Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制:
Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle
将maptask处理后的输出结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序
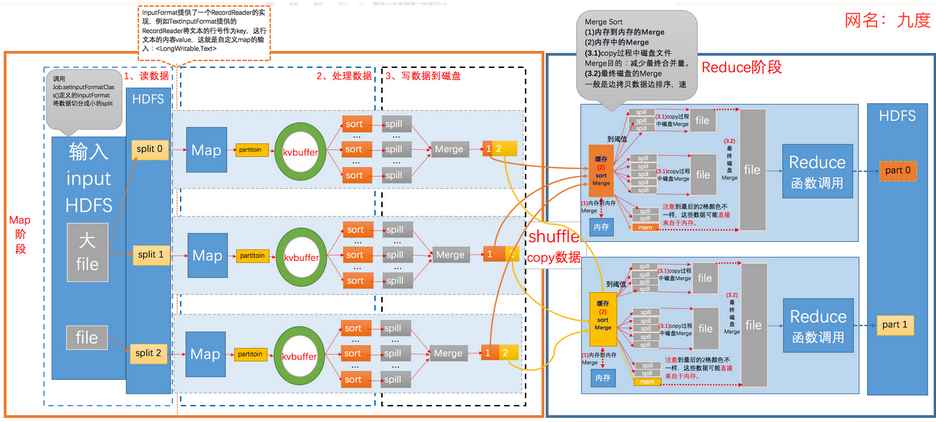
MapReduce程序的执行过程分为两个阶段:Mapper阶段和Reducer阶段。
1.MapReduce的Map阶段:
1.1.从HDFS读取数据:
由FileInputFormat实现类的getSplits()方法将待处理数据执行逻辑切片,默认切片的类为FileInputFormat,通过切片
输入文件将会变成split1、split2、split3……随后对输入切片split按照一定的规则解析成键值对<k1,v1>,在MapTask进行读取
数据时,其中默认处理的类为TextInputFormat,并通过记录读取器RecordReader的read()方法一次读取一行,并返回key和
value,其中k1就是读到的一行文本的起始偏移量,v1就是行文本的内容。
调用自己编写的Map逻辑,Maptask会对每一行<k1,v1>输入数据调用一次我们自定义的map()方法,
Map使用context.write输出键值对<k2,v2>,其输出结果由OutPutCollector将每个Map任务的键值对输出到内存所构造
的一个环形缓冲区中,其数据结构其实就是个字节数组,叫Kvbuffer,Mapper中的Kvbuffer的大小默认100M,spill一般会在
Buffer空间大小的80%开始进行spill溢出到文件,在溢出之前,按照一定的规则对输出的键值对<k2,v2>进行分区:分区的规
则是针对k2进行的,比如说k2如果是省份的话,那么就可以按照不同的省份进行分区,同一个省份的k2划分到一个区,注意:
默认分区的类是HashPartitioner类,这个类默认只分为一个区,因此Reducer任务的数量默认也是1.注意:如reduce要求得
到的是全局的结果,则不适合分区!然后再对每个分区中的键值对进行排序;注意:所谓排序是针对k2进行的,v2是不参与排
序的,如果要让v2也参与排序,需要自定义排序的类,此时得到的溢出文件分区且区内有序;不断溢出,不断形成溢出文件;
在MapTask结束前会对这些spill溢出文件进行归并排序Merge,形成MapTask的最终结果文件
注:Combiner存在的时候,此时会根据Combiner定义的函数对map的结果进行合并
由于job的每一个map都会根据reduce(n)数将数据输出结果分成n个partition,hadoop中是等job的第一个map结束后,
所有的reduce就开始尝试从完成的map中下载该reduce对应的partition部分数据(网络传输)到ReduceTask的本地磁盘工作
目录,当所有map输出都拷贝完毕之后,所有数据被最后合并成一个整体有序的文件,作为reduce任务的输入,Reducetask
真正进入reduce函数的计算阶段
Reduce在这个阶段,框架为已分组的输入数据中的每个 <key, (list of values)>对调用一次 reduce()方法。Reduce
任务的输出通常是通过调用 OutputCollector.collect(WritableComparable,Writable)写入文件系统
注意:Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速
度就越快缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
2.Mapreduce中的Combiner:
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1、 自定义一个combiner继承Reducer,重写reduce方法
2、 在job中设置: job.setCombinerClass(CustomCombiner.class)
(5) combiner能够应用的前提是不能影响最终的业务逻辑而且,combiner的输出kv应该跟reducer的输入kv类型要
对应起来
Combiner的使用要非常谨慎因为combiner在mapreduce过程中可能调用也肯能不调用,可能调一次也可能调多次所以:
combiner使用的原则是:有或没有都不能影响业务逻辑
