(一)使用sklearn做各种回归
#申明,本文章参考于 https://blog.csdn.net/yeoman92/article/details/75051848
import numpy as np
import matplotlib.pyplot as plt # 生成数据
def gen_data(x1, x2):
y = np.sin(x1) * 1/2 + np.cos(x2) * 1/2 + 0.1 * x1
return y def load_data():
x1_train = np.linspace(0, 50, 500)
x2_train = np.linspace(-10, 10, 500)
data_train = np.array([[x1, x2, gen_data(x1, x2) + np.random.random(1) - 0.5] for x1, x2 in zip(x1_train, x2_train)])
x1_test = np.linspace(0, 50, 100) + np.random.random(100) * 0.5
x2_test = np.linspace(-10, 10, 100) + 0.02 * np.random.random(100)
data_test = np.array([[x1, x2, gen_data(x1, x2)] for x1, x2 in zip(x1_test, x2_test)])
return data_train, data_test train, test = load_data()
# train的前两列是x,后一列是y,这里的y有随机噪声
x_train, y_train = train[:, :2], train[:, 2]
x_test, y_test = test[:, :2], test[:, 2] # 同上,但这里的y没有噪声 # 回归部分
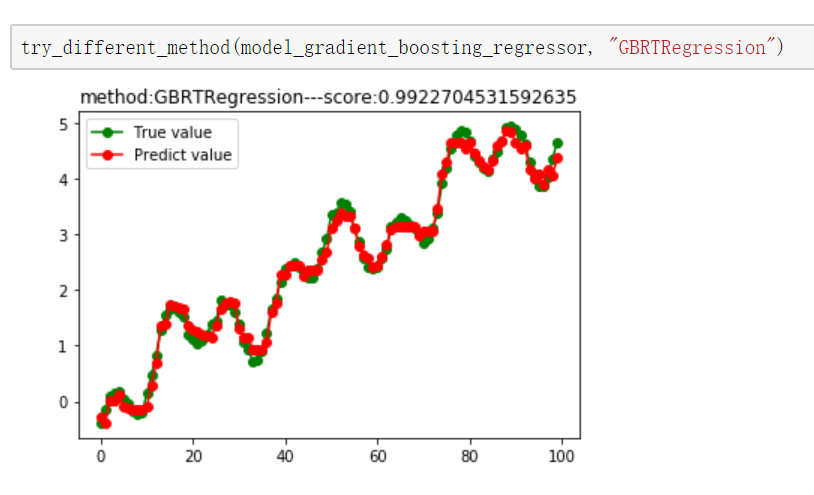
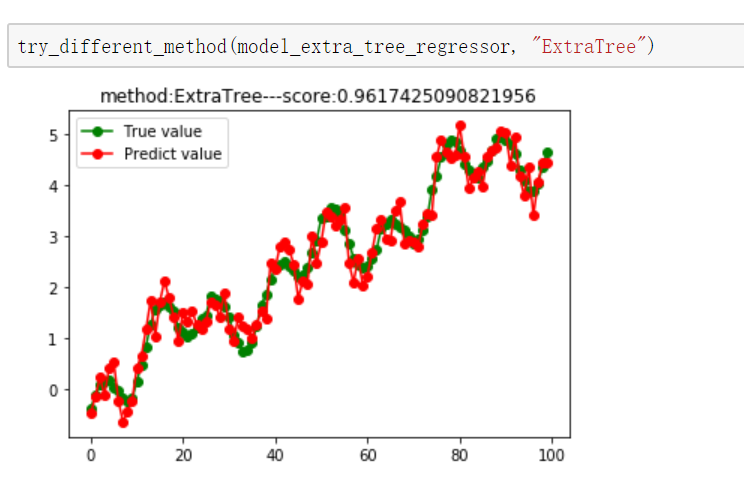
def try_different_method(model, method):
model.fit(x_train, y_train)
score = model.score(x_test, y_test)
result = model.predict(x_test)
plt.figure()
plt.plot(np.arange(len(result)), y_test, "go-", label="True value")
plt.plot(np.arange(len(result)), result, "ro-", label="Predict value")
plt.title(f"method:{method}---score:{score}")
plt.legend(loc="best")
