【Hadoop】10、Flume组件
Flume组件安装配置
1、下载和解压 Flume
# 传Flume安装包
[root@master ~]# cd /opt/software/
[root@master software]# ls
apache-flume-1.6.0-bin.tar.gz hadoop-2.7.1.tar.gz jdk-8u152-linux-x64.tar.gz mysql-5.7.18.zip sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
apache-hive-2.0.0-bin.tar.gz hbase-1.2.1-bin.tar.gz mysql-5.7.18 mysql-connector-java-5.1.46.jar zookeeper-3.4.8.tar.gz
# 使用root用户解压Flume到“/usr/local/src”路径
[root@master software]# tar xf /opt/software/apache-flume-1.6.0-bin.tar.gz -C /usr/local/src/
# 修改Flume安装路径文件夹名称
[root@master software]# cd /usr/local/src
[root@master src]# mv apache-flume-1.6.0-bin flume
# 修改文件夹归属用户和归属组为hadoop用户和hadoop组
[root@master src]# chown -R hadoop.hadoop /usr/local/src/
2、Flume 组件部署
# 编辑系统环境变量配置文件
[root@master src]# vi /etc/profile.d/flume.sh
添加:
export FLUME_HOME=/usr/local/src/flume
export PATH=${FLUME_HOME}/bin:$PATH
# 切换hadoop用户
[root@master src]# su - hadoop
# 查看是否成功
[hadoop@master ~]$ echo $PATH
/usr/local/src/zookeeper/bin:/usr/local/src/sqoop/bin:/usr/local/src/hbase/bin:/usr/local/src/jdk/bin:/usr/local/src/hadoop/bin:/usr/local/src/hadoop/sbin:/usr/local/src/flume/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/usr/local/src/hive/bin:/home/hadoop/.local/bin:/home/hadoop/bin
# 修改hbase-env.sh文件
[hadoop@master ~]$ vim /usr/local/src/hbase/conf/hbase-env.sh
#export HBASE_CLASSPATH=/usr/local/src/hadoop/etc/hadoop/ 注释掉这一行的内容
# 拷贝 flume-env.sh.template 文件
[hadoop@master ~]$ cd /usr/local/src/flume/conf
[hadoop@master conf]$ cp flume-env.sh.template flume-env.sh
# 修改并配置 flume-env.sh 文件
[hadoop@master conf]$ vi flume-env.sh
修改:
export JAVA_HOME=/usr/local/src/jdk
# 启动hadoop
[hadoop@master conf]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
hadoop@master's password:
master: namenode running as process 50448. Stop it first.
192.168.100.30: datanode running as process 43460. Stop it first.
192.168.100.20: datanode running as process 46094. Stop it first.
Starting secondary namenodes [0.0.0.0]
hadoop@0.0.0.0's password:
0.0.0.0: secondarynamenode running as process 50670. Stop it first.
starting yarn daemons
resourcemanager running as process 50836. Stop it first.
192.168.100.30: nodemanager running as process 43584. Stop it first.
192.168.100.20: nodemanager running as process 46228. Stop it first.
