【Hive】概念、安装、数据类型、DDL、DML操作、查询操作、函数、压缩存储、分区分桶、实战Top-N、调优(fetch抓取)、执行计划
一、概念
1、介绍
基于Hadoop的数据仓库工具,将结构化数据映射为一张表,可以通过类SQL方式查询
本质:将HQL转换成MapReduce程序
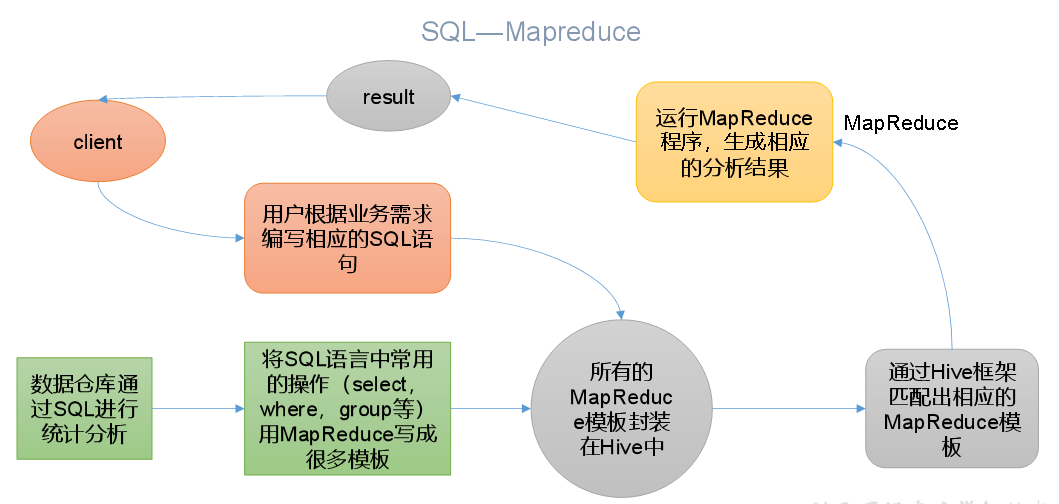
Hive中具有HQL对应的MapReduce模板
存在:HDFS,分析的底层是MapReduce,程序运行在yarn上
2、优缺点
HQL快速开发、适用于数据分析等实时性不高的场景、支持自定义函数、擅长大数据
表达能力有限、效率低、延迟性高
3、架构原理
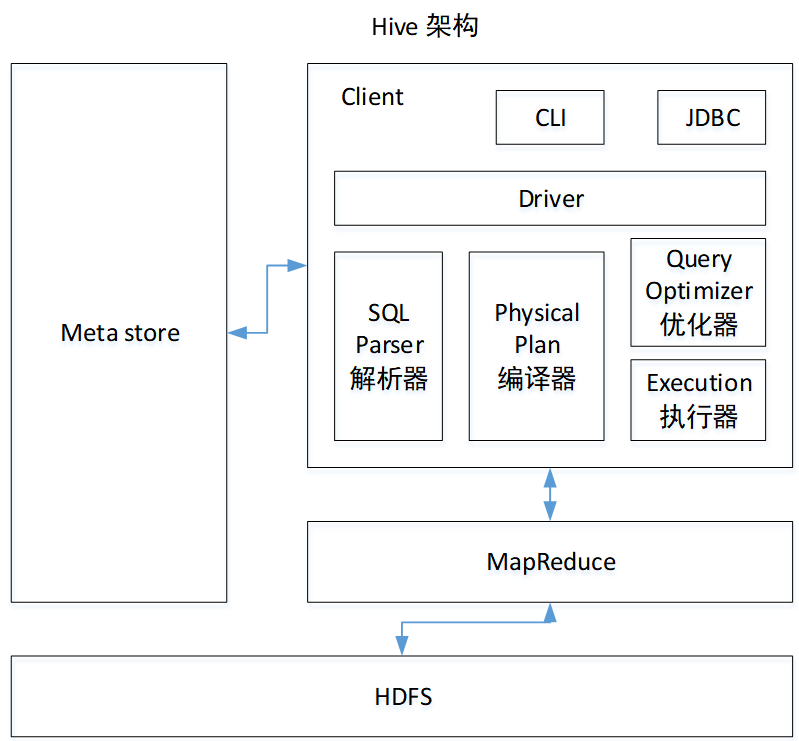
驱动器:解析器(SQL转为抽象语法树)、编译器(生成逻辑执行计划)、优化器、执行器(逻辑转为物理)
4、和数据库比较
数据更新(数据仓库)、执行延迟(无索引+MR的高延迟)、数据规模
二、Hive安装
1、Hive安装
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
2、MySQL的安装与配置
3、Hive安装部署:配置环境变量
4、元数据配置到MySQL:
拷贝MySQL驱动、配置Metastore到MySQL
5、安装Hive的Tez引擎
将多个有依赖的作业转换为一个作业,只需写一次HDFS,提高计算性能
6、启动Hive
初始化元数据库
启动metastore和hiveserver2
HiveJDBC访问
7、其他命令操作
退出、查看hdfs文件系统、查看输入的历史命令
8、常见属性配置
运行日志信息配置
参数配置(配置文件hive-site.xml、命令行参数bin/hive -hiveconf、参数声明SET)
三、Hive数据类型
1、基本数据类型
TINYINT
SMALINT
INT
BIGINT
BOOLEAN
FLOAT
DOUBLE
STRING
TIMESTAMP
BINARY--字节数组
2、集合数据类型
STRUCT--结构体,用.访问
MAP
ARRAY

3、类型转换
隐式类型转换、CAST('1' AS INT)显式类型转换
四、DDL数据定义
1、创建数据库,可以指定位置
create database db_hive2 location '/db_hive2.db';
2、查询数据库
显示、查看数据库及详情、切换当前数据库
3、修改数据库
属性、位置等
4、删除数据库
空数据库/cascade强制删除
5、创建表
(2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
5.1默认创建管理表(内部表),数据存储在hive.metastore.warehouse.dir
根据结果创建表:create table if not exists student3 as select id, name from student;
根据表结构创建表:create table if not exists student4 like student;
查询表的类型: desc formatted student2;
5.2 外部表
收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储
上传数据:dfs -put /opt/module/datas/student.txt /student;
建表语句+location '/student';
5.3 相互转换
