ApiView/Request类源码分析/序列化器
内容概要
- ApiView+JsonResponse编写接口
- ApiView+Response编写接口
- ApiView源码解析
- Request对象源码分析
- 序列化器介绍和快速使用/反序列化
- 反序列化的校验
ApiView+JsonResponse编写接口
我们还是在models模型层中创建一个book类
里面包含 name/price字段
我们就使用django自带的sqlite数据库即可
'modles.py'
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
'views'
from django.shortcuts import render
from rest_framework.views import APIView # 导入APiView
from django.http import JsonResponse
from app01 import models
class BookView(APIView): # 继承APIView类
def get(self, request):
book_queryset = models.Book.objects.all()
book_list = []
for book_obj in book_queryset: book_list.append({'name':book_obj.name,'price':book_obj.price})
return JsonResponse(book_list,safe=False)
# 因为在返回列表格式数据的时候会出现问题,需要将safe=False
'urls'
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('book/api/v1/',views.BookView.as_view()),
]
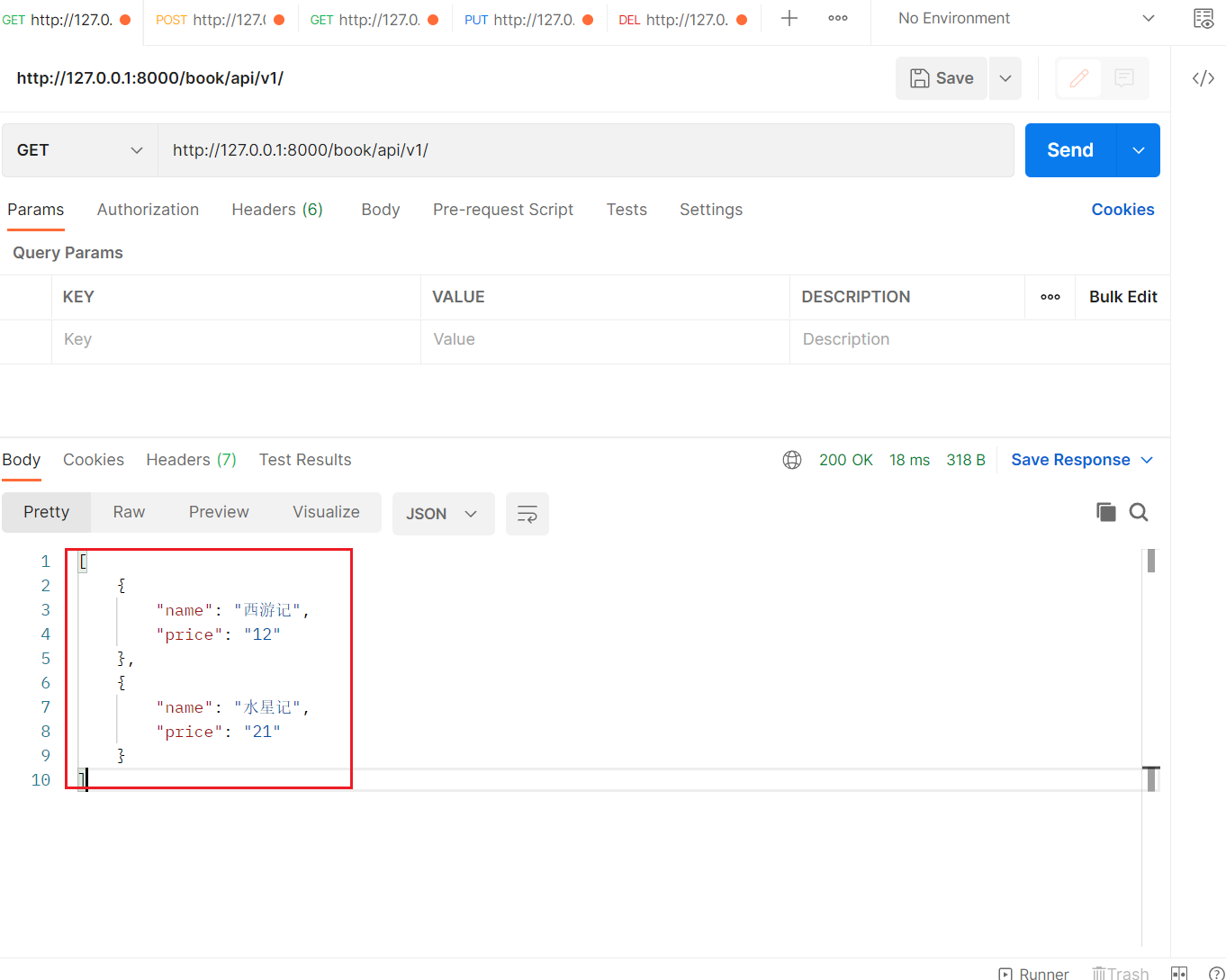
ApiView+Response编写接口
与JsonResponse基本一致,只是在返回数据时,不需要进行safe=False的操作
def get(self,request):
book_queryset = models.Book.objects.all()
book_list = []
for book_obj in book_queryset:
book_list.append({'name':book_obj.name,'price':book_obj.price})
return Response(book_list)
ApiView源码解析
我们接下来分析以下APIView和View到底有什么区别?
