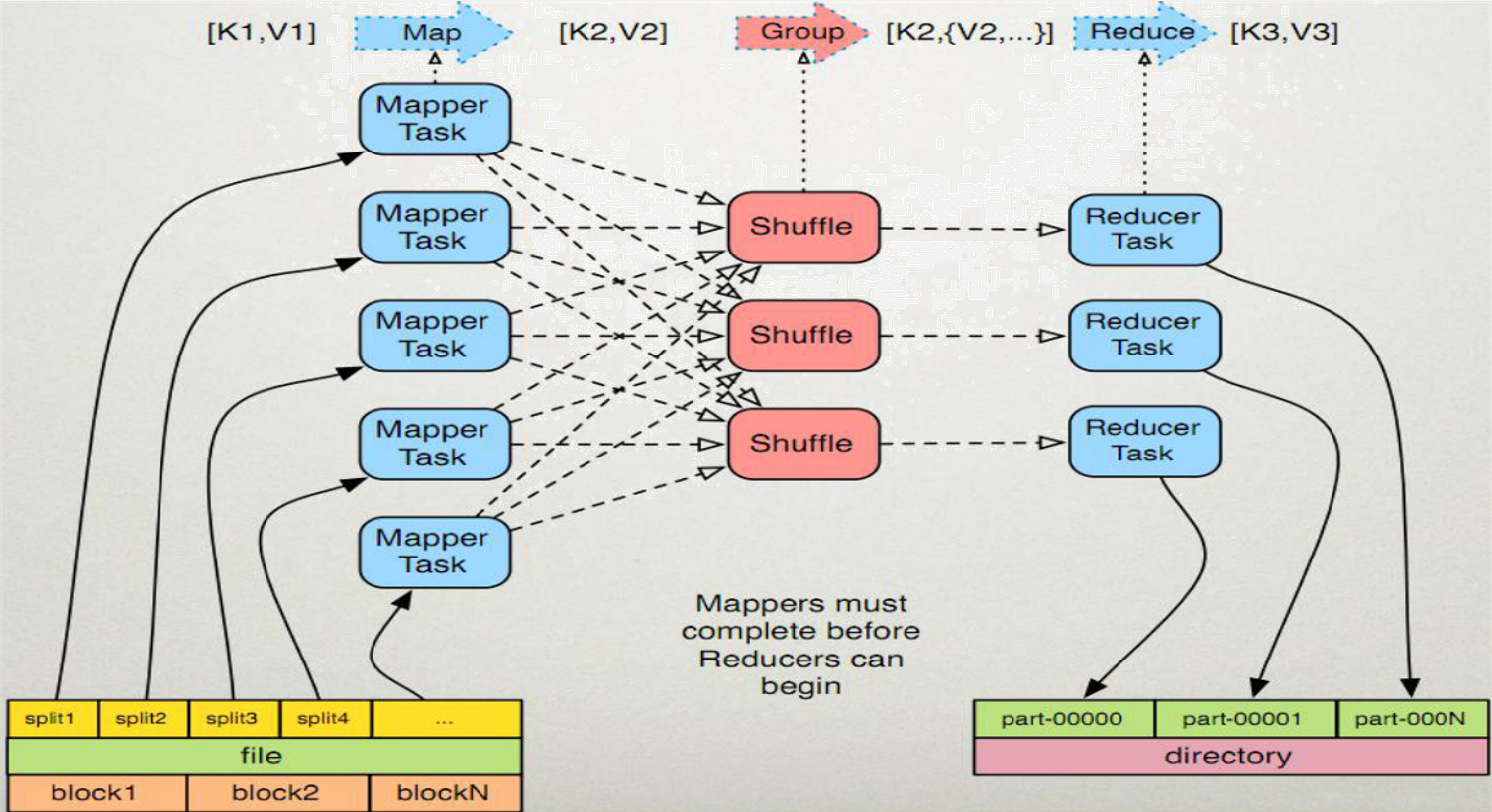
MapReduce原理
MapReduce执行过程----Map阶段
map任务处理
1.1 框架使用InputFormat类的子类把输入文件(夹)划分为很多InputSplit,默认,每个HDFS的block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个<k1,v1>。默认,框架对每个InputSplit中的每一行,解析成一个<k1,v1>。
1.2 框架调用Mapper类中的map(...)函数,map函数的形参是<k1,v1>对,输出是<k2,v2>对。一个InputSplit对应一个map task。程序员可以覆盖map函数,实现自己的逻辑。
1.3
(假设reduce存在)框架对map输出的<k2,v2>进行分区。不同的分区中的<k2,v2>由不同的reduce task处理。默认只有1个分区。
(假设reduce不存在)框架对map结果直接输出到HDFS中。
1.4 (假设reduce存在)框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。注意:分组不会减少<k2,v2>数量。
1.5 (假设reduce存在,可选)在map节点,框架可以执行reduce归约。
1.6 (假设reduce存在)框架会对map task输出的<k2,v2>写入到linux 的磁盘文件中。 至此,整个map阶段结束
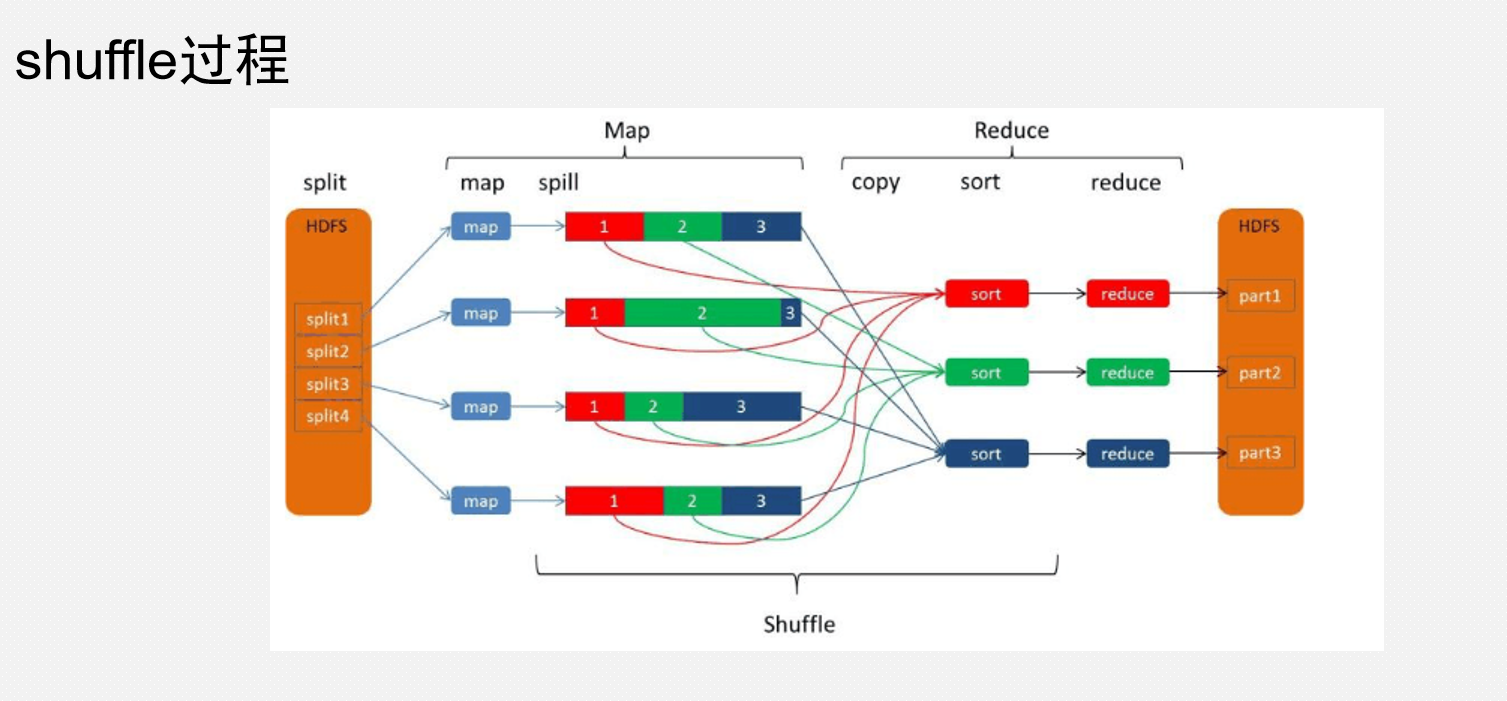
Shuffle过程(Reduce拉取数据的过程)
1.每个map有一个环形内存缓冲区,用于存储map的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容溢写到(spill)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。
2.写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
3.等最后记录写完,合并全部文件为一个分区且排序的文件。 =========================================================
1.Reducer通过Http方式得到输出文件的特定分区的数据。
2.排序阶段合并map输出。然后走Reduce阶段。
3.reduce执行完之后,写入到HDFS中。
MapReduce执行过程----Reduce阶段
reduce任务处理
2.1 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle。
2.2 框架对reduce端接收的[map任务输出的]相同分区的<k2,v2>数据进行合并、排序、分组。
2.3 框架调用Reducer类中的reduce方法,reduce方法的形参是<k2,{v2...}>,输出是<k3,v3>。一个<k2,{v2...}>调用一次reduce函数。程序员可以覆盖reduce函数,实现自己的逻辑。
