阿里出品Excel工具EasyExcel使用小结
前提
笔者做小数据和零号提数工具人已经有一段时间,服务的对象是运营和商务的大佬,一般要求导出的数据是Excel文件,考虑到初创团队机器资源十分有限的前提下,选用了阿里出品的Excel工具EasyExcel。这里简单分享一下EasyExcel的使用心得。EasyExcel从其依赖树来看是对apache-poi的封装,笔者从开始接触Excel处理就选用了EasyExcel,避免了广泛流传的apache-poi导致的内存泄漏问题。
引入EasyExcel依赖
引入EasyExcel的Maven如下:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>${easyexcel.version}</version>
</dependency>
当前(2020-09-08)的最新版本为2.2.6。
API简介
Excel文件主要围绕读和写操作进行处理,EasyExcel的API也是围绕这两个方面进行设计。先看读操作的相关API:
// 新建一个ExcelReaderBuilder实例
ExcelReaderBuilder readerBuilder = EasyExcel.read();
// 读取的文件对象,可以是File、路径(字符串)或者InputStream实例
readerBuilder.file("");
// 文件的密码
readerBuilder.password("");
// 指定sheet,可以是数字序号sheetNo或者字符串sheetName,若不指定则会读取所有的sheet
readerBuilder.sheet("");
// 是否自动关闭输入流
readerBuilder.autoCloseStream(true);
// Excel文件格式,包括ExcelTypeEnum.XLSX和ExcelTypeEnum.XLS
readerBuilder.excelType(ExcelTypeEnum.XLSX);
// 指定文件的标题行,可以是Class对象(结合@ExcelProperty注解使用),或者List<List<String>>实例
readerBuilder.head(Collections.singletonList(Collections.singletonList("head")));
// 注册读取事件的监听器,默认的数据类型为Map<Integer,String>,第一列的元素的下标从0开始
readerBuilder.registerReadListener(new AnalysisEventListener() {
@Override
public void invokeHeadMap(Map headMap, AnalysisContext context) {
// 这里会回调标题行,文件内容的首行会认为是标题行
}
@Override
public void invoke(Object o, AnalysisContext analysisContext) {
// 这里会回调每行的数据
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
}
});
// 构建读取器
ExcelReader excelReader = readerBuilder.build();
// 读取数据
excelReader.readAll();
excelReader.finish();
可以看到,读操作主要使用Builder模式和事件监听(或者可以理解为观察者模式)的设计。一般情况下,上面的代码可以简化如下:
Map<Integer, String> head = new HashMap<>();
List<Map<Integer, String>> data = new LinkedList<>();
EasyExcel.read("文件的绝对路径").sheet()
.registerReadListener(new AnalysisEventListener<Map<Integer, String>>() {
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
head.putAll(headMap);
}
@Override
public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) {
data.add(row);
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
// 这里可以打印日志告知所有行读取完毕
}
}).doRead();
如果需要读取数据并且转换为对应的对象列表,则需要指定标题行的Class,结合注解@ExcelProperty使用:
文件内容:
|订单编号|手机号|
|ORDER_ID_1|112222|
|ORDER_ID_2|334455|
@Data
private static class OrderDTO {
@ExcelProperty(value = "订单编号")
private String orderId;
@ExcelProperty(value = "手机号")
private String phone;
}
Map<Integer, String> head = new HashMap<>();
List<OrderDTO> data = new LinkedList<>();
EasyExcel.read("文件的绝对路径").head(OrderDTO.class).sheet()
.registerReadListener(new AnalysisEventListener<OrderDTO>() {
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
head.putAll(headMap);
}
@Override
public void invoke(OrderDTO row, AnalysisContext analysisContext) {
data.add(row);
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
// 这里可以打印日志告知所有行读取完毕
}
}).doRead();
