Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下.
目标: https://maoyan.com/board/1
问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字符, 且网页源码中该类数字均被 . 之类的字符串代替.

解决:
出现这种情况的原因是因为网页字体是在 CSS3 @font-face 规则中定义的, 我觉得这种字体就类似描点连线那种方式绘制出来的.
因为定义规则是动态随机获取的, 不能保证每次都是一个字体文件.
如下:


可以看到, 同一数字所对应的字符是不一样的, 所以我们也就动态下载实时字体文件, 具体分析.
虽然每次对应的字符可能不一样, 但是可以发现同一数字的字形是一样的, 也就是"描点的坐标"应该相同.
事实证明在这个例子中是确实如此.
如下:
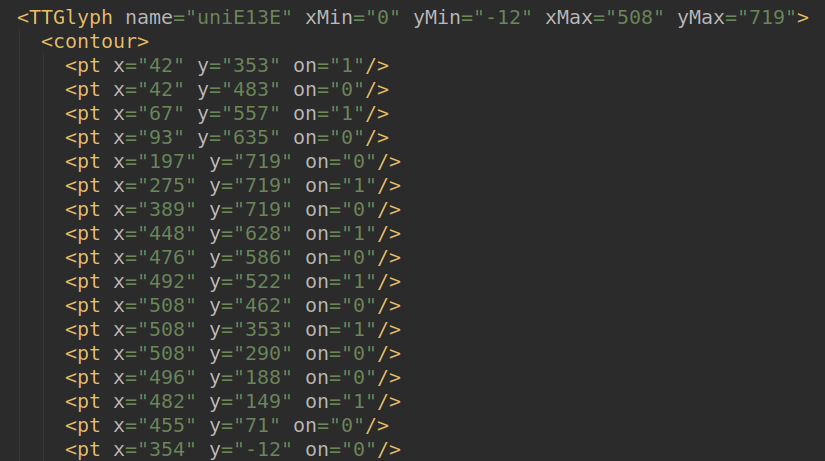
同一数字对象里的这些值是一样的.
既然找到问题所在和规律了, 就可以直接开始写代码了.
import re
from urllib.request import urlretrieve, urlopen
from fontTools.ttLib import TTFont def process_font(url):
# loc.woff是事先下载好的字体文件
# 可以通过font1.saveXML()来了解文件的结构, font1就像一个的字典, XML文件里的tag可以对font1用字典的方法获取
font1 = TTFont('loc.woff')
# 使用百度的FontEditor手动确认本地字体文件name和数字之间的对应关系, 保存到字典中
loc_dict = {'uniE8B2': '', 'uniF818': '', 'uniECCC': '', 'uniE622': '', 'uniEC92': '', 'uniF31A': '',
'uniE86D': '', 'uniE33C': '', 'uniE1FA': '', 'uniE13E': ''}
# 获取字符的name列表, 打印出来后发现第一个和最后一个name所对应的不是数字, 所以切片
uni_list1 = font1.getGlyphNames()[1: -1] # 网页源码
rsp = urlopen(url).read().decode()
# 获取动态的字体文件并下载
font_url = 'http://' + re.findall(r'url\(\'//(.*?\.woff)', rsp)[0]
# web字体文件落地名
filename = font_url.split('/')[-1]
# 下载web字体文件
urlretrieve(font_url, filename) # 打开web字体文件
font2 = TTFont(filename)
# 获取字符的name列表
uni_list2 = font2.getGlyphNames()[1: -1] # web字体文件中name和num映射
new_map = {} for uni2 in uni_list2:
# 获取name 'uni2' 在font2中对应的对象
obj2 = font2['glyf'][uni2]
for uni1 in uni_list1:
# 获取name 'uni1' 在font1中对应的对象
obj1 = font1['glyf'][uni1]
# 如果两个对象相等, 说明对应的数字一样
if obj1 == obj2:
# 将name键num值对加入new_map
new_map[uni2] = loc_dict[uni1] # 将数字替换至源码
for i in uni_list2:
pattern = '&#x' + i[3:].lower() + ';'
rsp = re.sub(pattern, new_map[i], rsp) # 返回处理处理后的源码
return rsp if __name__ == '__main__':
# 猫眼国内实时票房top10
url = 'https://maoyan.com/board/1'
# 替换数字后的网页源码
res = process_font(url)
代码里loc.woff文件是先下载好的, 通过它找到数字和"描点坐标"之间的对应关系. 这个文件大家可以自己提前下载, 并且手动找到对应关系.
