推荐系统实践 0x0f AutoRec
从这一篇开始,我们开始学习深度学习推荐模型,与传统的机器学习相比,深度学习模型的表达能力更强,并且更能够挖掘出数据中潜藏的模式。另外。深度学习模型结构也非常灵活,能够根据业务场景和数据结构进行调整。还是原来的样子,我会按照原理以及代码实现,再就是一些优缺点进行逐一介绍。
AutoRec
AutoRec可以说是最小的深度学习推荐系统了,它是一种单隐层神经网络推荐模型,将自编码器与协同过滤相结合。那么什么是自编码器呢?自编码器可以看做是一种压缩维度的工具,无论是图像、音频、还是文本,都能够通过自编码器转换成向量形式进行表达,假设我们的输入(无论是图像、音频等等)的数据向量是\(r\),那么希望通过自编码器的输出向量尽可能接近原来的数据输入\(r\)。
假设自编码器的重建函数是\(h(r;\theta)\),那么自编码器的目标函数是:
\]
其中的\(S\)就是所有数据输入的向量结合。
一般来说,重建函数\(h(r;\theta)\)的参数量远远小于输入向量的维度,所以自编码器相当于完成了数据压缩和降维的工作。并且,通过自编码器生成的输出向量,使得自编码器的编码过程有一定的泛化能力,可以预测丢失的维度信息,这也是自编码器能够用于推荐系统的原因。
模型结构
在之前的文章中我们介绍了协同过滤的关键——共现矩阵。就是因为由\(m\)个用户以及\(n\)的物品形成的\(m\times n\)的共现矩阵维度太高,所以我们需要使用一个重建函数对共现矩阵里面的评分向量进行压缩,然后经过评分预估以及排序之后形成最终的排序列表。AutoRec使用了单隐层神经网络结构来实现自编码器的功能。如下图所示。
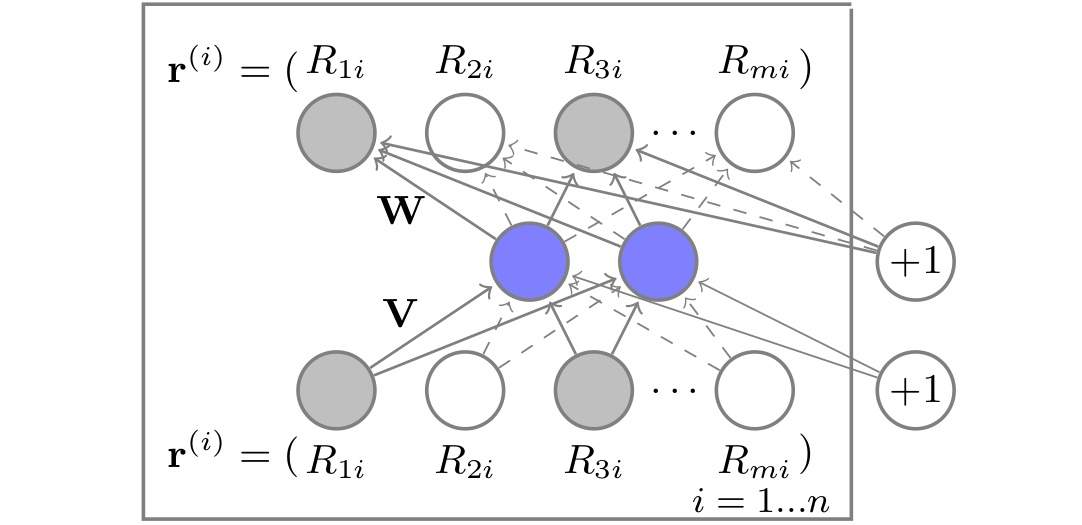
蓝色神经元代表模型的\(k\)维单隐层,也就是压缩之后的向量,\(V\)以及\(W\)代表从输入到隐层、从隐层到输出层的参数矩阵。那么写成重建函数的形式就是
\]
\(f(\cdot)\)以及\(g(\cdot)\)为输出层和隐层神经元的激活函数。为了防止重构函数(单隐层神经网络、或者说三层神经网络)的过拟合,再加上\(L2\)正则化项,那么AutoRec的目标函数就是
\]
\(||\cdot||_F\)为Frobenius范数.
推荐过程
当输入物品\(i\)的评分向量\(r^{(i)}\)时,得到的模型输出向量\(h(r;\theta)\)就是所有用户对物品\(i\)的评分预测。其中第\(u\)维就是用户\(u\)对物品\(i\)的预测评分\(\hat{R}_{ui}\)。那么再遍历一遍物品向量就可以得到该用户对所有物品的评分预测,然后进行排序就可以得到推荐列表。这种以物品评分向量作为输入的被称为I-AutoRec(Item based AutoRec),另外一种就是以用户评分向量作为输入的就是U-AutoRec(User based AutoRec)。U-Auto相比较于I-Auto优势是仅输入一次目标用户的用户向量就可以重建用户对所有物品的评分向量,也就是说仅需一次推断就可以得到用户的推荐列表,但是用户向量的稀疏性可能会影响模型推荐效果。
局限性
无法进行特征交叉,表达能力相对于后面更复杂的深度学习模型还是表达能力不足。由于AutoRec的简单明了,作为入门的深度学习推荐模型再合适不过了。
代码
## 模型部分
class Autorec(nn.Module):
def __init__(self,args, num_items):
super(Autorec, self).__init__()
self.args = args
#self.num_users = num_users
self.num_items = num_items
self.hidden_units = args.hidden_units
self.lambda_value = args.lambda_value
self.encoder = nn.Sequential(
nn.Linear(self.num_items, self.hidden_units),
nn.Sigmoid()
)
self.decoder = nn.Sequential(
nn.Linear(self.hidden_units, self.num_items),
)
def forward(self,torch_input):
encoder = self.encoder(torch_input)
decoder = self.decoder(encoder)
return decoder
## 损失函数部分
def loss(self, decoder, input, optimizer, mask_input):
cost = 0
temp2 = 0
cost += ((decoder - input) * mask_input).pow(2).sum()
rmse = cost
for i in optimizer.param_groups:
for j in i['params']:
# print(type(j.data), j.shape,j.data.dim())
if j.data.dim() == 2:
temp2 += torch.t(j.data).pow(2).sum()
cost += temp2 * self.lambda_value * 0.5
return cost, rmse
参考
AutoRec: Autoencoders Meet Collaborative Filtering
Github:NeWnIx5991/AutoRec-for-CF
推荐系统实践 0x0f AutoRec的更多相关文章
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
- zz京东电商推荐系统实践
挺实在 今天为大家分享下京东电商推荐系统实践方面的经验,主要包括: 简介 排序模块 实时更新 召回和首轮排序 实验平台 简介 说到推荐系统,最经典的就是协同过滤,上图是一个协同过滤的例子.协同过滤主要 ...