如果数据量巨大,建议使用Map<Integer, String>类型读取和操作数据对象,否则大量的反射操作会使读取数据的耗时大大增加,极端情况下,例如属性多的时候反射操作的耗时有可能比读取和遍历的时间长。
接着看写操作的API:
// 新建一个ExcelWriterBuilder实例
ExcelWriterBuilder writerBuilder = EasyExcel.write();
// 输出的文件对象,可以是File、路径(字符串)或者OutputStream实例
writerBuilder.file("");
// 指定sheet,可以是数字序号sheetNo或者字符串sheetName,可以不设置,由下面提到的WriteSheet覆盖
writerBuilder.sheet("");
// 文件的密码
writerBuilder.password("");
// Excel文件格式,包括ExcelTypeEnum.XLSX和ExcelTypeEnum.XLS
writerBuilder.excelType(ExcelTypeEnum.XLSX);
// 是否自动关闭输出流
writerBuilder.autoCloseStream(true);
// 指定文件的标题行,可以是Class对象(结合@ExcelProperty注解使用),或者List<List<String>>实例
writerBuilder.head(Collections.singletonList(Collections.singletonList("head")));
// 构建ExcelWriter实例
ExcelWriter excelWriter = writerBuilder.build();
List<List<String>> data = new ArrayList<>();
// 构建输出的sheet
WriteSheet writeSheet = new WriteSheet();
writeSheet.setSheetName("target");
excelWriter.write(data, writeSheet);
// 这一步一定要调用,否则输出的文件有可能不完整
excelWriter.finish();
ExcelWriterBuilder中还有很多样式、行处理器、转换器设置等方法,笔者觉得不常用,这里不做举例,内容的样式通常在输出文件之后再次加工会更加容易操作。写操作一般可以简化如下:
List<List<String>> head = new ArrayList<>();
List<List<String>> data = new LinkedList<>();
EasyExcel.write("输出文件绝对路径")
.head(head)
.excelType(ExcelTypeEnum.XLSX)
.sheet("target")
.doWrite(data);
实用技巧
下面简单介绍一下生产中用到的实用技巧。
多线程读
使用EasyExcel多线程读建议在限定的前提条件下使用:
- 源文件已经被分割成多个小文件,并且每个小文件的标题行和列数一致。
- 机器内存要充足,因为并发读取的结果最后需要合并成一个大的结果集,全部数据存放在内存中。
经常遇到外部反馈的多份文件需要紧急进行数据分析或者交叉校对,为了加快文件读取,笔者通常使用这种方式批量读取格式一致的Excel文件
一个简单的例子如下:
@Slf4j
public class EasyExcelConcurrentRead {
static final int N_CPU = Runtime.getRuntime().availableProcessors();
public static void main(String[] args) throws Exception {
// 假设I盘的temp目录下有一堆同格式的Excel文件
String dir = "I:\\temp";
List<Map<Integer, String>> mergeResult = Lists.newLinkedList();
ThreadPoolExecutor executor = new ThreadPoolExecutor(N_CPU, N_CPU * 2, 0, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), new ThreadFactory() {
private final AtomicInteger counter = new AtomicInteger();
@Override
public Thread newThread(@NotNull Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
thread.setName("ExcelReadWorker-" + counter.getAndIncrement());
return thread;
}
});
Path dirPath = Paths.get(dir);
if (Files.isDirectory(dirPath)) {
List<Future<List<Map<Integer, String>>>> futures = Files.list(dirPath)
.map(path -> path.toAbsolutePath().toString())
.filter(absolutePath -> absolutePath.endsWith(".xls") || absolutePath.endsWith(".xlsx"))
.map(absolutePath -> executor.submit(new ReadTask(absolutePath)))
.collect(Collectors.toList());
for (Future<List<Map<Integer, String>>> future : futures) {
mergeResult.addAll(future.get());
}
}
log.info("读取[{}]目录下的文件成功,一共加载:{}行数据", dir, mergeResult.size());
// 其他业务逻辑.....
}
@RequiredArgsConstructor
private static class ReadTask implements Callable<List<Map<Integer, String>>> {