这里也提供了我下载的loc.woff文件, https://github.com/ysl125963/maoyan, 里面的font.xml文件就是通过saveXML()方法得到的, 可以看到字体文件的具体结构.
这是第一次写分享博客, 而且github也没怎么用过, 希望以后能坚持吧.
Python爬虫-字体反爬-猫眼国内票房榜的更多相关文章
- python爬虫---字体反爬
目标地址:http://glidedsky.com/level/web/crawler-font-puzzle-1 打开google调试工具检查发现网页上和源码之中的数字不一样, 已经确认该题目为 字 ...
- python解析字体反爬
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码.这种一般是网站设置了字体反爬 一.58同城 用谷歌浏览器打开 ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- python爬虫--cookie反爬处理
Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长 ...
- Python爬虫实战——反爬策略之代理IP【无忧代理】
一般情况下,我并不建议使用自己的IP来爬取网站,而是会使用代理IP. 原因很简单:爬虫一般都有很高的访问频率,当服务器监测到某个IP以过高的访问频率在进行访问,它便会认为这个IP是一只"爬虫 ...
- Python 爬虫练习(一) 爬取国内代理ip
简单的正则表达式练习,爬取代理 ip. 仅爬取前三页,用正则匹配过滤出 ip 地址和 端口,分别作为key.value 存入 validip 字典. 如果要确定代理 ip 是否真的可用,还需要再对代理 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
随机推荐
- scrapy框架的命令行解释
scrapy框架的命令解释 创建爬虫项目 scrapy startproject 项目名例子如下: scrapy startproject test1 这个时候爬虫的目录结构就已经创建完成了,目录结构 ...
- 牛客寒假6-D.美食
链接:https://ac.nowcoder.com/acm/contest/332/D 题意: 小B喜欢美食. 现在有n个美食排成一排摆在小B的面前,依次编号为1..n,编号为i的食物大小为 a[i ...
- morphia(6-1)-查询
1.filter morphia语法: query.filter("price >=", 1000); mongodb语法: { price: { $gte: 1000 } ...
- StretchDIBits速度测试(COLORONCOLOR)
下面是一个测试程序,源码下载
- OS 内存泄漏 导致 整个aix主机block
问题 aix 主机 1.数据库主机使用vmstat 监控,隔几分钟 就是block 爆满. cpu 没有瓶颈,I/O 显示本地磁盘hdisk0和hdisk 1 是爆满. vmstat 同时显示大量pa ...
- E. The Best among Equals
http://codeforces.com/gym/101149/problem/E 这题的话,关键是注意到一定是要max score 然后就可以选出一个L最大优先,并且R最大的区间, 扫一次就能得到 ...
- [转]Cordova android框架详解
本文转自:http://www.cnblogs.com/hubcarl/p/4202784.html 一.Cordova 核心java类说明 CordovaActivity:Cordova Activ ...
- puppeteer 中国区的使用
puppeteer 中国区的使用 [issues]https://github.com/GoogleChrome/puppeteer/issues/1426 两种方案 使用 cnpm .npmrc 中 ...
- BundleConfig包含js,css失败
今天在做mvc项目的时候,引入了bootstrap样式.但是包含css和js的时候出错了 于是我查阅资料,好多人都说后缀名前面不能包含".",于是我把min前面的".&q ...
- 浅析ES6中的iterator
1.iterator迭代器必须保证其遍历终止条件可控,否则会形成死循环demo: //会用到iterator接口的场合 //1.for...of循环 //2. ...解构表达式 const obj = ...