自增特性,外键,级联更新与级联删除,表间关系,SELECT用法,GROUP BY
自增特性
自动增长的作用:
问题:为数据表设置主键约束后,每次插入记录时,如果插入的值已经存在,会插入失败。
如何解决:为主键生成自动增长的值。
自动增长的语法:
字段名 数据类型 AUTO_INCREMENT;
使用须知:
1.一个表中只能有一个自动增长字段;
2.该字段的数据类型是整数类型;
3.必须定义为键,如 UNIQUE KEY、 PRIMARY KEY;
4.若为自动增长字段插入NULL、0、 DEFAULT或在插入时省略该字段,该字段就会使用自动增长值;
5.若插入的是一个具体值,则不会使用自动增长值;
6.自动增长值从1开始自增,每次加1
7.若插入的值大于自动增长的值,则下次插入的自动增长值会自动使用最大值加1;
8.若插入的值小于自动增长值,则不会对自动增长值产生影响;
9.使用 DELETE删除记录时,自动增长值不会减小或填补空缺.
自动增长使用示例
--自动增长使用演示
Create Table my_auto(
id Int Unsigned Primary Key Auto_Increment,
username Varchar(20)
);
#查看字段信息
DESC my_auto;

#插入时省略id字段,将会使用自动增长值
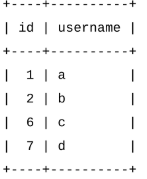
Insert Into my_auto(username) Values('a');
#为id字段插入null,将会使用自动增长值
Insert Into my_auto Values(Null,'b');
#为id字段插入具体值6
Insert Into my_auto Values(6,'c');
#为id字段插入0,使用自动增长值
Insert Into my_auto Values(0,'d');
#查看
Select * From my_auto;
为现有的表修改或删除自动增长:
#修改自动增长值
Alter Table my_auto Auto_Increment=10;
#删除自动增长值
Alter Table my_auto Modify id Int Unsigned;
#重新为id添加自动增长值
Alter Table my_auto Modify id Int Unsigned Auto_Increment;
注意:
1.自动增长删除并重新添加后,自动增长的初始值会自动设为该列现有的最大值加1;
2.在修改自动增长值时,修改的值若小于该列见有的最大值,则修改不会生效。
外键
概念
外键(foreign key) 是用于建立和加强两个表数据之间的链接的一列或多列。外键表示一个表中的一
个字段被另一个表中的一个字段引用。外键对相关表中的数据造成了限制,使MySQL能够保持参照完整性。
外键约束主要用来维护两个表之间数据的一致性。简言之,表的外键就是另一表的主键,外键将两表联系
起来。一般情况下,要删除一张表中的主键必须首先要确保其它表中的没有相同外键(即该表中的主键没有一
个外键和它相关联)。
定义外键时,需要遵守下列规则:
1.主表必须已经存在于数据库中,或者是当前正在创建的表。如果是后一种情况,则主表与从表是同一个
表,这样的表称为自参照表,这种结构称为自参照完整性。
2.必须为主表定义主键。
3.主键不能包含空值,但允许在外键中出现空值。也就是说,只要外键的每个非空值出现在指定的主键中,
这个外键的内容就是正确的。
4.在主表的表名后面指定列名或列名的组合。这个列或列的组合必须是主表的主键或候选键。
5.外键中列的数目必须和主表的主键中列的数目相同。
6.外键中列的数据类型必须和主表主键中对应列的数据类型相同。
设置外键约束失效
查看外键约束是否有效 select @@FOREIGN_KEY_CHECKS,1表示有效,0表示失效。
设置失效 SET FOREIGN_KEY_CHECKS = 0 ,设置生效 SET FOREIGN_KEY_CHECKS = 1
案例
# 创建数据库
CREATE DATABASE Test;
USE TEMP;
# 创建表
CREATE TABLE student(
id int (11) primary key auto_increment,
name char(255),
sex char(255),
age int(11)
)charset utf8;
CREATE TABLE student_score(
id int (11) primary key auto_increment,
class char(255),
score char(255),
student_id int(11)
)charset utf8;
Alter table student_score add constraint s_id foreign key(student_id) references student(id);
# 创建表(第二种方法)
CREATE TABLE student(
id int (11) primary key auto_increment,
name char(255),
sex char(255),
age int(11)
)charset utf8;
CREATE TABLE student_score(
id int (11) primary key auto_increment,
class char(255),
score char(255),
student_id int(11),
foreign key(student_id) references student(id)
)charset utf8;
# 插入学生信息
INSERT INTO student(name,sex,age) VALUES('学生1','男','12');
# 插入学科及分数信息
INSERT INTO student_score(class,score,student_id) VALUES('语文','100',1);
INSERT INTO student_score(class,score,student_id) VALUES('数学','100',1);
INSERT INTO student_score(class,score,student_id) VALUES('英语','100',1);
级联跟新和级联删除(一般在外键字段使用)
为什么要用级联?