alter table student2 set tblproperties('EXTERNAL'='TRUE');
6、修改表
增删改分区、增删改列信息
7、删除表
drop table dept_partition;
五、DML数据操作
1、数据导入
表中装载数据、通过查询语句插入数据、创建表及加载数据
通过Location指定加载数据路径
Import数据到指定Hive表中
2、数据导出
导出到本地/hdfs
Hive Shell 命令导出:bin/hive -e
导出到HDFS
Sqoop导出
清空数据truncate
六、查询
1、操作
limit限制行数
RLIKE子句使用正则表达式匹配条件
select * from emp where sal RLIKE '[2]';
2、分组
3、join语句
4、排序
分区排序(Distribute By)
Cluster By
5、抽样查询
select * from stu_buck tablesample(bucket 1 out of 4 on id);
七、函数
1、系统内置函数
显示用法:desc function upper;
2、常用内置函数
行转列concat、列转行EXPLODE
空字段赋值NVL( value,default_value)
case sex when '男' then 1 else 0 end
窗口函数(开窗函数):sum累加
RANK排序
日期函数:select current_date();
3、自定义函数UDF:user-defined function
一进一出
一进多出
多进一出
4、自定义UDF函数
上传jar包,执行调用
create temporary function mylower as "com.atguigu.hive.Lower";
八、压缩存储
1、压缩配置
方式、参数配置
2、Map输出阶段压缩(MR引擎)
set mapreduce.map.output.compress=true;
也可以设置压缩方式
3、开启Reduce输出阶段压缩
set hive.exec.compress.output=true;
4、文件存储格式
列式存储和行式存储
TextFile默认不压缩
Orc
Parquet二进制存储,文件是自解析的
5、存储和压缩结合
建表时压缩stored as orc
hive表的数据存储格式一般选择:orc或parquet。压缩方式一般选择snappy,lzo。
九、Hive实战
1、统计各种TopN指标
十、分区表和分桶表
1、分区表
分区就是分目录
CRUD分区
二级分区表的数据加载和查询
动态分区调整
2、分桶表
决定数据放入哪个桶
对分桶字段的值进行哈希,然后除以桶的个数求余
十一、企业调优
1、Fetch抓取
set hive.fetch.task.conversion=more;
不必使用MapReduce计算
2、表的优化
数据量小的表放在join的左边
合理设置MR数量
3、JVM重用
4、查看执行计划
explain extended select * from emp;
【Hive】概念、安装、数据类型、DDL、DML操作、查询操作、函数、压缩存储、分区分桶、实战Top-N、调优(fetch抓取)、执行计划的更多相关文章
- Hive 实战(2)--hive分区分桶实战
前言: 互联网应用, 当Mysql单机遇到性能瓶颈时, 往往采用的优化策略是分库分表. 由于互联网应用普遍的弱事务性, 这种优化效果非常的显著.而Hive作为数据仓库, 当数据量达到一定数量时, 查询 ...