- 推荐系统实践 0x07 基于邻域的算法(2)
基于邻域的算法(2) 上一篇我们讲了基于用户的协同过滤算法,基本流程就是寻找与目标用户兴趣相似的用户,按照他们对物品喜好的对目标用户进行推荐,其中哪些相似用户的评分要带上目标用户与相似用户的相似度作为 ...
- 推荐系统实践 0x0b 矩阵分解
前言 推荐系统实践那本书基本上就更新到上一篇了,之后的内容会把各个算法拿来当专题进行讲解.在这一篇,我们将会介绍矩阵分解这一方法.一般来说,协同过滤算法(基于用户.基于物品)会有一个比较严重的问题,那 ...
- 推荐系统实践 0x09 基于图的模型
用户行为数据的二分图表示 用户的购买行为很容易可以用二分图(二部图)来表示.并且利用图的算法进行推荐.基于邻域的模型也可以成为基于图的模型,因为基于邻域的模型都是基于图的模型的简单情况.我们可以用二元 ...
- Spark推荐系统实践
推荐系统是根据用户的行为.兴趣等特征,将用户感兴趣的信息.产品等推荐给用户的系统,它的出现主要是为了解决信息过载和用户无明确需求的问题,根据划分标准的不同,又分很多种类别: 根据目标用户的不同,可划分 ...
- 基于Neo4j的个性化Pagerank算法文章推荐系统实践
新版的Neo4j图形算法库(algo)中增加了个性化Pagerank的支持,我一直想找个有意思的应用来验证一下此算法效果.最近我看Peter Lofgren的一篇论文<高效个性化Pagerank ...
- 推荐系统实践 0x05 推荐数据集MovieLens及评测
推荐数据集MovieLens及评测 数据集简介 MoiveLens是GroupLens Research收集并发布的关于电影评分的数据集,规模也比较大,为了让我们的实验快速有效的进行,我们选取了发布于 ...
- 推荐系统实践 0x06 基于邻域的算法(1)
基于邻域的算法(1) 基于邻域的算法主要分为两类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法.我们首先介绍基于用户的协同过滤算法. 基于用户的协同过滤算法(UserCF) 基于用户的 ...
随机推荐
- abp(net core)+easyui+efcore实现仓储管理系统——出库管理之六(五十五)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统--ABP总体介绍(一) abp(net core)+ ...
- php 把一个数随机分成n份
$money_total=100; $personal_num=10; $min_money=0.01; $money_right=$money_total; $randMoney=[]; for($ ...
- python-基础入门-7基础
1.语法和语句 Python中有一些基本规则和特殊字符 1)#符号之后的表示注释 2)\n符号表示换行 3)\继续上一行的内容 推荐使用括号,这样可读性更好 4):将两个语句链接在一行中 类似于c语言 ...
- RabbitMQ+Redis模拟手机验证码登录
RabbitMQ+Redis模拟手机验证码登录 依赖 <dependency> <groupId>org.springframework.boot</groupId> ...
- 一个神奇的bug:OOM?优雅终止线程?系统内存占用较高?
摘要:该项目是DAYU平台的数据开发(DLF),数据开发中一个重要的功能就是ETL(数据清洗).ETL由源端到目的端,中间的业务逻辑一般由用户自己编写的SQL模板实现,velocity是其中涉及的一种 ...
- JAVA中删除文件夹下及其子文件夹下的某类文件
##定时删除拜访图片 ##cron表达式 秒 分 时 天 月 ? ##每月1日整点执行 CRON1=0 0 0 1 * ? scheduled.enable1=false ##图片路径 filePat ...
- Django的model.py
什么是ORM? 对象关系映射 类 >>> 表 对象 >>> 表记录 对象的属性 >>> 一条记录某个字段对应的值 django的orm不能够自动帮 ...
- C#(二)基础篇—操作符
2020-12-02 本随笔为个人复习巩固知识用,多从书上总结与理解得来,如有错误麻烦指正 1.数学操作符 int a=2,b=3,c=0; float d=0; c=a+b; //c=5 c++; ...
- 创建实验楼课程app模块以及配置图片路径
1.创建course模型 1.1 创建用户模型course python ../manage.py startapp course # 创建course模型 1.2 在setting.py中注册cou ...
- CPU实现原子操作的原理
586之前的CPU, 会通过LOCK锁总线的形式来实现原子操作. 686开始则提供了存储一致性(Cache coherence), 这是多处理的基础, 也是原子操作的基础. 1. 存储的粒度 存储的 ...