# 执行以上命令后要确保master上有NameNode、SecondaryNameNode、ResourceManager进程,在slave节点上要能看到DataNode、NodeManager进程
# master节点查看
[hadoop@master conf]$ jps
50448 NameNode
50836 ResourceManager
47502 QuorumPeerMain
50670 SecondaryNameNode
55855 Jps
# slave1节点查看
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ jps
2070 DataNode
2364 Jps
2191 NodeManager
[hadoop@slave1 ~]$
# slave2节点查看
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ jps
2166 NodeManager
2055 DataNode
2345 Jps
[hadoop@slave2 ~]$
# 验证安装是否成功
[hadoop@master conf]$ flume-ng version
Flume 1.6.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 2561a23240a71ba20bf288c7c2cda88f443c2080
Compiled by hshreedharan on Mon May 11 11:15:44 PDT 2015
From source with checksum b29e416802ce9ece3269d34233baf43f
# 若能够正常查询 Flume 组件版本为1.6.0,则表示安装成功。
3、使用 Flume 发送和接受信息
# 在 Flume 安装目录中创建 simple-hdfs-flume.conf 文件
[hadoop@master conf]$ cd /usr/local/src/flume
[hadoop@master flume]$ vi simple-hdfs-flume.conf
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/usr/local/src/hadoop/logs
a1.sources.r1.fileHeader=true
a1.sources.r1.deserializer.maxLineLength=30000
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://master:9000/tmp/flume
a1.sinks.k1.hdfs.rollsize=1024000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollInterval=900
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.channels.c1.type=file
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=1000
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
# 删除/tmp
[hadoop@master flume]$ hdfs dfs -rm -r /tmp
22/05/08 22:16:44 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /tmp
# 创建/tmp/flume
[hadoop@master flume]$ hdfs dfs -mkdir -p /tmp/flume
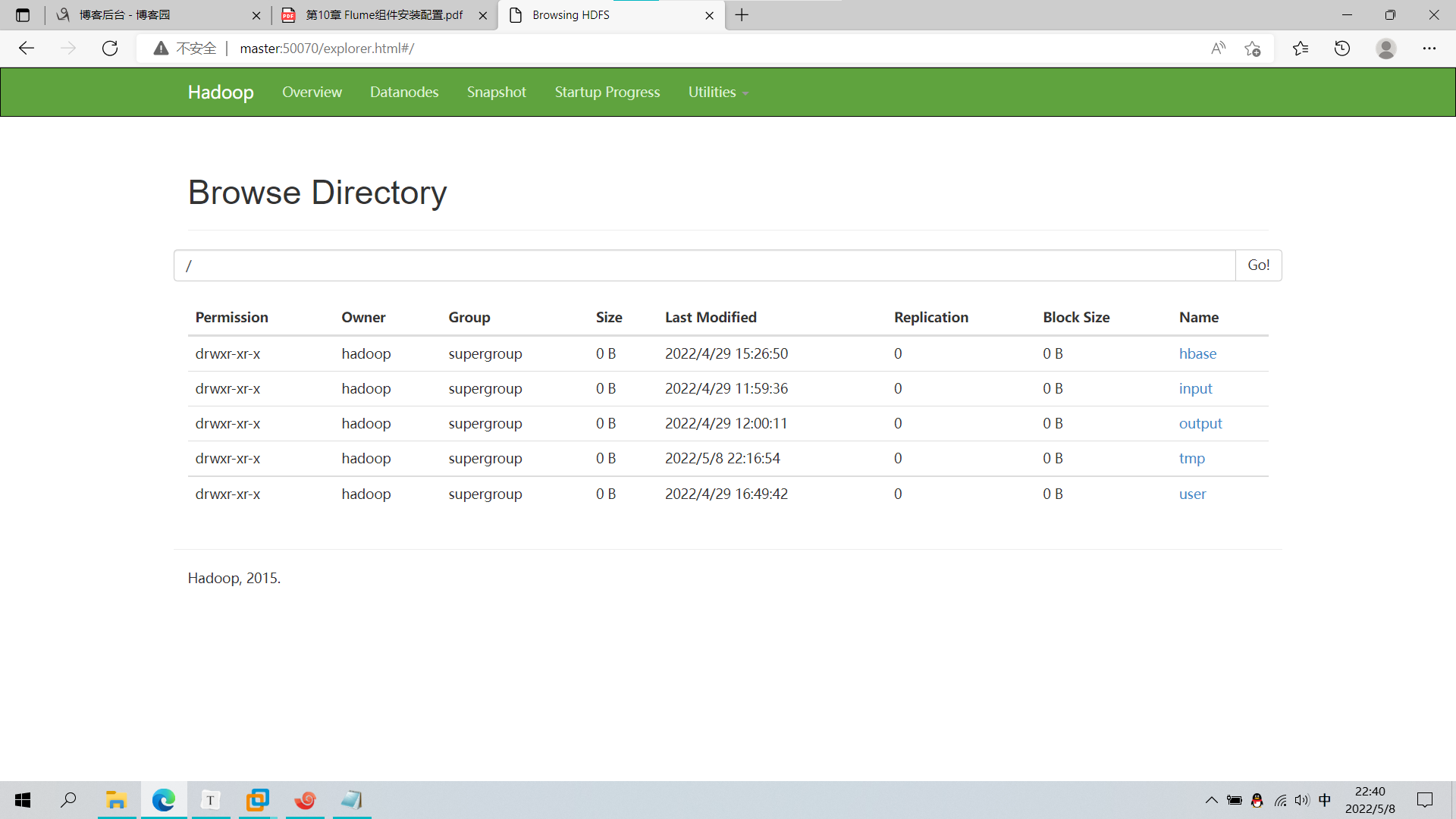
# 查看文件
[hadoop@master flume]$ hdfs dfs -ls /
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2022-04-29 15:26 /hbase
drwxr-xr-x - hadoop supergroup 0 2022-04-29 11:59 /input
drwxr-xr-x - hadoop supergroup 0 2022-04-29 12:00 /output
drwxr-xr-x - hadoop supergroup 0 2022-05-08 22:16 /tmp
drwxr-xr-x - hadoop supergroup 0 2022-04-29 16:49 /user
