python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法。这里介绍下使用scrapy如何实现自动登录。还是以csdn网站为例。
Scrapy使用FormRequest来登录并递交数据给服务器。只是带有额外的formdata参数用来传送登录的表单信息(用户名和密码),为了使用这个类,需要使用以下语句导入:from scrapy.http import FormRequest
那么关于登录过程中使用cookie值,scrapy会自动为我们处理cookie,只要我们登录成功了,它就会像一个浏览器一样自动传送cookie
首先爬虫中定义start_requests
def start_requests(self):
return [Request("http://passport.csdn.net/account/login",meta={'cookiejar':1},callback=self.post_login,method="POST")]
其中采用Requests的方法首先访问登录网站。meta属性是字典,字典格式即{‘key’:'value'},字典是一种可变容器模型,可存储任意类型对象。
request中meta参数的作用是传递信息给下一个函数,这些信息可以是任意类型的,比如值、字符串、列表、字典......方法是把要传递的信息赋值给meta字典的键. 上面start_requests中键‘cookiejar’是一个特殊的键,scrapy在meta中见到此键后,会自动将cookie传递到要callback的函数中。既然是键(key),就需要有值(value)与之对应,例子中给了数字1,也可以是其他值,比如任意一个字符串。
Callback就是连接到了登录网站后下一步需要调的函数。下面来看下post_login如何实现
def post_login(self,response):
html=BeautifulSoup(response.text,"html.parser")
for input in html.find_all('input'):
if 'name' in input.attrs and input.attrs['name'] == 'lt':
lt=input.attrs['value']
if 'name' in input.attrs and input.attrs['name'] == 'execution':
e1=input.attrs['value']
data={'username':'xxxx','password':'xxxxx','lt':lt,'execution':e1,'_eventId':'submit'}
return [FormRequest.from_response(response,
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.after_login,)]
首先是获取lt,execution字段的值,具体在之前介绍requests的帖子中有解释。
然后调用FormRequest.from_response。 这个方法的作用是从response中返回的网页中构造表单数据,因此第一个参数是response。这里response返回的网页也就是前面Requests中调用的http://passport.csdn.net/account/login
接下来的参数是meta。Heasers,formadata以及callback。这里的callback有就是指向登录后的函数。
after_login的实现如下。
def after_login(self,response):
print 'after login'
print response.status
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36'}
return [Request("http://my.csdn.net/my/mycsdn",meta={'cookiejar':response.meta['cookiejar']},headers=header,callback=self.parse)]
def parse(self, response):
print response.text.decode('utf-8').encode(self.type)
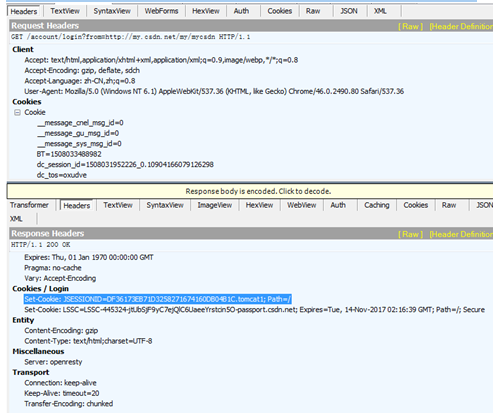
运行后我们来看下记录的log。从下面的红色标红部分可以看到。在向http://passport.csdn.net/account/login发起登录请求后,scrapy紧接着
向http://passport.csdn.net/account/login;jsessionid=8B4A62EA09BBB5F1FBF4D921B64FECE6.tomcat2 发起建立请求。这也就是调用FormRequest.from_response触发的。在这里后面连接的jsessionid值也就是之前在访问登录网站的时候获取的会话ID,在这里scrapy自动给添加上了
2017-10-16 22:17:34 [scrapy] INFO: Spider opened
2017-10-16 22:17:34 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-10-16 22:17:34 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-10-16 22:17:34 [scrapy] DEBUG: Crawled (404) <GET http://passport.csdn.net/robots.txt> (referer: None)
2017-10-16 22:17:34 [scrapy] DEBUG: Crawled (200) <POST http://passport.csdn.net/account/login> (referer: None)
2017-10-16 22:17:34 [scrapy] DEBUG: Crawled (200) <POST http://passport.csdn.net/account/login;jsessionid=8B4A62EA09BBB5F1FBF4D921B64FECE6.tomcat2> (referer: http://www.csdn.net/)
2017-10-16 22:17:35 [scrapy] DEBUG: Crawled (200) <GET http://my.csdn.net/robots.txt> (referer: None)
2017-10-16 22:17:35 [scrapy] DEBUG: Crawled (200) <GET http://my.csdn.net/my/mycsdn> (referer: http://passport.csdn.net/account/login;jsessionid=8B4A62EA09BBB5F1FBF4D921B64FECE6.tomcat2)
2017-10-16 22:17:35 [scrapy] INFO: Closing spider (finished)
2017-10-16 22:17:35 [scrapy] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 2022,
从fiddler中抓取的数据可以看到jsessionid是在访问登录网站后,网站返回的response 消息的header消息中。也就是网站设置的cookie值
完整的代码:
# -*- coding:UTF-8 -*- #
from scrapy.spiders import Spider,CrawlSpider,Rule
from scrapy.selector import Selector
from scrapy.http import Request
from scrapy import FormRequest from test2.items import Test2Item
from scrapy.utils.response import open_in_browser
