【python爬虫】bilibili综合热门页面视频图片爬取
此博客仅作为交流学习
我用python来爬取bilibili综合热门页面视频图片
首先分析页面:
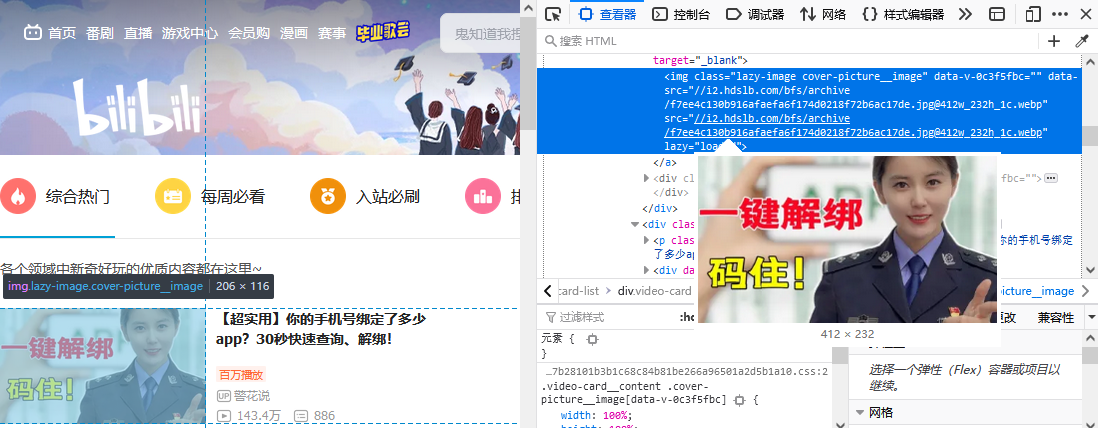
如上图所示,当我们想要在页面爬取图片时,往往得不到页面图片的地址,这时我们也得不到图片
开始抓包分析:
点击Network,CTRL+R开始抓包点击下面页面
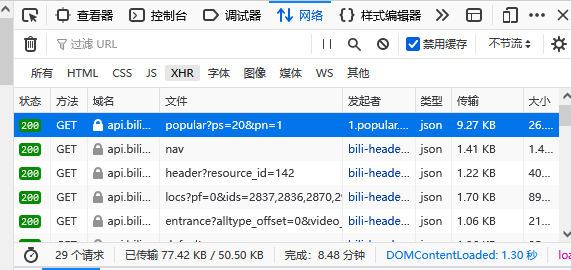
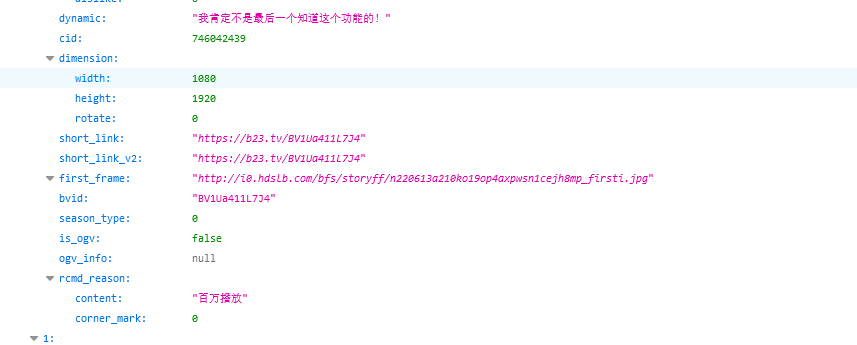
发现页面是json
那么,只要进入当前页面解析并提取页面信息便可以拿到图片地址,进而得到视频封面了
查看响应
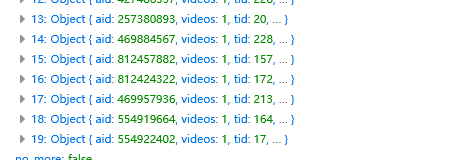
发现抓包得到的页面信息有限,只有热门页面的一部分
下拉页面发现

出现了当前页面又一信息链接
那么根据观察发现,只有不断下拉时,页面就会开始加载信息
根据抓包页面链接进行for循环解析页面提取数据并保存信息:
import requests
import pprint
import time for i in range(1,12):
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn=' + str(i)
response = requests.get(url=url)
data = response.json()
#pprint.pprint(data) #将页面内容规范为易懂可视页面
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
# print([pic,title]) imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
time.sleep(2)
效果:
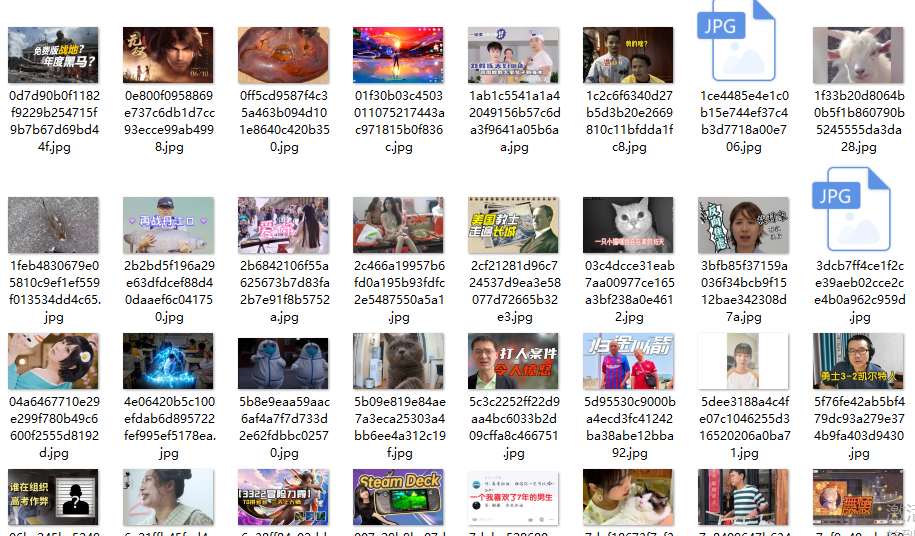
【python爬虫】bilibili综合热门页面视频图片爬取的更多相关文章
- Python爬虫入门教程:豆瓣Top电影爬取
基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一. ...
- python爬虫11 | 这次,将带你爬取b站上的NBA形象大使蔡徐坤和他的球友们
在上一篇中 python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!! 小帅b给大家透露了我们这篇要说的牛逼利器 selenium + phantomjs 如果你看了 python爬虫 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- Python爬虫与一汽项目【二】爬取中国东方电气集中采购平台
网站地址:https://srm.dongfang.com/bid_detail.screen 东方电气采购的页面看似很友好,实际上并不好爬取 在观察网页的审查元素之后发现,1处的网页响应只是单纯的一 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