首先是APIView的执行流程:
路由层:path('book/api/v1/',views.BookView.as_view()),
请求来了,执行views.BookView.as_view()()
'as_view()是APIView中的方法,并不是View的了!'
# 调用父类的as_view()方法,APIView继承的是View
view = super().as_view(**initkwargs)
# 拿到父类中的闭包函数view
as_view() 方法 返回了 >>>> return csrf_exempt(view)
# csrf_exempt 排除所有csrf的认证
# 相当于在所有的方法上面加了这个装饰器
路由匹配成功,执行 csrf_exempt(view)(requets)
相当于回到了View类中,执行闭包函数view,返回的是
return self.dispatch(request, *args, **kwargs)
这个self就是我们视图函数中编写的BookView类产生的对象
所以执行对象.dispatch,因为这个BookView继承了APIView
正好在APIView中也有dispatch方法
def dispatch(self, request, *args, **kwargs):
# request是django原生的request,老的request
request = self.initialize_request(request, *args, **kwargs)
self.request = request
# 把老的request包装成了新的request,这个是drf提供的Request类的对象
try:
# 执行了三大认证(认证,频率,权限)使用新的request
self.initial(request, *args, **kwargs)
接下来跟CBV源码都一样了
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
# 将新的request传入,视图类中的get的request也是新的request
response = handler(request, *args, **kwargs)
except Exception as exc:
# 在执行3大认证和视图类中方法的过程中,如果出了异常,都能捕获到---》全局异常捕获
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
# 总结
1 去除了所有的csrf
2 包装了新的request,以后在视图类中用的request是新的request Request类的对象,不是原生的了
-原生的在:新的requets._request
3 在执行视图类的方法之前,执行了3大认证
4 如果在3大认证或视图函数方法执行过程中出了错,会有异常捕获>>>全局异常捕获
5 以后视图类方法中的request都是新的了
Request源码分析
在Request类中有__getattr__魔法方法
如果我们使用新的request.method方法就会触发Request中的__getattr__方法
def __getattr__(self, attr):
try:
return getattr(self._request, attr) # 会从老的request中获取method方法
except AttributeError:
return self.__getattribute__(attr)
-request.data--->这是个方法,包装成了数据属性
-以后无论post,put 在body中提交的数据,都从request.data中取,取出来就是字典
-无论是那种编码格式
-request.query_params--->这是个方法,包装成了数据属性
-get请求携带的参数,以后从这里面取
-query_params:查询参数--->restful规范请求地址中带查询参数
-request.FILES--->这是个方法,包装成了数据属性
-前端提交过来的文件,从这里取
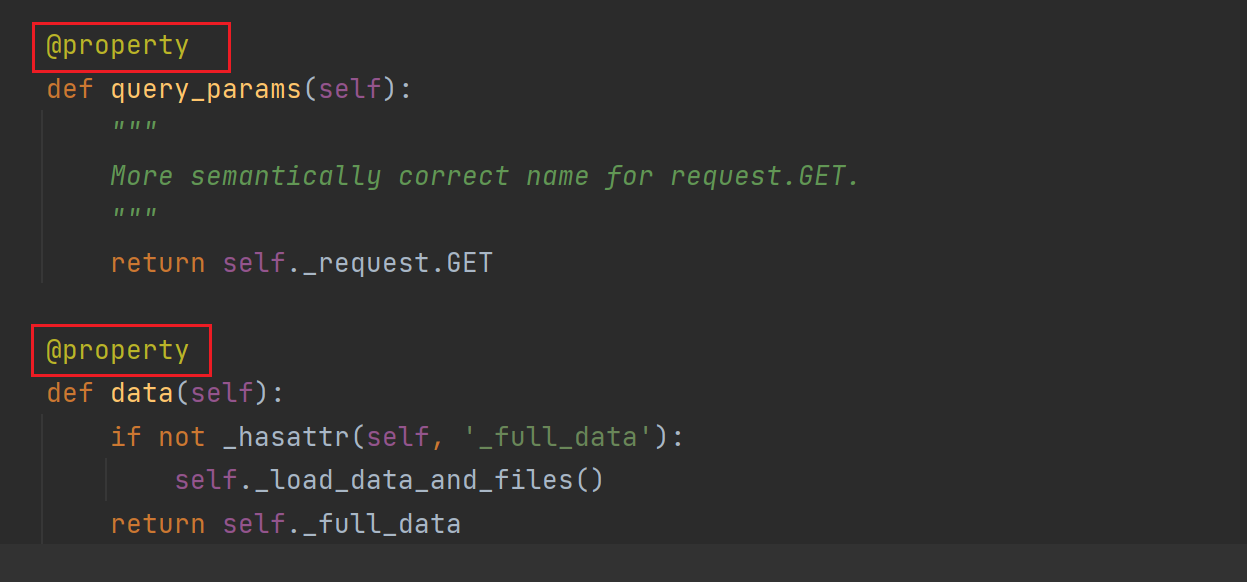
它们都携带了@property装饰器,将方法伪装成了属性
# Request类总结
-1 新的request用起来,跟之前一模一样,因为新的取不到,会取老的__getattr__
-2 request.data 无论什么编码,什么请求方式,只要是body中的数据,就从这里取(字典格式)
-3 request.query_params 就是原来的request._request.GET
-4 上传的文件从request.FILES中取
序列化器介绍和快速使用
我们在编写接口时,经常需要使用到序列化和反序列化
并且在反序列化过程中需要进行数据校验
drf中直接提供了固定的写法,我们只需要按照固定写法编写即可完成上述需求
drf提供了两个类 Serializer/ModelSerializer
以后我们只需要编写自己的类,继承drf提供的序列化类
使用其中的某些方法即可
序列化基本使用>>>序列化多条数据