plt.show() # 方法选择
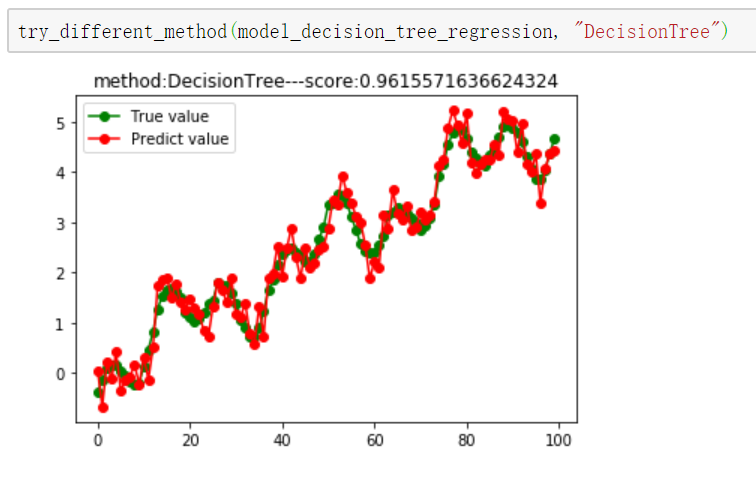
# 1.决策树回归
from sklearn import tree
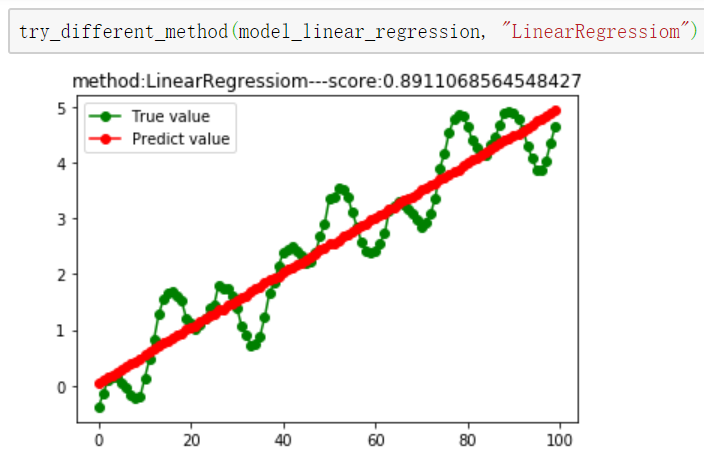
model_decision_tree_regression = tree.DecisionTreeRegressor() # 2.线性回归
from sklearn.linear_model import LinearRegression
model_linear_regression = LinearRegression() # 3.SVM回归
from sklearn import svm
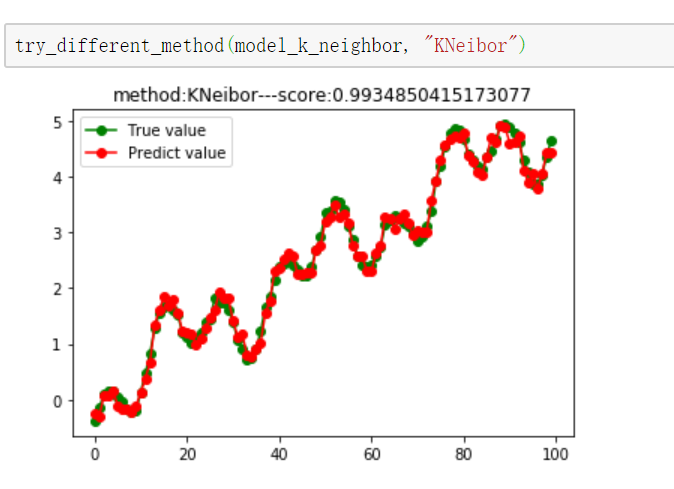
model_svm = svm.SVR() # 4.kNN回归
from sklearn import neighbors
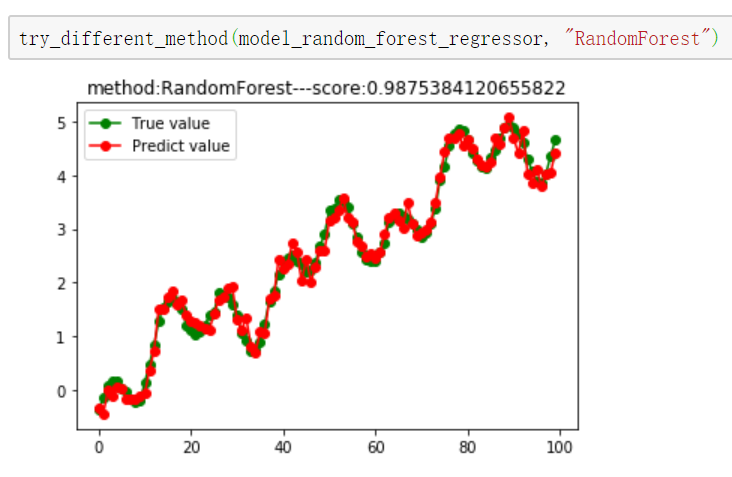
model_k_neighbor = neighbors.KNeighborsRegressor() # 5.随机森林回归
from sklearn import ensemble
model_random_forest_regressor = ensemble.RandomForestRegressor(n_estimators=20) # 使用20个决策树 # 6.Adaboost回归
from sklearn import ensemble
model_adaboost_regressor = ensemble.AdaBoostRegressor(n_estimators=50) # 这里使用50个决策树 # 7.GBRT回归
from sklearn import ensemble
model_gradient_boosting_regressor = ensemble.GradientBoostingRegressor(n_estimators=100) # 这里使用100个决策树 # 8.Bagging回归
from sklearn import ensemble
model_bagging_regressor = ensemble.BaggingRegressor() # 9.ExtraTree极端随机数回归
from sklearn.tree import ExtraTreeRegressor
model_extra_tree_regressor = ExtraTreeRegressor()


(一)使用sklearn做各种回归的更多相关文章
- Sklearn实现逻辑回归
方法与参数 LogisticRegression类的各项参数的含义 class sklearn.linear_model.LogisticRegression(penalty='l2', dual=F ...
