ES BM25 TF-IDF相似度算法设置——
Before we move on from relevance and scoring, we will finish this chapter with a more advanced subject: pluggable similarity algorithms. While Elasticsearch uses the Lucene’s Practical Scoring Function as its default similarity algorithm, it supports other algorithms out of the box, which are listed in the Similarity Modules documentation.
Okapi BM25
The most interesting competitor to TF/IDF and the vector space model is called Okapi BM25, which is considered to be a state-of-the-art ranking function. BM25 originates from the probabilistic relevance model, rather than the vector space model, yet the algorithm has a lot in common with Lucene’s practical scoring function.
Both use term frequency, inverse document frequency, and field-length normalization, but the definition of each of these factors is a little different. Rather than explaining the BM25 formula in detail, we will focus on the practical advantages that BM25 offers.
Term-frequency saturation
Both TF/IDF and BM25 use inverse document frequency to distinguish between common (low value) words and uncommon (high value) words. Both also recognize (see Term frequency) that the more often a word appears in a document, the more likely is it that the document is relevant for that word.
However, common words occur commonly. The fact that a common word appears many times in one document is offset by the fact that the word appears many times in all documents.
However, TF/IDF was designed in an era when it was standard practice to remove the most common words (or stopwords, see Stopwords: Performance Versus Precision) from the index altogether. The algorithm didn’t need to worry about an upper limit for term frequency because the most frequent terms had already been removed.
In Elasticsearch, the standard analyzer—the default for string fields—doesn’t remove stopwords because, even though they are words of little value, they do still have some value. The result is that, for very long documents, the sheer number of occurrences of words like the and and can artificially boost their weight.
BM25, on the other hand, does have an upper limit. Terms that appear 5 to 10 times in a document have a significantly larger impact on relevance than terms that appear just once or twice. However, as can be seen in Figure 34, “Term frequency saturation for TF/IDF and BM25”, terms that appear 20 times in a document have almost the same impact as terms that appear a thousand times or more.
This is known as nonlinear term-frequency saturation.
Figure 34. Term frequency saturation for TF/IDF and BM25
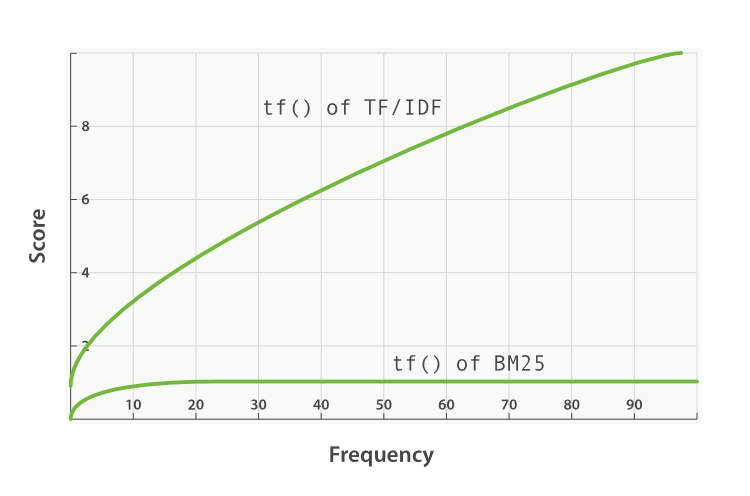
Field-length normalization
In Field-length norm, we said that Lucene considers shorter fields to have more weight than longer fields: the frequency of a term in a field is offset by the length of the field. However, the practical scoring function treats all fields in the same way. It will treat all title fields (because they are short) as more important than all body fields (because they are long).
BM25 also considers shorter fields to have more weight than longer fields, but it considers each field separately by taking the average length of the field into account. It can distinguish between a shorttitle field and a long title field.
In Query-Time Boosting, we said that the title field has a natural boost over the bodyfield because of its length. This natural boost disappears with BM25 as differences in field length apply only within a single field.
ES BM25 TF-IDF相似度算法设置——的更多相关文章
- ES 相似度算法设置(续)
Tuning BM25 One of the nice features of BM25 is that, unlike TF/IDF, it has two parameters that allo ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- ES设置查询的相似度算法
similarity Elasticsearch allows you to configure a scoring algorithm or similarity per field. The si ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
随机推荐
- 【Python】列表~深入篇
列表是一列按特定顺序排列的元素组成. 在Python中,用方括号[]来表示列表 下面是一个语言列表 Language = ['Chinese','English','Franch','Deutsch' ...
- Linux在中国正在走向没落
在中国,Linux正在走向没落,一片萧条景象. 在这样的大背景下.居然有人愿意接手中科红旗,令人佩服! 在中国,没有一个关于国际Linux的官方刊物(或站点)反映国际Linux运动的真实声音.Linu ...
- 安装gi的时候回退root.sh的运行
</pre><pre name="code" class="html">/u01/app/11.2.0/grid/crs/install ...
- Java获取系统属性及环境变量
当程序中需要使用与操作系统相关的变量(例如:文件分隔符.换行符)时,Java提供了System类的静态方法getenv()和getProperty()用于返回系统相关的变量与属性,getenv方法返回 ...
- jQuery--基础(实例)
jQuery的操作方法并不需要都记下来,但是使用什么功能需要什么样的方法,我们是一定会知道的.所以写实例来进行对功能方法的练习和熟练,是最快能够掌握jQuery的方法. <!DOCTYPE ht ...
- gulp入门-压缩js/css文件(windows)
类似于grunt,都是基于Node.js的前端构建工具.不过gulp压缩效率更高. 工具/原料 nodejs/npm 方法/步骤 首先要确保pc上装有node,然后在global环境和项目文件中都in ...
- Hibernate demo之使用xml
1.新建maven项目 testHibernate,pom.xml <?xml version="1.0" encoding="UTF-8"?> & ...
- golang生成随机函数的实现
golang生成随机数可以使用math/rand包, 示例如下: package main import ( "fmt" "math/rand" ) func ...
- JAVA解析XML之DOM方式
JAVA解析XML之DOM方式 准备工作 创建DocumentBuilderFactory对象; 创建DocumentBuilder对象; 通过DocumentBuilder对象的parse方法 ...
- 【WinForm】创建自定义控件(转)
转自:http://www.cnblogs.com/bomo/archive/2012/12/09/2810559.html 虽然VS为我们提供了很多控件可以使用,但有时候这些控件仍然不能满足我们的要 ...