当没有对目标键设置级联删除和更新,删除或更新主键表中的数据(外键表中有该目标键的数据)时,会
报错,不允许删除或更新,必须先把外键表中关联的数据删除之后才能删除主键表中的数据。
简单思路
多设置几条sql语句,在删除主键表中的数据时,先把外键表中与之关联的数据删除。
级联概念
概念:当对主键表中的数据进行删除和更新时,数据库会对关联的数据会自动删除和更新。
语法
写在外键约束的后面,在创建外键约束的时候创建级联操作
级联操作 语法
级联更新 on update cascade
级联删除 on delete cascade
案例
# 添加级联更新和级联删除
CREATE TABLE student(
id int (11) primary key auto_increment,
name char(255),
sex char(255),
age int(11)
)charset utf8;
CREATE TABLE student_score(
id int (11) primary key auto_increment,
class char(255),
score char(255),
student_id int(11)
)charset utf8;
Alter table student_score add constraint s_id foreign key(student_id) references student(id) on update cascade on delete cascade;
# 添加级联更新和级联删除(第二种方法)
CREATE TABLE student(
id int (11) primary key auto_increment,
name char(255),
sex char(255),
age int(11)
)charset utf8;
CREATE TABLE student_score(
id int (11) primary key auto_increment,
class char(255),
score char(255),
student_id int(11),
foreign key(student_id) references student(id)
on update cascade
on delete cascade
)charset utf8;
表与表之间的关系
一对多 : 关联方式 -- foreign key
1.以员工表与部门表为例
先站在员工表的角度
问:一个员工能否对应多个部门
答:不可以
再站在部门表的角度
问:一个部门能否对应多个员工
答:可以
结论:换位思考之后得出的答案是一个可以一个不可以
所以关系是"一对多" 部门是'一'员工是'多'
'''关系表达只能用一对多 不能用多对一'''
一对多关系 外键字段建在"多"的一方(员工表)
一对多关系: 一对多关系是关系数据库中两个表之间的一种关系,该关系中第一个表中的单个行可以与第
二个表中的一个或多个行相关,但第二个表中的一个行只可以与第一个表中的一个行相关。
一对多关系,一般是一个表的主键对应另一个表的非主键,主键的值是不能重复的,而非主键值是可以重复的,
一个主键值对应另一个表的非主键的值,那么就只有一个值对一个值或一个值对多个值两种可能,故称一对多。
最常用的关系
例如: 学生和教室
分析:一个教室有多个学生,一个学生只能对应一个教室
create table class(id int primary key,cname char(12));
create table student(id int primary key,sname char(16),cid int,foreign key(cid) references class(id));
多对多 : 关联方式 -- foreign key + 一张新的表
以图书与作者表为例
1.先站在图书表的角度
问:一本书籍能否对应多名作者
答:可以
2.再站在作者表的角度
问:一名作者能否对应多本书籍
答:可以
结论:换位思考之后两边都可以 那么就是"多对多"关系
多对多
例如:老师 和 教室
分析:一个老师可以选择很多教室,一个教室也可以被很多老师选择
create table class(id int primary key,cname char(12));
create table teacher(id int primary key,tname char(12));
create table teach_cls(id int,cid int,tid int,foreign key(cid) references class(id)),foreign key(tid) references teacher(id)));
一对一 : 关联方式 -- foreign key + unique
针对qq用户表 其实里面的数据可以分成两类
热数据:经常需要使用的数据
eg:qq号码 座右铭 个人简介 爱好
冷数据:不怎么经常需要使用的数据
eg:邮箱 电话 学校 ...
