[Spark News] Spark + GPU are the next generation technology
一、资源:Spark进行机器学习,支持GPU
From:https://my.oschina.net/u/2306127/blog/1602291
为了使用Spark进行机器学习,支持GPU是必须的,上层再运行神经网络引擎。
目前AWS\GCP和Databricks的云都已经支持GPU的机器学习,AliYun也在实验之中。
这包括几个层次:
- GPU直接支持Spark。因为Spark是多线程的,而GPU往往只能起一个单例,导致线程会竞争GPU资源,需要进行管理、加锁和调度。方法包括:
- 原生代码内置编译支持。
- 引入cuDNN等NVidia库进行调用。
- 通过Tensorflow等间接进行支持。
- JIT方式即时编译调用方式支持。
- GPU支持的Docker中运行Spark。如果将Spark节点放入Docker容器中运行,则需要使用NVidia提供的特殊版本Docker,而且需要安装NVidai提供的cuDNN等软件支持库。由于这些库调用了系统驱动,而且是C++编写,因此Spark要能够进行系统库的调用。
- GPU支持的Kubernetes之上运行Spark。
- 在上面的基础上,支持GPU的Docker容器需要能够接受Kubernetes的管理和调度。
- 参考:https://my.oschina.net/u/2306127/blog/1808304
只有同时满足上面的条件,才能通过Kubernetes的集群管理对Docker中Spark进行GPU操作。
下面是已经做的一些研究。
- IBMSparkGPU 的方案可以将GPU用于RDD和DataFrame,支持通用计算,重点支持机器学习;
- deeplearning4j 是基于Java的,包含数值计算和神经网络,支持GPU;
- NUMBA 的方案通过PySpark即时编译产生GPU的调用代码,兼容性好;
- Tensorflow/Caffe/MXNet等与Spark整合主要是节点调度,GPU由深度学习引擎调度,RDD需要数据交换,主要用于存储中间超参数数据。如TensorFrame的实现-https://github.com/databricks/tensorframes
Reference
- https://github.com/databricks/spark-deep-learning,Deep Learning Pipelines for Apache Spark,直接支持Images的一些功能。
- http://www.spark.tc/simd-and-gpu/, Spark多种支持GPU方法。
- http://www.spark.tc/gpu-acceleration-on-apache-spark-2/,GPU扩展
- https://my.oschina.net/u/2306127/blog/1602295,同上。
- http://www.spark.tc/0-to-life-changing-app-new-apache-systemml-api-on-spark-shell/,systemML在Spark中使用。
- Continuum-Anaconda,NUMBA: A PYTHON JIT COMPILER,http://on-demand.gputechconf.com/gtc/2016/presentation/s6413-stanley-seibert-apache-spark-python.pdf
- http://spark.tc/why-you-should-be-using-apache-systemml-2/,关于SystemML。
- 基于Java的神经网络深度学习系列库(支持GPU,https://deeplearning4j.org/),https://github.com/deeplearning4j
- https://github.com/IBMSparkGPU,源码:https://github.com/IBMSparkGPU/GPUEnabler
- Spark Summit 2016 Talk by Jun Feng Liu (IBM) and Yonggang Hu (IBM)
- Hadoop, Spark, Deep Learning Mesh on Single GPU Cluster,https://www.nextplatform.com/2016/02/24/hadoop-spark-deep-learning-mesh-on-single-gpu-cluster/
- IBM,关于GPU RDD的讨论,http://on-demand.gputechconf.com/gtc/2016/presentation/s6280-rajesh-bordawekar-accelerating-spark.pdf
- GPU Computing with Apache Spark and Python,http://on-demand.gputechconf.com/gtc/2016/presentation/s6413-stanley-seibert-apache-spark-python.pdf
- Spark ML Runs 10x Faster on GPUs, Databricks Says。https://www.datanami.com/2016/10/27/spark-ml-runs-faster-gpus/
二、在笔记本上实现Spark-GPU集群开发教程
From: https://www.jdon.com/bigdata/spark-gpu.html
第1部分:Spark-Notebook
选择Scala:完整的Spark API;GPU库允许我无需编写编译C代码而直接使用Java (这样从scala调用Java)。
Zeppelin -> buggy API
Spark-Notebook -> 导入依赖很头疼
Sparknotebook -> 就选择这个了,杀手级应用
下面是从Sparknotebook 仓储Clone下载一份,按照其指引操作,比如下载IScala.jar等等。
第2部分:在JVM上GPU
灵感来自于一个令人印象深刻的库包 ScalaNLP。 他们声称有一个解析器,可以在一台计算机上每分钟解析一百万字。
Aparapi出现的原因。 它编译Java代码到OpenCL,如果不能获得一个GPU则使用Java线程池运行。
第3部分:整合Spark和笔记本中Aparapi
真正的挑战是让这些工具相互调用。 集成的第一步,我们需要做的就是aparapi jar导入iscala笔记本。
第4部分:在笔记本(仅使用Scala)构建案例
第5部分:在Spark 集群执行GPU内核
下面是Spark运行在笔记本上的内核上示意图:
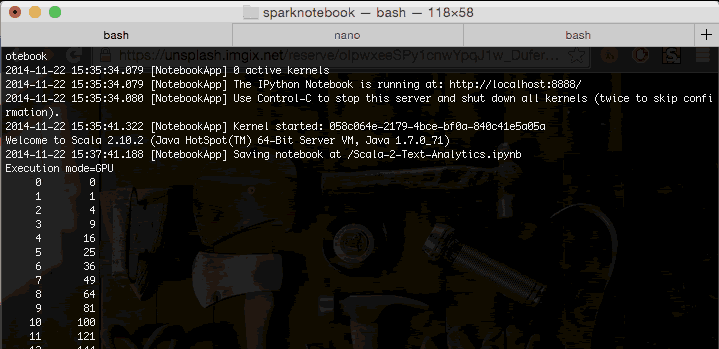
程序日志记录出现GPU…显示它确实是被运行在GPU。
但问题在于深度学习必须使用cuda,还是cuda才是正道。
/* implement */
[Spark News] Spark + GPU are the next generation technology的更多相关文章
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- 科普Spark,Spark核心是什么,如何使用Spark(1)
科普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html 阅读本文章可以带着下面问题:1.Spark基于 ...