**serializer.py >>> BookSerializer类
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField() # 只需要填写需要序列化的字段即可
price = serializers.CharField()
views视图 >>> BookView类
def get(self,request):
book_queryset = models.Book.objects.all()
serializer_obj = serializer.BookSerializer(instance=book_queryset,many=True)
# instance 参数是指定需要序列化的对象,
# many 参数是如果有多个对象就需要将many参数改为True,默认为False
return Response(serializer_obj.data)
urls路由层 >>> urlpatterns
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('book/api/v1/',views.BookView.as_view()),
]
序列化基本使用>>> 反序列化单条数据(新增)
**serializer.py >>> BookSerializer类
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField() # 只需要填写需要序列化的字段即可
price = serializers.CharField()
# 新增数据需要我们自己编写create方法来进行保存
def create(self, validated_data):
# validated_data >> 校验完成的数据
book_obj = models.Book.objects.create(**validated_data)
return book_obj
views视图 >>> BookView类
def post(self,request):
# 因为是新增数据我们需要将前端传递来的数据反序列化
serializer_obj = serializer.BookSerializer(data=request.data)
if serializer_obj.is_valid(): # 校验数据是否合法
# 合法的数据通过ser_obj点save方法自动调用序列化文件中的create方法
serializer_obj.save()
return Response({"code":100,"msg":'新增成功','result':serializer_obj.data})
else:
return Response({"code":101,'msg':serializer_obj.errors})
urls路由层 >>> urlpatterns
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('book/api/v1/',views.BookView.as_view()),
]
序列化基本使用>>> 序列化单条数据(查询)
**serializer.py >>> BookSerializer类
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField() # 只需要填写需要序列化的字段即可
price = serializers.CharField()
views视图 >>> BookDetailView类
class BookDetailView(APIView):
def get(self, request, pk):
book_obj = models.Book.objects.filter(pk=pk).first()
serializer_obj = serializer.BookSerializer(instance=book_obj)
return Response(serializer_obj.data)
urls路由层 >>> urlpatterns
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('book/api/v1/',views.BookView.as_view()),
path('book/api/v1/<int:pk>/',views.BookDetailView.as_view()),
]
序列化基本使用>>> 反序列化数据(修改单条数据)
**serializer.py >>> BookSerializer类
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
def create(self, validated_data):
# validated_data >> 校验完成的数据
# name = validated_data.get('name')
# price = validated_data.get('price')
book_obj = models.Book.objects.create(**validated_data)