2.4 框架把reduce的输出保存到HDFS中。
至此,整个reduce阶段结束。 例子:实现WordCountApp
MapReduce默认处理类
InputFormat
抽象类,只是定义了两个方法。
FileInputFormat
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,
FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
TextInputFormat
是默认的处理类,处理普通文本文件
文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value
默认以\n或回车键作为一行记录
RecordReader
每一个InputSplit都有一个RecordReader,作用是把InputSplit中的数据解析成Record,即<k1,v1>。
在TextInputFormat中的RecordReader是LineRecordReader,每一行解析成一个<k1,v1>。其中,k1表示偏移量,v1表示行文本内容
InputSplit
在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入。
当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,会有大量的map task运行,导致效率底下
例如:一个1G的文件,会被划分成8个128MB的split,并分配8个map任务处理,而10000个100kb的文件会被10000个map任务处理
Map任务的数量
一个InputSplit对应一个Map task
InputSplit的大小是由Math.max(minSize, Math.min(maxSize,blockSize))决定
单节点建议运行10—100个map task
map task执行时长不建议低于1分钟,否则效率低
特殊:一个输入文件大小为140M,会有几个map task?
FileInputFormat类中的getSplits
输入类-FileInputFormat源码分析:
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
什么是序列化,为什么要序列化
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。 当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
说的再直接点,序列化的目的就是为了跨进程传递格式化数据
map-Reduce键值对格式
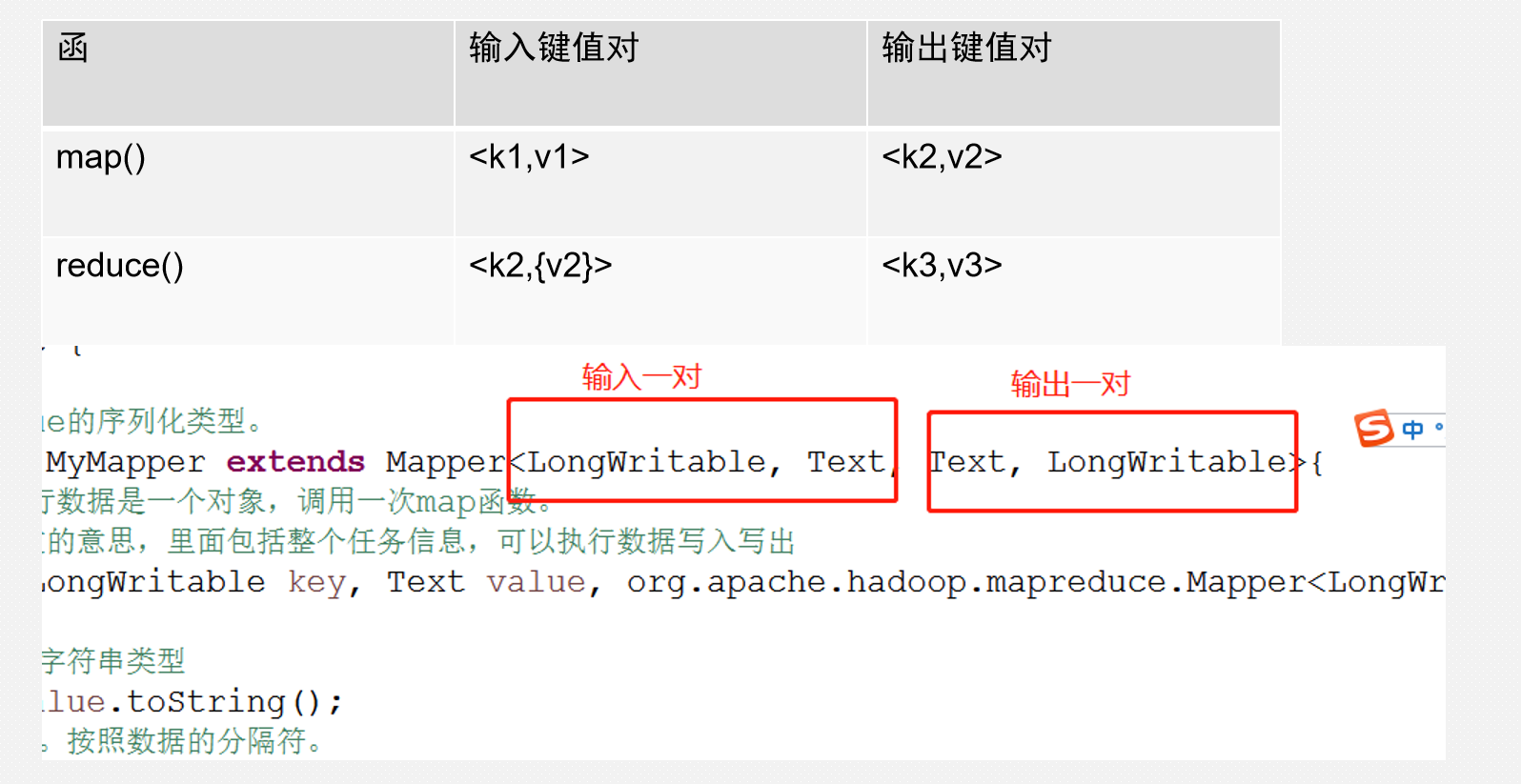
常用的数据类型在Hadoop中
补充一个,字符串类型是 Text
编写WordCount程序