为了节省资源并降低数据库压力 会将表一分为二
用户表
存使用频率较高的数据字段
用户详情表
存使用频率较低的数据字段
1.先站在用户表的角度
问:一个用户数据能否对应多个用户详情数据
答:不可以
2.再站在用户详情表的角度
问:一个用户详情数据能否对应多个用户数据
答:不可以
结论:换位思考之后两边都不可以 那么关系可能有两种
'没有关系':用膝盖都能判断出来
'一对一关系'
针对'一对一关系'外键字段建在任意一方都可以,但是推荐建在查询频率较高的较好的一方
create table guest(id int primary key,name char(12));
create table student(id int primary key,sname char(12),gid int unique,foreign key(gid) referances guest(id));
SELECT
为列设置别名
SECECT 列名1 AS 别名1,列名2 AS 别名2 FROM 表名;
如果别名使用汉语,需要用双引号“”括起来
在返回值中加入常数列
在返回值中添加表中没有的常数(字符串常数、数字常数、日期常数):
SELECT 常数 AS 自定义的列名,列名1,列名2 FROM 表名;
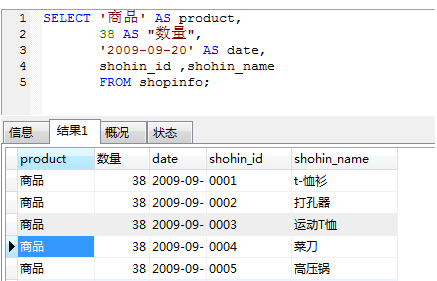
删除结果中的重复项
采用DISTINCT关键字去除返回结果中的重复项,NULL也是一类数据,返回结果中如果有多个null,使用distinct将多个null合并为一条。
select shop_car from shop;
返回的值为:
'''
衣服
办公用品
衣服
厨房用具
厨房用具
厨房用具
厨房用具
'''
select DISTINCT shop_car from shop;
返回值为:
'''
衣服
办公用品
厨房用具
'''
多列使用
多列数据都相同的情况下会被合并,(distinct只能放在第一个字段名之前)
select DISTINCT shop_car,data from shop;
运算符
1.算数运算符(与Null计算还是Null)
select id,score,score/100 as "成绩百分比" from score_student;
2.比较运算符 (日期比较、字符串比较)
select * from teacher where name is Null;
3.逻辑运算符
-- 性别为男生,且姓名是小张或小王的同学
select * from student where 性别 = '男' and (姓名 = '小张' or 姓名 = '小王');
select * from student where 性别 = '男' and 姓名 in ('小张','小王');
-- 查找成绩在60到90之间的学生
select * from score where 成绩 >= 60 and 成绩 <= 90;
select * from score where 成绩 between 60 and 90;
-- 成绩小于60或者大于90的数据
select * from score where 成绩 < 60 or 成绩 > 90;
select * from score where 成绩 not between 60 and 90;
-- in 与not in的使用
select * from student where 姓名 in ('小张','小王');
select * from student where 姓名 not in ('小张','小王');
模糊查询
like使用
% 任意个数的字符
_ 任意单个字符
-- 查询以小开头的额学生:
select * from student where 姓名 like "小%";
-- 查询最后一个字是玉的学生:
select * from student where 姓名 like "%玉";
-- 查询姓名中带小的学生:
select * from student where 姓名 like '%小%';
-- 查询姓名以小开头且名字为2个字的学生:
select * from student where 姓名 like '小_'
GROUP BY
group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
某个员工信息表结构和数据如下:
id name dept salary edlevel hiredate
1 张三 开发部 2000 3 2009-10-11
2 李四 开发部 2500 3 2009-10-01
3 王五 设计部 2600 5 2010-10-02
4 王六 设计部 2300 4 2010-10-03
5 马七 设计部 2100 4 2010-10-06
6 赵八 销售部 3000 5 2010-10-05
7 钱九 销售部 3100 7 2010-10-07
8 孙十 销售部 3500 7 2010-10-06
按部门分组
select * from staff group by dept;
"""
mysql5.7及以上版本默认自带sql_mode=only_full_group_by
该模式要求分组之后默认只可以直接获取分组的依据不能直接获取其他字段
原因是分组的目的就是按照分组的条件来管理诸多数据 最小单位应该是分组的依据而不是单个单个的数据
如果是MySQL5.6及以下版本 需要自己手动添加
"""
聚合函数
COUNT()函数:用于统计记录的条数。
SUM()函数:用于计算字段的值的总和。
AVG()函数:用于计算字段的值的平均值。
MAX()函数:用于查询字段的最大值。
MIN()函数:用于查询字段的最小值。
# 1.统计每个部门的最高薪资
select dept,max(salary) from staff group by dept;
# 2.统计每个部门的平均薪资
select dept,avg(salary) from staff group by dept;
# 3.统计每个部门的员工人数
select dept,count(id) from staff group by dept;
# 4.统计每个部门的月工资开销
select dept,sum(salary) from staff group by dept;
# 5.统计每个部门薪资最少
select dept,min(salary) from staff group by dept;
"""间接获取分组以外其他字段的数据"""
# 1.统计每个部门下所有员工的姓名
select dept,group_concat(name) from staff group by dept;