return book_obj
def update(self, instance, validated_data):
# instance就是需要序列化的数据对象
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.save()
return instance # 返回序列化数据对象
views视图 >>> BookDetailView类
def put(self,request,pk):
book_obj = models.Book.objects.filter(pk=pk).first()
serializer_obj = serializer.BookSerializer(instance=book_obj,data=request.data)
if serializer_obj.is_valid():
serializer_obj.save() # 会自动调用update方法进行修改操作
return Response({"code": 103, "msg": '修改成功', 'result': serializer_obj.data})
else:
return Response({"code": 104, 'msg': serializer_obj.errors})
urls路由层 >>> urlpatterns
from django.contrib import admin
from django.urls import path
from app01 import views
urlpatterns = [
path('admin/', admin.site.urls),
path('book/api/v1/',views.BookView.as_view()),
path('book/api/v1/<int:pk>/',views.BookDetailView.as_view()),
]
删除单条数据 (不需要序列化/反序列化)
views视图 >>> BookDetailView类
class BookDetailView(APIView):
def delete(self, requset, pk):
Book.objects.filter(pk=pk).delete()
return Response({'code': 100, 'msg': '删除成功'})
反序列化数据校验
在我们的serializer.py文件中编写反序列化的校验
# 全局钩子 # 校验过后的数据,价格不能超过90
def validate(self, attrs):
if int(attrs.get('price')) >= 90:
raise ValidationError('书价格不能超过90')
else:
return attrs
# 局部钩子 校验名字不能以1开头
def validate_name(self, name):
if name.startswith('1'):
raise ValidationError('不能以1开头')
else:
return name
如果满足上述函数报错条件,serializer_obj.is_valid() 不成立!
练习
原生的request 没有data 属性 实现一个原生的 request.data
拿出无论什么编码格式提交的数据(编写FBV即可)
views.py
def method(func):
def inner(request,*args,**kwargs):
try:
# 如果报错说明数据不是Json格式
request.data = request.body
except:
request.data = request.POST
res = func(request)
return res
return inner
@method
def login(request):
print(request.data)
print(request.content_type)
return render(request,'login.html',locals())
ApiView/Request类源码分析/序列化器的更多相关文章
- Request类源码分析
通过APIView进入找到Request的源码 可以看见一堆属性和方法,其中request.data其实是一个方法,被包装成一个属性 继续看__getattr__和query_params方法: 代码 ...
- List 接口以及实现类和相关类源码分析
List 接口以及实现类和相关类源码分析 List接口分析 接口描述 用户可以对列表进行随机的读取(get),插入(add),删除(remove),修改(set),也可批量增加(addAll),删除( ...
- Spring AOP 源码分析 - 拦截器链的执行过程
1.简介 本篇文章是 AOP 源码分析系列文章的最后一篇文章,在前面的两篇文章中,我分别介绍了 Spring AOP 是如何为目标 bean 筛选合适的通知器,以及如何创建代理对象的过程.现在我们的得 ...