该程序在大数据道路上就相当于学习Java时的 HelloWorld!!!!!!!!!!!
package com.wyh.shujia006; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 创建时间:2019年12月17日 下午3:14:11 * 项目名称:shujia006 * @author WYH * @version 1.0 * @since JDK 1.8.0 * 文件名称:WordCount.java * 类说明: */ public class WordCount {
//创建内部类 MyMap
public static class MyMap extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable K1, Text V1,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String s1 = V1.toString();
String[] words = s1.split(",");
for(String word1 : words){
Text word = new Text(word1);
context.write(word, new LongWritable(1l));
}
}
} //创建内部类MyReduce
public static class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text K2, Iterable<LongWritable> V2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
Long sum = 0l;
for(LongWritable V2 : V2s){
sum += V2.get();
}
context.write(K2, new LongWritable(sum));
}
} //主体函数
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//加载hadoop的配置参数
Configuration conf = new Configuration();
//创建任务的对象
Job job = Job.getInstance(conf, WordCount.class.getSimpleName());
//=========================================================================
//设置打包的类
job.setJarByClass(WordCount.class);
//=========================================================================
//设置读取文件的hdfs路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//=========================================================================
//指定需要执行的map类
job.setMapperClass(MyMap.class);
//指定map输出的序列化类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//=========================================================================
//指定需要执行的reduce类
job.setReducerClass(MyReduce.class);
//指定reduce的序列化类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//=========================================================================
//指定输出的hdfs路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//=========================================================================
//提交任务,等待执行完成,并打印执行日志
job.waitForCompletion(true); } }
1、编写号之后,我们右击这个程序导出jar包
2、将jar包上传到Linux中

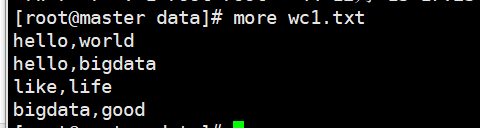
3、编写测试程序上传到HDFS中,我这里写的程序是以逗号分割的,可以更改。 上传命令是 hadoop fs -put 你要上传的文件路径 HDFS上的路径
4、编写命令进行测试

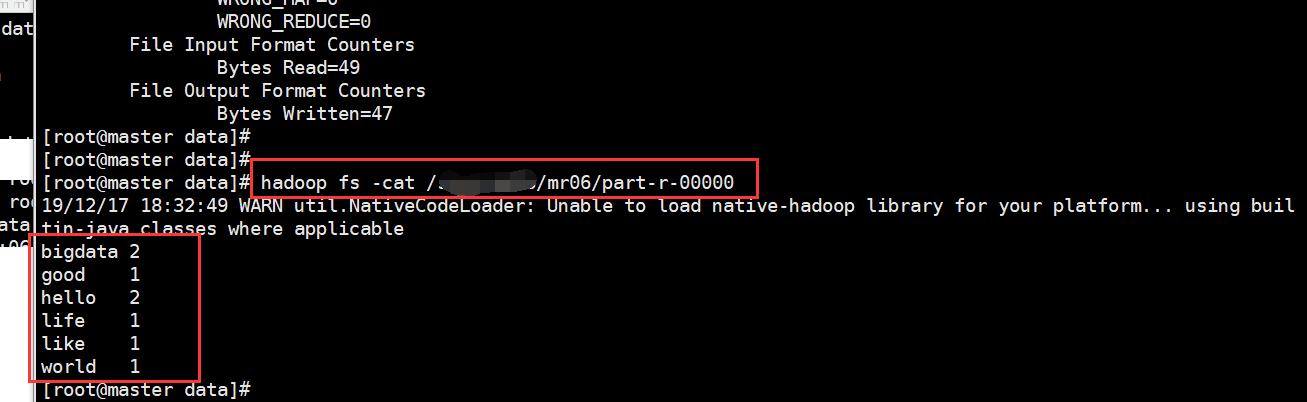
5、查看结果
改进扩展:将员工数据拿出来,每个岗位的工资进行倒叙排序
1、编写代码
package com.wyh.shujia006; import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 创建时间:2019年12月17日 下午7:42:54 * 项目名称:shujia006 * @author WYH * @version 1.0 * @since JDK 1.8.0 * 文件名称:test.java * 类说明: */ public class test {
public static class empMap extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable k1, Text v1,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String line = v1.toString();