- Spark之 spark简介、生态圈详解
来源:http://www.cnblogs.com/shishanyuan/p/4700615.html 1.简介 1.1 Spark简介Spark是加州大学伯克利分校AMP实验室(Algorithm ...
- 科普Spark,Spark是什么,如何使用Spark
科普Spark,Spark是什么,如何使用Spark 1.Spark基于什么算法的分布式计算(很简单) 2.Spark与MapReduce不同在什么地方 3.Spark为什么比Hadoop灵活 4.S ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
- Spark:使用Spark Shell的两个示例
Spark:使用Spark Shell的两个示例 Python 行数统计 ** 注意: **使用的是Hadoop的HDFS作为持久层,需要先配置Hadoop 命令行代码 # pyspark >& ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- [Spark][Python]spark 从 avro 文件获取 Dataframe 的例子
[Spark][Python]spark 从 avro 文件获取 Dataframe 的例子 从如下地址获取文件: https://github.com/databricks/spark-avro/r ...
- [Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子:
[Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子: mydf001=sqlContext.read.format("jdbc").o ...
随机推荐
- PAT Basic 1087 有多少不同的值 (20 分)
当自然数 n 依次取 1.2.3.…….N 时,算式 ⌊ 有多少个不同的值?(注:⌊ 为取整函数,表示不超过 x 的最大自然数,即 x 的整数部分.) 输入格式: 输入给出一个正整数 N(2). 输出 ...
- PAT Advanced 1152 Google Recruitment (20 分)
In July 2004, Google posted on a giant billboard along Highway 101 in Silicon Valley (shown in the p ...
- vue多层次组件监听动作和属性
v-bind="$attrs" v-on="$listeners" Vue 2.4 版本提供了这种方法,将父组件中不被认为 props特性绑定的属性传入子组件中 ...
- mysql基础_操作文件中的内容
1.插入数据: insert into t1(id,name) values(1,'alex'); #向t1表中插入id为1,name为'alex'的一条数据 2.删除: delete from t1 ...
- C# 动态语言扩展(11)
在 C# 4 开始添加 dynamic 类型.Mono C# 已经支持 C# 6.0 了. DLR C# 4 动态功能是 Dynamic Language Runtime (动态语言运行时,DLR)的 ...
- Create Advanced Web Applications With Object-Oriented Techniques
Create Advanced Web Applications With Object-Oriented Techniques Ray Djajadinata Recently I intervie ...
- Java中的集合HashSet、LinkedHashSet、TreeSet和EnumSet(二)
Set接口 前面已经简绍过Set集合,它类似于一个罐子,一旦把对象'丢进'Set集合,集合里多个对象之间没有明显的顺序.Set集合于Collection基本上完全一样,它没有提供任何额外的方法. Se ...
- WINCE7 SYMBOL MC32N0 SDK,VS2008调试程序,连接设备时,出现bootstrap 未能加载时
开发工具:visual studio 2008 手持设备: SYMBOL MC32NO工具->连接到设备->WINCE 7.00连接设备出现bootstrap 未能加载时,试下安装Mot ...
- 读取根目录src下的指定配置properties文件内容
代码如下: package com.chen.system.util; import java.io.File; import java.io.FileInputStream; import java ...
- 爬虫代理池源代码测试-Python3WebSpider
元类属性的使用 来源: https://github.com/Python3WebSpider/ProxyPool/blob/master/proxypool/crawler.py 主要关于元类的使用 ...