# 2.统计每个部门下所有员工的姓名和进入公司的时间
select dept,group_concat(name,hiredate) from staff group by dept;
select dept,group_concat(name,'|',hiredate) from staff group by dept;
今日作业
# 数据准备
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#插入记录
#三个部门:教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), #以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
1. 查询岗位名以及岗位包含的所有员工名字
select post,group_concat(name) from emp group by post;
+-----------------------------+------------------------------------------------+
| post | group_concat(name) |
+-----------------------------+------------------------------------------------+
| operation | 僧龙,程咬金,程咬银,程咬铜,程咬铁 |
| sale | 哈哈,呵呵,西西,乐乐,拉拉 |
| teacher | tom,kevin,tony,owen,jack,jenny,sank |
| 张江第一帅形象代言 | jason |
+-----------------------------+------------------------------------------------+
4 rows in set (0.00 sec)
2. 查询岗位名以及各岗位内包含的员工个数
mysql> select post,count(id) from emp group by post;
+-----------------------------+-----------+
| post | count(id) |
+-----------------------------+-----------+
| 张江第一帅形象代言 | 1 |
| teacher | 7 |
| sale | 5 |
| operation | 5 |
+-----------------------------+-----------+
4 rows in set (0.00 sec)
3. 查询公司内男员工和女员工的个数
mysql> select sex,count(id) from emp group by sex;
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
2 rows in set (0.00 sec)
4. 查询岗位名以及各岗位的平均薪资
mysql> select post,avg(salary) from emp group by post;
+-----------------------------+---------------+
| post | avg(salary) |
+-----------------------------+---------------+
| 张江第一帅形象代言 | 7300.330000 |
| teacher | 151842.901429 |
| sale | 2600.294000 |
| operation | 16800.026000 |
+-----------------------------+---------------+
4 rows in set (0.00 sec)
5. 查询岗位名以及各岗位的最高薪资
mysql> select post,max(salary) from emp group by post;
+-----------------------------+-------------+
| post | max(salary) |
+-----------------------------+-------------+
| 张江第一帅形象代言 | 7300.33 |
| teacher | 1000000.31 |
| sale | 4000.33 |
| operation | 20000.00 |
+-----------------------------+-------------+
4 rows in set (0.00 sec)
6. 查询岗位名以及各岗位的最低薪资
mysql> select post,min(salary) from emp group by post;
+-----------------------------+-------------+
| post | min(salary) |
+-----------------------------+-------------+
| 张江第一帅形象代言 | 7300.33 |
| teacher | 2100.00 |
| sale | 1000.37 |
| operation | 10000.13 |
+-----------------------------+-------------+
4 rows in set (0.00 sec)
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
mysql> select sex,avg(salary) from emp group by sex;
+--------+---------------+
| sex | avg(salary) |
+--------+---------------+
| male | 110920.077000 |
| female | 7250.183750 |
+--------+---------------+
2 rows in set (0.00 sec)
自增特性,外键,级联更新与级联删除,表间关系,SELECT用法,GROUP BY的更多相关文章
- sql在外键存在的情况下删除表
SQL Server 批量 停用/启用 外键约束 今天百度知道上面,看到这样一个要求: 现在有一个库,有很多张表想要删除一张表的记录的时候,由于外键关联太多,所以,没法删除相应的记录,谁能帮忙写个存储 ...