- 【转】使用sklearn做特征工程
1 特征工程是什么? 有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已.那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中 ...
- 使用sklearn做单机特征工程(Performing Feature Engineering Using sklearn)
本文转载自使用sklearn做单机特征工程 目录 目录 特征工程是什么 数据预处理 1 无量纲化 11 标准化 12 区间缩放法 13 标准化与归一化的区别 2 对定量特征二值化 3 对定性特征哑编码 ...
- 【导包】使用Sklearn构建Logistic回归分类器
官方英文文档地址:http://scikit-learn.org/dev/modules/generated/sklearn.linear_model.LogisticRegression.html# ...
- [特征工程]-------使用sklearn做单机特征工程[转载]
https://www.cnblogs.com/jasonfreak/p/5448385.html 使用sklearn做单机特征工程 目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1 ...
- sklearn调用逻辑回归算法
1.逻辑回归算法即可以看做是回归算法,也可以看作是分类算法,通常用来解决分类问题,主要是二分类问题,对于多分类问题并不适合,也可以通过一定的技巧变形来间接解决. 2.决策边界是指不同分类结果之间的边界 ...
- Python机器学习笔记 使用sklearn做特征工程和数据挖掘
特征处理是特征工程的核心部分,特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样式确定的步骤,更多的是工程上的经验和权衡,因此没有统一的方法,但是sklearn提供了较为完整的特征处 ...
- 使用sklearn做单机特征工程
目录 1 特征工程是什么?2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 标准化与归一化的区别 2.2 对定量特征二值化 2.3 对定性特征哑编码 2.4 缺 ...
- 【转】使用sklearn做单机特征工程
这里是原文 说明:这是我用Markdown编辑的第一篇随笔 目录 1 特征工程是什么? 2 数据预处理 2.1 无量纲化 2.1.1 标准化 2.1.2 区间缩放法 2.1.3 无量纲化与正则化的区别 ...
随机推荐
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤:1.分类,识别物体是什么 2.定位,找出物体在哪里 除了对单个物体进行检测,还要能支持 ...
- Android学习笔记(四)之碎片化Fragment实现仿人人客户端的侧边栏
其实一种好的UI布局,可以使用户感到更加的亲切与方便.最近非常流行的莫过于侧边栏了,其实我也做过很多侧边栏的应用,但是那些侧边栏的使用我 都不是很满意,现在重新整理,重新写了一个相对来说我比较满意的侧 ...
- 《Cracking the Coding Interview》——第5章:位操作——题目6
2014-03-19 06:24 题目:将一个整数的奇偶二进制位交换,(0, 1) (2, 3) ... 解法:使用掩码来进行快速交换,定义掩码为'0101...'和‘1010...’. 代码: // ...
- 【Decision Tree】林轩田机器学习技法
首先沿着上节课的AdaBoost-Stump的思路,介绍了Decision Tree的路数: AdaBoost和Decision Tree都是对弱分类器的组合: 1)AdaBoost是分类的时候,让所 ...
- Jetty 安装、启动与项目部署
Jetty是当下非常流行的一款轻量级Java Web服务器和Servlet容器实现,它由Eclipse基金会托管,完全免费而且开放源代码,因此所有人均可以从其官网下载最新源代码进行研究.由于其轻量.灵 ...
- day06_07 字典操作02
1.0 删_del dic5 = {'age':18,'name':'alex','hobby':'girl'} del dic5['name'] #删除键值对 print(dic5) #>&g ...
- NOIP2018 集训(一)
A题 Simple 时间限制:1000ms | 空间限制:256MB 问题描述 对于给定正整数\(n,m\),我们称正整数\(c\)为好的,当且仅当存在非负整数\(x,y\)使得\(n×x+m×y=c ...
- 孤荷凌寒自学python第二十六天python的time模块的相关方法
孤荷凌寒自学python第二十六天python的time模块的相关方法 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 要使用time模块的相关方法,必须在文件顶端引用: import tim ...
- Windows添加自定义服务、批处理文件开机自启动方法
[Windows 添加自定义服务方法]: 1.使用Windows服务工具instsrv.exe与srvany.exe: 参考:https://wenku.baidu.com/view/44a6e6f8 ...
- css background-size与背景图片填满div
background-size与背景图片填满div 在开发中,常有需要将一张图片作为一个div的背景图片充满div的需求 background-size的取值及解释 background-size共有 ...