from scrapy.linkextractors import LinkExtractor
from bs4 import BeautifulSoup
import sys class testSpider(Spider):
name="test2"
allowd_domains=['http://www.csdn.net/']
header={'host':'passport.csdn.net','User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36','Referer':'http://www.csdn.net/'}
start_urls=["http://www.csdn.net/"]
reload(sys)
sys.setdefaultencoding('utf-8')
type = sys.getfilesystemencoding()
def start_requests(self): return [Request("http://passport.csdn.net/account/login",meta={'cookiejar':1},callback=self.post_login,method="POST")] def post_login(self,response):
html=BeautifulSoup(response.text,"html.parser")
for input in html.find_all('input'):
if 'name' in input.attrs and input.attrs['name'] == 'lt':
lt=input.attrs['value']
if 'name' in input.attrs and input.attrs['name'] == 'execution':
e1=input.attrs['value']
data={'username':'xxxx','password':'xxxxx','lt':lt,'execution':e1,'_eventId':'submit'}
return [FormRequest.from_response(response,
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.after_login,)]
def after_login(self,response):
print 'after login'
print response.status
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36'}
return [Request("http://my.csdn.net/my/mycsdn",meta={'cookiejar':response.meta['cookiejar']},headers=header,callback=self.parse)]
def parse(self, response):
print response.text.decode('utf-8').encode(self.type)
python网络爬虫之使用scrapy自动登录网站的更多相关文章
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- 【python 网络爬虫】之scrapy系列
网络爬虫之scripy系列 [scrapy网络爬虫]之0 爬虫与反扒 [scrapy网络爬虫]之一 scrapy框架简介和基础应用 [scrapy网络爬虫]之二 持久化操作 [scrapy网络爬虫]之 ...
- Python 网络爬虫 002 (入门) 爬取一个网站之前,要了解的知识
网站站点的背景调研 1. 检查 robots.txt 网站都会定义robots.txt 文件,这个文件就是给 网络爬虫 来了解爬取该网站时存在哪些限制.当然了,这个限制仅仅只是一个建议,你可以遵守,也 ...
- python网络爬虫之使用scrapy下载文件
前面介绍了ImagesPipeline用于下载图片,Scrapy还提供了FilesPipeline用与文件下载.和之前的ImagesPipeline一样,FilesPipeline使用时只需要通过it ...
- python网络爬虫之使用scrapy爬取图片
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片. 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- 《实战Python网络爬虫》- 感想
端午节假期过了,之前一直在做出行准备,后面旅游完又休息了一下,最近才恢复状态. 端午假期最后一天收到一个快递,回去打开,发现是微信抽奖中的一本书,黄永祥的<实战Python网络爬虫>. 去 ...
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
随机推荐
- Java中final和static关键字总结
1.final: final关键字可用于类.方法.变量前. final修饰的类不可被继承,例如java.lang.Math就是一个 final类,不可被继承. final修饰变量,在显示初始化后不可改 ...
- 转:ospf学习-----SPF最短路径算法
ospf学习-----SPF最短路径算法 常见的路由协议比如RIP.IGRP.BGP是距离矢量协议,OSPF和ISIS是数据链路状态协议.矢量协议路由器只知道本身和与自身相连的接口路由信息,矢量图只是 ...
- Jenkins强制设置语言为中文
解决方法如下: 1.使用中文版的google浏览器,并确定把语言设置成了中文.语言配置在设置页.如下: 2.直接设置jenkins的语言.强制性. 前提:先安装插件:Locale plugin 配置如 ...
- php数据库操作代码
数据库名为reg,表名为member,字段名为username,password,regdate <?php $link=@mysql_connect("localhost" ...
- SVN merge 三种方式
1.Merge a range of revisions 2.Reintegrate a branch 3.Merge two different trees ———————————————————— ...
- thinkphp5 中使用postgresql 缺少函数 table_msg
参考解决办法 在postgresql 中执行命令 插入函数 https://blog.csdn.net/sinat_35767703/article/details/76070236?utm_sour ...
- Python将JSON格式数据转换为SQL语句以便导入MySQL数据库
前文中我们把网络爬虫爬取的数据保存为JSON格式,但为了能够更方便地处理数据.我们希望把这些数据导入到MySQL数据库中.phpMyadmin能够把MySQL数据库中的数据导出为JSON格式文件,但却 ...
- MYSQL索引优化思维导图
有关索引的优化.MYSQL索引优化 文章来源:刘俊涛的博客 地址:http://www.cnblogs.com/lovebing
- C语言 结构体篇
结构体:是一种构造类型 它是由若干成员组成的 其中每一个成员都可以是一个基本数据类型或者又是一个构造类型 定义结构体变量后,系统就会为其自动分配内存 为了便于更大的程序便于修改和使用 常常将结构体类 ...
- apt-get update --> Bad header line (fresh install) Ign http://archive.ubuntu.com natty-security/multiverse Sources/DiffIndex W: Failed to fetch http://archive.ubuntu.com/ubuntu/dists/natty/Rele
apt-get update --> Bad header line (fresh install) fresh natty install i386 desktop. I get this e ...