Group by后加rollup、cube、Grouping_Sets的用法区别
一、相关分析
通常当聚合率和数据量没有大于一定程度时,对于不涉及Rollup、Cube、Grouping_Sets这三种操作的聚合很少出现GC问题。对于Rollup、Cube、Grouping_Sets操作可采用如下优化方法避免GC。
1、Rollup / Cube / Grouping_Sets时,某些场景下,如果多维度的字段比较多,内存或者GC会造成性能问题。特别的, 在实现这三种操作 时, 记录数会出现倍数的膨胀, 调优的时候请务必关注 GC 情况。 如果 GC性能情况表现不加, 建议用手动改动的方式调优, 通常是把这三种操作等价的用 UNION 多个子查询 SQL 的方式实现。 对 SQL 改写相当于是对它们计算内容的同语义翻译。
1、1Rollup的改写

对它等价的拆分改写结果如下,上下两个语句的结果相同:

1、2Cube改写


可以看出前三个的Union块的结果等同于一个Cube,所以还可以改写为

1、3Grouping Sets的改写

对它等价的拆分改写结果如下,上下两个语句的结果相同:

总结:可以按照以上所示的对三种操作的改写形式对语句展开优化,尽可能的减少因内存和GC引发的性能问题。但是,一般情况下,如果GC问题不是特别严重,就不用改写,否则会导致性能更差。
二、对比Group by、Cube、Rollup
-1、创建表
CREATE TABLE employee_part(department STRING,name STRING,salary int)
CLUSTERED BY (department) INTO 7 BUCKETS
STORED AS ORC
tblproperties('transactional'='true');
--2、入数据
insert into employee_part values('A','ZHANG',100);
insert into employee_part values('A','LI',200);
insert into employee_part values('A','WANG',300);
insert into employee_part values('A','DUAN',500);
insert into employee_part values('B','DUAN',600 );
insert into employee_part values('B','DUAN',700);
insert into employee_part values('A','ZHAO',400);
--3、Group by
SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY department,name;
--4、Rollup
SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Rollup(department,name);
等价于
SELECT department,name,sum(salary)AS sum
FROM employee_part
GROUP BY department,name
union
SELECT department,'NULL',SUM(salary)AS sum
FROM employee_part
GROUP BY department
union
SELECT 'NULL','NULL',SUM(salary)AS sum
FROM employee_part;
--5、CUBE
SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Cube(department,name);
等价于
SELECT department,name,sum(salary)AS sum
FROM employee_part
GROUP BY department,name
union
SELECT department,'NULL',SUM(salary)AS sum
FROM employee_part
GROUP BY department
union
SELECT 'NULL','NULL',SUM(salary)AS sum
FROM employee_part
UNION
SELECT 'NULL', name, SUM(Salary) AS sum
FROM employee_part
GROUP BY name;
等价于
SELECT department,name,sum(salary)AS sum FROM employee_part GROUP BY Rollup(department,name)
UNION
SELECT 'NULL', name, SUM(Salary) AS sum
FROM employee_part
GROUP BY name;
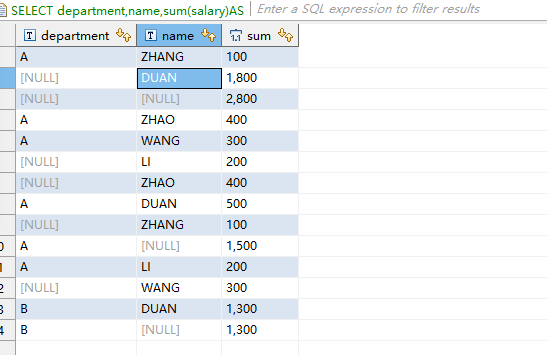
可以看出CUBE的结果集在Rollup结果集上多出了5行,这5行相当于在Rollup结果集上再union上以员工名字为group by 的结果。
Group by后加rollup、cube、Grouping_Sets的用法区别的更多相关文章
- [转]group by 后使用 rollup 子句总结
group by 后使用 rollup 子句总结 一.如何理解group by 后带 rollup 子句所产生的效果 group by 后带 rollup 子句的功能可以理解为:先按一定的规则产生多种 ...
- SQL GROUP BY GROUPING SETS,ROLLUP,CUBE(需求举例)