- oracle级联更新与级联删除
Oracle级联删除:可以使用外键约束来实现,建立表的主外键关系,给列设置级联删除.如下: ——创建了CLASS表,并设置ID字段为主键. -- Create tablecreate table CL ...
- Mysql学习笔记(八)由触发器回顾外键约束中的级联选项
近些天都没有写博客.在学习mysql的知识,通过学习和练习,也熟悉了mysql的函数.触发器.视图和存储过程.并且在实际的开发过程中也应用了一小部分.效果还是十分理想的. 今天晚上在学习触发器模仿in ...
- MySQL的数据类型,MySQL增删改--添加主外键、添加属性、删除主外键、改表名、获取系统当前时间等
ls /etc/rc.d/init.d/mysql56service mysql56 start ps aux |grep "mysql"|grep "socket=&q ...
- mysql数据库设置外键,更新与删除选项
CASCADE:父表delete.update的时候,子表会delete.update掉关联记录:SET NULL:父表delete.update的时候,子表会将关联记录的外键字段所在列设为null, ...
- MySql必知必会实战练习(四)主键、外键、sql约束、联结表
本博将对主键.外键.MySql数据库约束和联结表的相关特性进行总结和实战 1. 主键 表中的每一行都应该具有可以唯一标识自己的一列(或一组列),而这个承担标识作用的列称为主键 如果没有主键,数据的管理 ...
- Mysql实现级联操作(级联更新、级联删除)
一.首先创建两张表stu,sc create table stu( sid int UNSIGNED primary key auto_increment, name ) not null) TYPE ...
- MySQL之级联删除、级联更新、级联置空
1. 准备测试表 # 专业表major ))engine=innodb default charset=utf8; # 学生表mstudent ), major int)engine=innodb d ...
- Mysql实现级联操作(级联更新、级联删除)(转)
一.首先创建两张表stu,sc create table stu( sid int UNSIGNED primary key auto_increment, name varchar(20) not ...
随机推荐
- 学习openldap03
ldap统一认证架构 一.ldap目录服务介绍什么是目录服务? 目录是一类为了浏览和搜索数据而设计的特殊的数据库.例如,为人所熟知的微软公司的活动目录(active directory)就是目录数据 ...
- BMZCTF phar???
pchar??? 补充知识点 开始这题之前我们先补充一个知识点 phar 的文件包含 和上面类似先创建一个phar 标准包,使用 PharData 来创建,然后添加文件进去phar里面. 然后在文件包 ...
- 攻防世界shrine
shrine import flask import os app = flask.Flask(__name__) app.config['FLAG'] = os.environ.pop('FLAG' ...
- 03-三高-并行并发&服务内
三高项目-服务内并发 cap:分布式系统的起点. 一致性,可用性,分区容错性. P:分区容错性.分区,容错. 因为有网络的8大谬误: 网络是可靠的. 没有延迟 带宽无限 网络安全 拓扑结构 ...
- STM32 中的 assert_param 函数
在学STM32的时候函数assert_param出现的几率非常大,上网搜索一下,网上一般解释断言机制,做为程序开发调试阶段时使用. 断言机制函数assert_param我们在分析库函数的时候,几乎每一 ...
- 编译器警告c4996
由于编译器的原因(我用的是vs 2012),我们写程序时有时候会遇到编译器给出的警告,如: warning C4996: 'fopen': This function or variable may ...
- css预编译--sass进阶篇
基础篇中主要介绍了一些sass的基本特性,进阶篇中,主要是写一些我们常用的sass控制命令,函数和规则. 控制命令 可能看过基础篇的朋友会发现在有些代码中出现@if @else @each等,熟悉JS ...
- Web 开发中 Blob 与 FileAPI 使用简述
本文节选自 Awesome CheatSheet/DOM CheatSheet,主要是对 DOM 操作中常见的 Blob.File API 相关概念进行简要描述. Web 开发中 Blob 与 Fil ...
- java堆排序
直接贴源代码: package com.java.fmd; import java.util.Scanner; public class HeapSort { int[] arr; public st ...
- 布局框架frameset
<!DOCTYPE html>//demo.html <html> <head> <meta charset="UTF-8"> &l ...