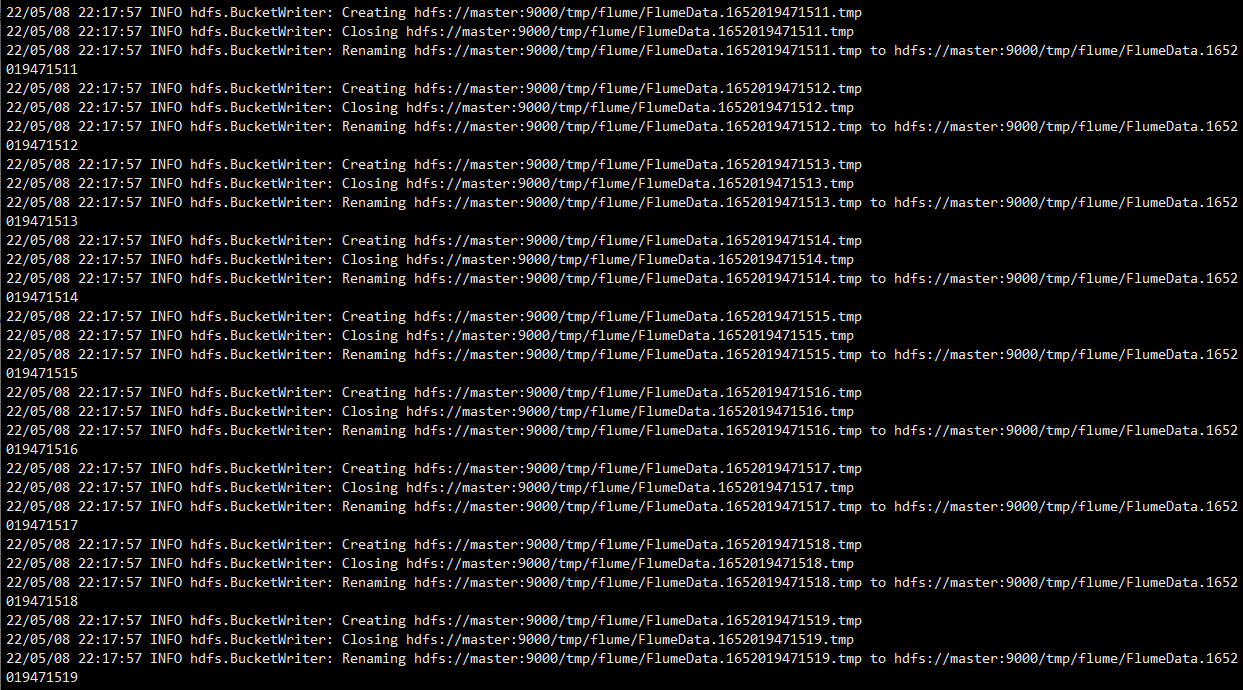
# 使用 flume-ng agent 命令加载 simple-hdfs-flume.conf 配置信息,启动 flume 传输数据
[hadoop@master flume]$ flume-ng agent --conf-file simple-hdfs-flume.conf --name a1
22/05/08 22:17:56 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471497.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471497.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471497.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471497
22/05/08 22:17:56 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471498.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471498.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471498.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471498
22/05/08 22:17:56 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471499.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471499.tmp
22/05/08 22:17:56 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471499.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471499
22/05/08 22:17:56 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471500.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471500.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471500.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471500
22/05/08 22:17:57 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471501.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471501.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471501.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471501
22/05/08 22:17:57 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471502.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471502.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471502.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471502
22/05/08 22:17:57 INFO hdfs.BucketWriter: Creating hdfs://master:9000/tmp/flume/FlumeData.1652019471503.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Closing hdfs://master:9000/tmp/flume/FlumeData.1652019471503.tmp