String[] split = line.split(",");
Text job = new Text(split[2]);
LongWritable sal = new LongWritable(Long.parseLong(split[5]));
context.write(job, sal);
}
} public static class empReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException { ArrayList<Long> arrays = new ArrayList<Long>();
for(LongWritable sal : v2s){
arrays.add(sal.get());
}
//倒序(从大到小)
Object[] array = arrays.toArray();
Arrays.sort(array);
for(int x = array.length-1;x>=0;x--){
Long salss = (Long)array[x];
context.write(k2, new LongWritable(salss));
}
//顺序(从小到大)
/*for(Object sals : array){
Long salss = (Long)sals;
context.write(k2, new LongWritable(salss));
}*/
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, test.class.getSimpleName()); job.setJarByClass(test.class);
FileInputFormat.addInputPath(job, new Path(args[0])); job.setMapperClass(empMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class); job.setReducerClass(empReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true); } 96 }
(忽略了打包上传过程同上)
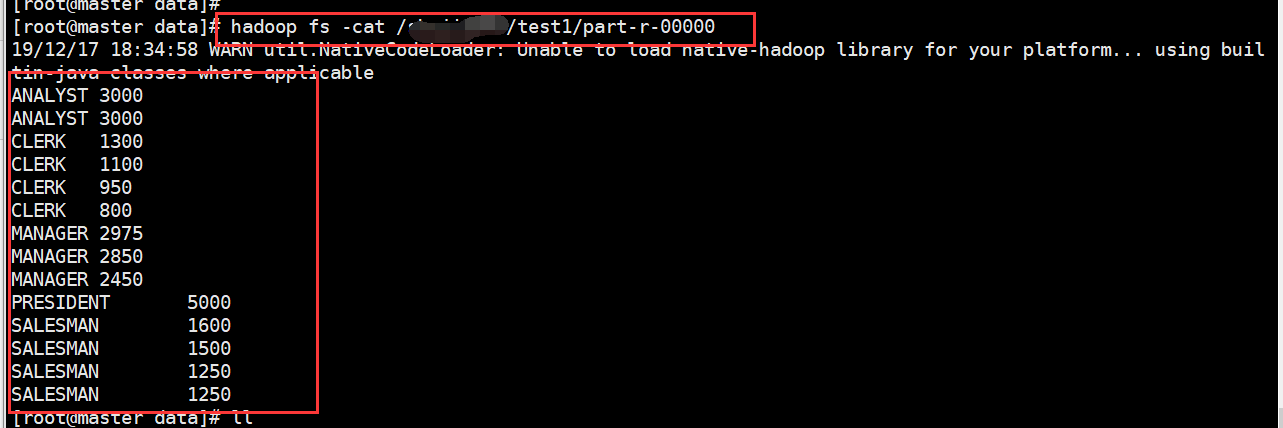
2、进行测试
大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)的更多相关文章
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week06--day07(Hadoop常用命令)
一.前述 分享一篇hadoop的常用命令的总结,将常用的Hadoop命令总结如下. 二.具体 1.启动hadoop所有进程start-all.sh等价于start-dfs.sh + start-yar ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