- (一) Mybatis源码分析-解析器模块
Mybatis源码分析-解析器模块 原创-转载请说明出处 1. 解析器模块的作用 对XPath进行封装,为mybatis-config.xml配置文件以及映射文件提供支持 为处理动态 SQL 语句中的 ...
- Python学习---Django的request.post源码分析
request.post源码分析: 可以看到传递json后会帮我们dumps处理一次最后一字节形式传递过去
- Cocos2d-X3.0 刨根问底(六)----- 调度器Scheduler类源码分析
上一章,我们分析Node类的源码,在Node类里面耦合了一个 Scheduler 类的对象,这章我们就来剖析Cocos2d-x的调度器 Scheduler 类的源码,从源码中去了解它的实现与应用方法. ...
- springMVC源码分析--拦截器HandlerExecutionChain(三)
上一篇博客springMVC源码分析--HandlerInterceptor拦截器调用过程(二)中我们介绍了HandlerInterceptor的执行调用地方,最终HandlerInterceptor ...
- Struts2 源码分析——拦截器的机制
本章简言 上一章讲到关于action代理类的工作.即是如何去找对应的action配置信息,并执行action类的实例.而这一章笔者将讲到在执行action需要用到的拦截器.为什么要讲拦截器呢?可以这样 ...
- Java并发编程笔记之Unsafe类和LockSupport类源码分析
一.Unsafe类的源码分析 JDK的rt.jar包中的Unsafe类提供了硬件级别的原子操作,Unsafe里面的方法都是native方法,通过使用JNI的方式来访问本地C++实现库. rt.jar ...
- Java Properties类源码分析
一.Properties类介绍 java.util.Properties继承自java.util.Hashtable,从jdk1.1版本开始,Properties的实现基本上就没有什么大的变动.从ht ...
随机推荐
- Win环境安装Protobuf 2.0 版本
转载请注明出处: 安装步骤 下载 protobuf-2.5.0.zip 与 protoc-2.5.0-win32.zip 下载链接 : https://github.com/protocolbuffe ...
- 野火 STM32MP157 开发板内核和设备树的编译烧写
一.环境 编译环境:Ubuntu 版本:18.4.6 交叉编译工具:arm-linux-gnueabihf-gcc 版本:7.4.1 开发板:STM32MP157 pro 烧写方式:STM32Cube ...
- JIRA操作之JQL
搜索功能 Jira的搜索功能非常强大,有专用的搜索语言JQL(Jira Query Language).Jira的Python库是基于JQL语法搜索的,返回的是搜索到的问题列表. jira.searc ...
- 【实操日记】使用 PyQt5 设计下载远程服务器日志文件程序
最近通过 PyQt5 设计了一个下载服务器指定日期日志文件的程序,里面有些有意思的技术点,现在做一些分享. PyQt5 是一套 Python 绑定 Digia Qt5 应用的框架,是最强大的 GUI ...
- Python中 or、and 的优先级
上式可以看出 先看 and 输出才为 ture 因此 优先级 and>or
- 硬核!Apache Hudi Schema演变深度分析与应用
1.场景需求 在医疗场景下,涉及到的业务库有几十个,可能有上万张表要做实时入湖,其中还有某些库的表结构修改操作是通过业务人员在网页手工实现,自由度较高,导致整体上存在非常多的新增列,删除列,改列名的情 ...
- Easy-Classification-分类框架设计
1. 框架介绍 Easy-Classification是一个应用于分类任务的深度学习框架,它集成了众多成熟的分类神经网络模型,可帮助使用者简单快速的构建分类训练任务. 框架源代码:https://gi ...
- php+apache环境搭建
[先安装apache] apache快速安装:https://www.cnblogs.com/brad93/p/16718104.html PHP安装教程参考:https://www.cnblogs. ...
- 批量将多个相同Excel表格内容合并到一个Excel表格的sheet工作簿当中。
Sub Books2Sheets()Dim fd As FileDialog Set fd = Application.FileDialog(msoFileDialogFilePicker) Dim ...
- kestrel网络编程--开发redis服务器
1 文章目的 本文讲解基于kestrel开发实现了部分redis命令的redis伪服务器的过程,让读者了解kestrel网络编程的完整步骤,其中redis通讯协议需要读者自行查阅,文章里不做具体解析. ...