22/05/08 22:17:57 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/tmp/flume/FlumeData.1652019471503.tmp to hdfs://master:9000/tmp/flume/FlumeData.1652019471503
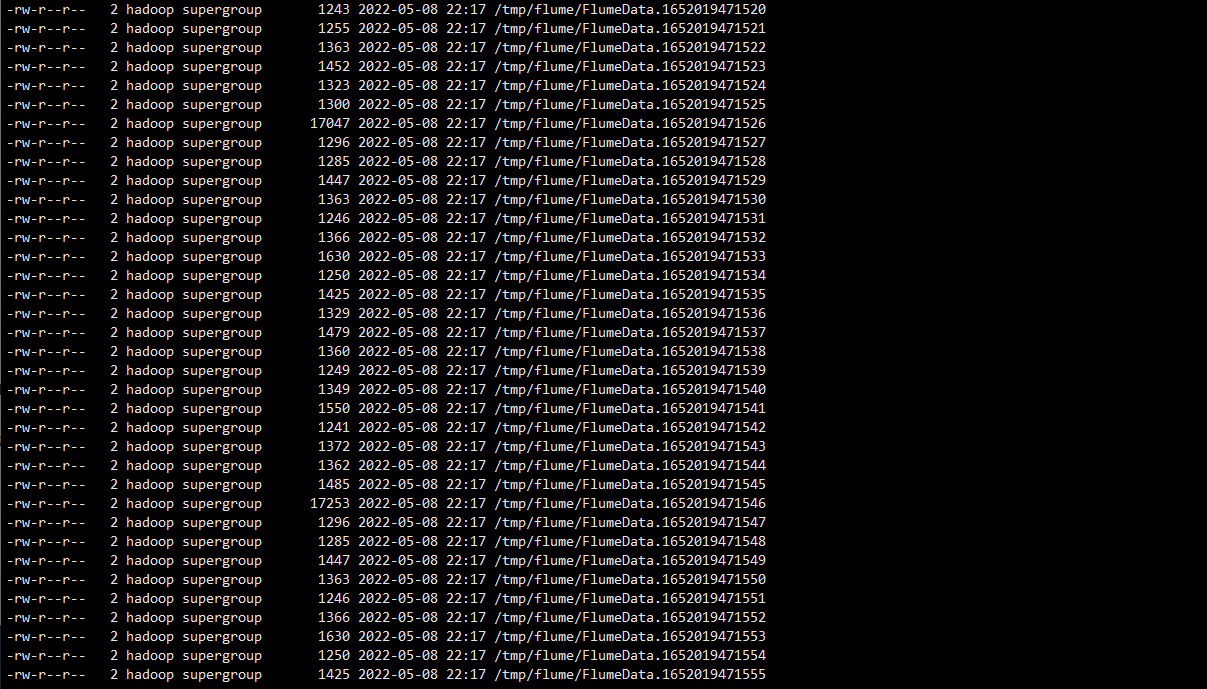
# 查看 Flume 传输到 HDFS 的文件
[hadoop@master flume]$ hdfs dfs -ls /tmp/flume
-rw-r--r-- 2 hadoop supergroup 1329 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471536
-rw-r--r-- 2 hadoop supergroup 1479 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471537
-rw-r--r-- 2 hadoop supergroup 1360 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471538
-rw-r--r-- 2 hadoop supergroup 1249 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471539
-rw-r--r-- 2 hadoop supergroup 1349 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471540
-rw-r--r-- 2 hadoop supergroup 1550 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471541
-rw-r--r-- 2 hadoop supergroup 1241 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471542
-rw-r--r-- 2 hadoop supergroup 1372 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471543
-rw-r--r-- 2 hadoop supergroup 1362 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471544
-rw-r--r-- 2 hadoop supergroup 1485 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471545
-rw-r--r-- 2 hadoop supergroup 17253 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471546
-rw-r--r-- 2 hadoop supergroup 1296 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471547
-rw-r--r-- 2 hadoop supergroup 1285 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471548
-rw-r--r-- 2 hadoop supergroup 1447 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471549
-rw-r--r-- 2 hadoop supergroup 1363 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471550
-rw-r--r-- 2 hadoop supergroup 1246 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471551
-rw-r--r-- 2 hadoop supergroup 1366 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471552
-rw-r--r-- 2 hadoop supergroup 1630 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471553
-rw-r--r-- 2 hadoop supergroup 1250 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471554