随机推荐
- nnexus3 破解密码
主要步骤如下: 1.停服 2.进入OrientDB控制台:java -jar /usr/local/nexus/lib/support/nexus-orient-console.jar 3.在控制台执 ...
- Django的小记
大致按流程列出来 在pycham中创建Django project时要确定机器上的版本及你要用的版本,机器上一般情况下默认最新版本2.1(2018年11月),根据需要下载相应版本 创建好工程后就要创建 ...
- springboot的mapper.xml在src下问题
在pom.xml里面的build标签加上resources说明 <resources> <!-- mapper.xml文件在java目录下 --> <resource&g ...
- 一个unsigned int 数的二进制表示中有多少个1
这是一道面试题可以用以下的一些方案.第一种是很容易想到的采用循环的方式并且与1进行位与运算,具体代码如下. 1unsigned int GetBitNumOfOne_ByLoop1(unsigned ...
- layer.prompt添加多个输入框
原文链接:https://www.jianshu.com/p/65fea33e6750 我们都知道layer.prompt官网上的例子是一个弹出框,那么有没有可能出来多个呢,当然是可以的 1.首先增加 ...
- 兔子问题(Rabbit problem)
Description 有一种兔子,出生后一个月就可以长大,然后再过一个月一对长大的兔子就可以生育一对小兔子且以后每个月都能生育一对.现在,我们有一对刚出生的这种兔子,那么,n 个月过后,我们会有多少 ...
- TCP/IP学习笔记7--TCP/IP模型通信例子学习
"一位如蝴蝶般美丽的女子向我飞来,翩翩的舞姿如同云端轻盈的叶儿." -------------------------------------------------------- ...
- DCEP究竟是什么?
DCEP (Digital Currency Electronic Payment) 数字货币电子支付工具 DCEP将由中国人民银行推出,推出时间待定. DCEP是使用区块链技术的一种联盟链,为全新的 ...
- (三)Spring Boot 官网文档学习之默认配置
文章目录 继承 `spring-boot-starter-parent` 覆盖默认配置 启动器 原文地址:https://docs.spring.io/spring-boot/docs/2.1.3.R ...
- Visual Studio Code 中实现 C++ 函数定义跳转和代码自动补全功能(25)
方法1: 1.1 安装插件 C++ Intellisense 名称: C++ Intellisense id: austin.code-gnu-global 说明: C/C++ Intellisens ...