参考文章:https://blog.csdn.net/aijiudu/article/details/72353510
Hadoop_18_MapRduce 内部的shuffle机制的更多相关文章
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Shuffle 机制
1. 概述 Map 方法之后,Reduce 方法之前的数据处理过程称之为 Shuffle. 2. Partition 分区 需求:要求将统计结果按照条件输出到不同文件中(分区).比如:将统计结果按照手 ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
- Qt 的内部进程通信机制
Qt 的内部进程通信机制 续欣 (xxin76@hotmail.com), 博士.大学讲师 2004 年 4 月 01 日 Qt 作为一种跨平台的基于 C++ 的 GUI 系统,能够提供给用户构造图形 ...
- AsnycTask的内部的实现机制
AsnycTask的内部的实现机制 写在前面 我们为什么要用AsnycTask. 在Android程序开始运行的时候会单独启动一个进程,默认情况下所有 这个程序操作都在这个进程中进行.一个Androi ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Spark Shuffle机制详细源码解析
Shuffle过程主要分为Shuffle write和Shuffle read两个阶段,2.0版本之后hash shuffle被删除,只保留sort shuffle,下面结合代码分析: 1.Shuff ...
随机推荐
- 【ARTS】01_23_左耳听风-201900415~2019004021
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- 如何将Nginx注册为系统服务,开机自启动
亲测有效! 一般程序员在实际工作中,除了敲代码,很少有机会实际接触操作其它东西,例如服务器环境搭建,项目部署等等,不是领导信任或项目组核心成员,应该是没有机会实际接触的,只能通过网上资料稍微了解一下. ...
- 【VS开发】IPicture在指定窗口绘制图
1.利用IPicture接口加载.显示图片 IPicture接口管理一个图片对象和它的属性.图片对象提供对Bitmap Icon Metafile的语言不相关的抽象支持.图像对象的主要接口是IPict ...
- [Agc029D]Grid game_贪心
Grid game 题目链接:https://atcoder.jp/contests/agc029/tasks/agc029_d 数据范围:略. 题解: 方法肯定很简单,就是找一处障碍待在他上面就好. ...
- 测试sigaction重启动标识
#include <stdio.h>#include <unistd.h>#include <signal.h>#include <string.h># ...
- HTTPS 简单学习
1. HTTP缺点 使用明文通信,内容可能会被窃听: 通信加密:使用SSL和TLS: 内容加密: 不验证通信方的身份,因此可能会遭到伪装: SSL提供加密和证书: 无法证明报文的完整性,因此会遭到修改 ...
- RabbitMQ 幂等性概念及业界主流解决方案
RabbitMQ 幂等性概念及业界主流解决方案 2019年01月24日 15:57:03 JAVA@架构 阅读数:506 一.什么是幂等性 可以参考数据库乐观锁机制,比如执行一条更新库存的 SQL ...
- 剑指offer46:圆圈中最后剩下的数字(链表,递归)
1 题目描述 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈.然后,他随 ...
- 【Python】**kwargs和takes 1 positional argument but 2 were given
Python的函数定义中可以在参数里添加**kwargs——简单来说目的是允许添加不定参数名称的参数,并作为字典传递参数.但前提是——你必须提供参数名. 例如下述情况: class C(): def ...
- 笔记-2:python基本数据类型
1.数字类型 1.1 整数类型 整数类型有4种进制表示:十进制,二进制,八进制,十六进制,默认情况下,整数采用十进制. 整数类型有4种进制:十进制. 二进制. 八进制和十六进制. 默认情况, 整数采用 ...