-rw-r--r-- 2 hadoop supergroup 1425 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471555
-rw-r--r-- 2 hadoop supergroup 1329 2022-05-08 22:17 /tmp/flume/FlumeData.1652019471556
……
# 若能查看到 HDFS 上/tmp/flume 目录有传输的数据文件,则表示数据传输成功。
使用 flume-ng agent 命令加载 simple-hdfs-flume.conf 配置信息
查看 Flume 传输到 HDFS 的文件:
浏览器查看:http://master:50070
查看文件:
声明:未经许可,不得转载
【Hadoop】10、Flume组件的更多相关文章
- Flume 组件安装配置
下载和解压 Flume 实验环境可能需要回至第四,五,六章(hadoop和hive),否则后面传输数据可能报错(猜测)! 可 以 从 官 网 下 载 Flume 组 件 安 装 包 , 下 载 地 址 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop生态圈-Flume的主流source源配置
Hadoop生态圈-Flume的主流source源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Source,想要了解更详细的配置信息请参 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- hadoop伪分布式组件安装
一.版本建议 Centos V7.5 Java V1.8 Hadoop V2.7.6 Hive V2.3.3 Mysql V5.7 Spark V2.3 Scala V2.12.6 Flume V1. ...
- Hadoop生态圈-Flume的主流Sinks源配置
Hadoop生态圈-Flume的主流Sinks源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Sinks,想要了解更详细的配置信息请参考官 ...
随机推荐
- List、Map、Set 三个接口存取元素时,各有什么特点?
List 以特定索引来存取元素,可以有重复元素.Set 不能存放重复元素(用对象的 equals()方法来区分元素是否重复).Map 保存键值对(key-value pair)映射, 映射关系可以是一 ...
- SpringCloud个人笔记-04-Stream初体验
sb_cloud_stream Spring Cloud Stream 是一个构建消息驱动微服务的框架 应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream ...
- Python中对象、类型、元类之间的关系
Python里的对象.类型和元类的关系很微妙也很有意思. 1989年圣诞节期间,上帝很无聊,于是创造了一个世界. 对象 在这个世界的运转有几条定律. 1.一切都是对象 对象(object)是这个世界的 ...
- CSDN博客步骤:
在SCDN看到喜欢的文章想转载又嫌一个一个敲太麻烦,干脆直接收藏.但有时候作者把原文章删除或设置为私密文章后又看不了.所以还是转载来的好.这篇博文为快速转载博客的方法,亲测有效,教程如下. 原博客原址 ...
- MOS管防反接电路设计
转自嵌入式单片机之家公众号 问题的提出 电源反接,会给电路造成损坏,不过,电源反接是不可避免的.所以,我们就需要给电路中加入保护电路,达到即使接反电源,也不会损坏的目的 01二极管防反接 通常情况下直 ...
- HTML5摇一摇(上)—如何判断设备摇动
刚刚过去的一年里基于微信的H5营销可谓是十分火爆,通过转发朋友圈带来的病毒式传播效果相信大家都不太陌生吧,刚好最近农历新年将至,我就拿一个"摇签"的小例子来谈一谈HTML5中如何调 ...
- python计算项目净现值和内部回报率
代码: import numpy as np from numpy import irr import warnings def project(number, period_list): rate ...
- 大数据学习之路之ambari配置(四)
试了很多遍,内存还是不够,电脑不太行的,不建议用ambari!!! 放弃了
- 大数据学习之路之ambari配置(三)
添加了虚拟机内存空间 重装ambari
- php 实验一 网页设计
实验目的: 1. 能够对整个页面进行html结构设计. 2. 掌握CSS+DIV的应用. 实验内容及要求: ***个人博客网页 参考Internet网上的博客网站,设计自己的个人网页,主要包括:图 ...