随机推荐
- Windows 10 输入法(仅桌面) %100 解决
大家好,今天我遇到了一件非常难受的一件事,那就是 WIndows 自带的输入发问题,无法输入中文!!! 这时我去网上找找解决方案,总结了一下几个: 文件检查 步骤 以管理员身份运行PowerShell ...
- VSCODE C# 运行 找不到任务"BUILD"----C#常用命令
使用 Visual Studio Code 创建 .NET 类库 - .NET | Microsoft Docs 安装vscode.vscode c#相关拓展.MINIGW64 1.创建文件夹 2.用 ...
- Markdown操作方法
Markdown学习 标题 三级标题 四级标题 字体 原本 hello,world! 斜体 hello,world! 加粗 hello,world! 斜体加粗 hello,world! 删除 hell ...
- 一文快速回顾 Session 和 Cookie
前言 在 Web 应用程序中(通俗点,可以理解成一个网站),Session 和 Cookie 是两个非常重要的概念,主要用于实现用户身份认证.数据传递等功能.今天就来讲讲这两个东西. 对于当时刚开始接 ...
- windows2003 DHCP服务器配置
一.导入光驱 二.安装可选的windows组件 三.双击打开网路服务,安装DHCP/DNS服务器. 注:服务器地址要固定,因此安装时要规划好网络. 四.ip地址范围规划时要预留i出一些p地址.排除ip ...
- git clone的时候出现 fatal: unable to access 'https://github.com/...':OpenSSL SSL_read: Connection was reset, errno 10054解决方法
git clone的时候出现fatal: unable to access 'https://github.com/...':OpenSSL SSL_read: Connection was rese ...
- Asp-Net-Core开发笔记:使用RateLimit中间件实现接口限流
前言 最近一直在忙(2月份沉迷steam,3月开始工作各种忙),好久没更新博客了,不过也积累了一些,忙里偷闲记录一下. 这个需求是这样的,我之前做了个工单系统,现在要对登录.注册.发起工单这些功能做限 ...
- C#MD5加密的两种方式
在开发过程当中,我们经常会用到MD5加密,下面介绍MD5加密的两种方式: /// <summary> /// MD5字符串加密 /// </summary> /// <p ...
- ABAP 屏幕开发-仿采购订单
1.功能说明 本文档通过一个简单的实例,仿照采购订单的界面,介绍屏幕开发. 2.效果展示 3.功能实现 3.1界面框架 从界面上看,整个界面框架分为四部分.抬头行,抬头页签,行项目,项目细节.其中抬头 ...
- 64位的单周期 RISC-V 模拟器
分享一个我最近完成过的小项目--64位的单周期 RISC-V 模拟器,这个项目我最近参与一生一芯计划过程中完成的一个小项目. 需要用到的相关知识:Verilog.Verilator.计算机组成原理.汇 ...