实现按照不同级别分组统计 关于GROUP BY 中的GROUPING SETS,ROLLUP,CUBE 从需求的角度理解会更加容易些. 需求举例: 假如一所学校只有两个系, 每个系有两个专业, 每个专 ...
- 【转】new对象时,类名后加括号和不加括号的区别
请看测试代码: #include <iostream> using namespace std; // 空类 class empty { }; // 一个默认构造函数,一个自定义构造函数 ...
- new对象时,类名后加括号与不加括号的区别
[1]默认构造函数 关于默认构造函数,请参见随笔<类中函数> 请看测试代码: 1 #include <iostream> 2 using namespace std; 3 4 ...
- Oracle分析函数 — sum, rollup, cube, grouping用法
本文通过例子展示sum, rollup, cube, grouping的用法. //首先建score表 create table score( class nvarchar2(20), course ...
- rollup&&cube
group by 擴展 rollup&&cube --按job分組計算不同job的匯總工資 SELECT job, SUM (sal) FROM emp GROUP BY ...
- GROUP BY中ROLLUP/CUBE/GROUPING/GROUPING SETS使用示例
oracle group by中rollup和cube的区别: Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句.CUBE ROLLUP 是用于统计数据的. 实验 ...
- SQL Server2008 程序设计 汇总 GROUP BY,WITH ROLLUP,WITH CUBE,GROUPING SETS(..)
--SQL Server2008 程序设计 汇总 GROUP BY ,WITH ROLLUP WITH CUBE GROUPING SET(..) /*********************** ...
- [转]详解Oracle高级分组函数(ROLLUP, CUBE, GROUPING SETS)
原文地址:http://blog.csdn.net/u014558001/article/details/42387929 本文主要讲解 ROLLUP, CUBE, GROUPING SETS的主要用 ...
随机推荐
- PyQt(Python+Qt)学习随笔:Qt Designer中QAbstractButton派生按钮部件的icon属性和iconSize属性
icon属性 icon属性保存按钮上展示的图标,图标的缺省大小由图形界面的样式决定,但可以通过 iconSize 属性进行调整. 图标的几种子属性状态的含义与QWidget的windowIcon属性相 ...
- PyQt(Python+Qt)学习随笔:窗口部件大小策略sizePolicy与SizeConstraint布局大小约束的关系
在<PyQt(Python+Qt)学习随笔:Qt Designer中部件的三个属性sizeHint缺省尺寸.minimumSizeHint建议最小尺寸和minimumSize最小尺寸>. ...
- OLLVM简单入门
目前市面上的许多安全公司都会在保护IOS应用程序或安卓APP时都会用到OLLVM技术.譬如说顶象IOS加固.网易IOS加固等等.故而我们今天研究下OLLVM是个什么.将从(1)OLLVM是什么?OLL ...
- 初识Flask——基于python的web框架
参考教程链接: https://dormousehole.readthedocs.io/en/latest/ (主要)https://www.w3cschool.cn/flask/ 目录: 1.写了一 ...
- CSP-S 初赛最后的复习
2020CSP-S 模拟赛1 3.一个圆形水池中等概率随机分布着四只鸭子,那么存在一条直径,使得鸭子全在直径一侧的概率是(). A.\(\frac 1{16}\) B.\(\frac 1{8}\) C ...
- AcWing 180. 排书
AStar 最坏情况\(O(log_2560 ^ 4)\) 用\(AStar\)算法做了这题,程序跑了\(408ms\). 相比于\(IDA*\)的\(100ms\)左右要慢上不少. 且\(A*\)由 ...
- Chrome DevTools — Network -- 转载
转载地址:https://segmentfault.com/a/1190000008407729 记录网络请求 默认情况下,只要DevTools在开启状态,DevTools会记录所有的网络请求,当然, ...
- Springboot 使用logback直接将日志写入Elasticsearch
正常情况下,一般组合为elk 即日志会通过logstash写入es,但本文主要为轻量级项目直接利用appender写入es 首先需要引入包 <dependency> <groupId ...
- 设置RAC DB归档
1.关闭集群数据库 srvctl stop database -d RAC 2.将节点一设置为归档模式 sqlplus / as sysdba startup mount alter database ...
- linux之文本编辑器vi常用命令
由于经常在linux下面文本操作,所以这里稍微系统的总结一下自己常用的vi命令 1.打开命令: vi+filename (还有各种打开的姿势,只不过我比较顺手这个) 2.退出命令: :q 退出而 ...