- Hive数据据类型 DDL DML
Hive的基本数据类型 DDL DML: 基本数据类型 对于Hive而言String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以 ...
- 第4节 hive调优:1、2、fetch抓取和表的优化
hive的调优:第一个调优:fetch抓取,能够避免使用mr的,就尽量不要用mr,因为mr太慢了 set hive.fetch.task.conversion=more 表示我们的全局查找,字段查找, ...
- 大数据入门第十一天——hive详解(二)基本操作与分区分桶
一.基本操作 1.DDL 官网的DDL语法教程:点击查看 建表语句 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data ...
- MySql用statement实现DDL,DML,DQL的操作Demo
Demo1 Connection connection=null; Statement stmt=null; int result=-1; try { Class.forName("com. ...
- Hibernate修改操作 删除操作 查询操作 增加操作 增删改查 Hibernate增删查改语句
我用的数据库是MySQL,实体类叫User public class User { private Integer uid; private String username; private Stri ...
- hive分区分桶
目录 1.分区 1.1.静态分区 1.1.1.一个分区 1.1.2.多个分区 1.2.动态分区 2.分桶 1.分区 如果一个表中数据很多,我们查询时就很慢,耗费大量时间,如果要查询其中部分数据该怎么办 ...
- Hive调优
Hive存储格式选择 和Hive 相关优化: 压缩参考 Hive支持的存储数的格式主要有:TEXTFILE .SEQUENCEFILE.ORC.PARQUET. 文件存储格式 列式存储和行式存储 行存 ...
- 【Hive六】Hive调优小结
Hive调优 Hive调优 Fetch抓取 本地模式 表的优化 小表.大表Join 大表Join大表 MapJoin Group By Count(Distinct) 去重统计 行列过滤 动态分区调整 ...
- Hive(八)Hive的Shell操作与压缩存储
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
随机推荐
- Kibana:在Kibana中对数据进行深入分析 (drilldown)
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/105193907 在上面,我们需要把之前地址栏中拷贝的内容粘贴过来,并做相应的修改.针 ...
- 2_Git
一. 引言 在单人开发过程中, 需要进行版本管理, 以利于开发进度的控制 在多人开发过程中, 不仅需要版本管理, 还需要进行多人协同控制 二. 介绍 Git是一个开源的分布式版本控制系统, 用于敏捷高 ...
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- WPF绘制圆形调色盘
本文使用writeableBitmap类和HSB.RGB模式来绘制圆形的调色盘. 开源项目地址:https://github.com/ZhiminWei/Palette RGB为可见光波段三个颜色通道 ...
- .Net CLR GC plan_phase二叉树和Brick_table
楔子 别那么懒,勤快点.以下取自CLR PreView 7.0. 主题 GC计划阶段(plan_phase)主要就两个部分,一个是堆里面的对象构建一颗二叉树(这颗二叉树的每个节点包含了诸如对象移动信息 ...
- 220726 T3 最优化问题 (树状数组)
题目描述 在同学们的努力下, 高匀感受到了 alb 的快乐. 高勺意犹未尽,找来了一个长度为 nn 的序列 a_1,a_2,-.,a_na1,a2,-.,an . 她想要删除这个序列中的 kk ...
- SpringMvc(五) - 支付宝沙箱和关键字过滤,md5加密,SSM项目重要知识点
1.支付宝沙箱 1.1 jar包 alipay-sdk <!-- alipay-sdk --> <dependency> <groupId>com.alipay.s ...
- MSQL-->存储引擎
概述 MySQL体系结构图 Innodb引擎是在mysql的5.5版本之后的默认存储引擎. Index是在引擎层次的,不同的存储引擎index的用法不同. 存储引擎就是存储数据,建立索引,更新查询数据 ...
- Sentinel安装教程【Linux+windows】
一.Sentinel的简介 Sentinel是阿里巴巴出品的一款流控组件,它以流量为切入点,在流量控制.断路.负载保护等多个领域开展工作,保障服务可靠性. 如果你学过netflix公司旗下的Hystr ...
- 现有一个接口DataOperation定义了排序方法sort(int[])和查找方法search(int[],int),已知类QuickSort的quickSort(int[])方法实现了快速排序算法
欢迎大家加入我的社区:http://t.csdn.cn/Q52km 社区中不定时发红包 文章目录 1.UML类图 2.源码: 3.优缺点分析 1.UML类图 2.源码: package com.bac ...