private final String location;
@Override
public List<Map<Integer, String>> call() throws Exception {
List<Map<Integer, String>> data = Lists.newLinkedList();
EasyExcel.read(location).sheet()
.registerReadListener(new AnalysisEventListener<Map<Integer, String>>() {
@Override
public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) {
data.add(row);
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("读取路径[{}]文件成功,一共[{}]行", location, data.size());
}
}).doRead();
return data;
}
}
}
这里采用ThreadPoolExecutor#submit()提交并发读的任务,然后使用Future#get()等待所有任务完成之后再合并最终的读取结果。
注意,一般文件的写操作不能并发执行,否则很大的概率会导致数据错乱
多Sheet写
多Sheet写,其实就是使用同一个ExcelWriter实例,写入多个WriteSheet实例中,每个Sheet的标题行可以通过WriteSheet实例中的配置属性进行覆盖,代码如下:
public class EasyExcelMultiSheetWrite {
public static void main(String[] args) throws Exception {
ExcelWriterBuilder writerBuilder = EasyExcel.write();
writerBuilder.excelType(ExcelTypeEnum.XLSX);
writerBuilder.autoCloseStream(true);
writerBuilder.file("I:\\temp\\temp.xlsx");
ExcelWriter excelWriter = writerBuilder.build();
WriteSheet firstSheet = new WriteSheet();
firstSheet.setSheetName("first");
firstSheet.setHead(Collections.singletonList(Collections.singletonList("第一个Sheet的Head")));
// 写入第一个命名为first的Sheet
excelWriter.write(Collections.singletonList(Collections.singletonList("第一个Sheet的数据")), firstSheet);
WriteSheet secondSheet = new WriteSheet();
secondSheet.setSheetName("second");
secondSheet.setHead(Collections.singletonList(Collections.singletonList("第二个Sheet的Head")));
// 写入第二个命名为second的Sheet
excelWriter.write(Collections.singletonList(Collections.singletonList("第二个Sheet的数据")), secondSheet);
excelWriter.finish();
}
}
效果如下:

分页查询和批量写
在一些数据量比较大的场景下,可以考虑分页查询和批量写,其实就是分页查询原始数据 -> 数据聚合或者转换 -> 写目标数据 -> 下一页查询....。其实数据量少的情况下,一次性全量查询和全量写也只是分页查询和批量写的一个特例,因此可以把查询、转换和写操作抽象成一个可复用的模板方法:
int batchSize = 定义每篇查询的条数;
OutputStream outputStream = 定义写到何处;
ExcelWriter writer = new ExcelWriterBuilder()
.autoCloseStream(true)
.file(outputStream)
.excelType(ExcelTypeEnum.XLSX)
.head(ExcelModel.class);
for (;;){
List<OriginModel> list = originModelRepository.分页查询();
if (list.isEmpty()){
writer.finish();
break;
}else {
list 转换-> List<ExcelModel> excelModelList;
writer.write(excelModelList);
}
}
参看笔者前面写过的一篇非标题党生产应用文章《百万级别数据Excel导出优化》,适用于大数据量导出的场景,代码如下:
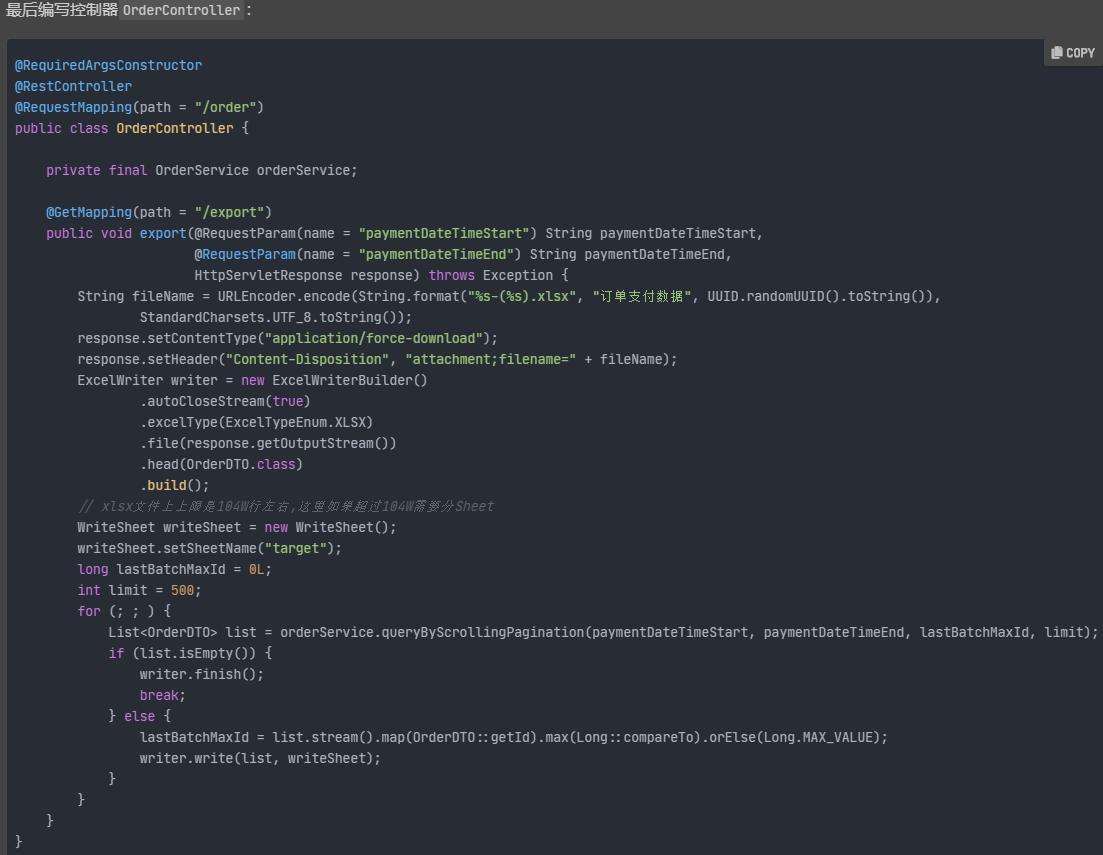
Excel上传与下载
下面的例子适用于Servlet容器,常见的如Tomcat,应用于spring-boot-starter-web
Excel文件上传跟普通文件上传的操作差不多,然后使用EasyExcel的ExcelReader读取请求对象MultipartHttpServletRequest中文件部分抽象的InputStream实例即可:
@PostMapping(path = "/upload")
public ResponseEntity<?> upload(MultipartHttpServletRequest request) throws Exception {
Map<String, MultipartFile> fileMap = request.getFileMap();
for (Map.Entry<String, MultipartFile> part : fileMap.entrySet()) {
InputStream inputStream = part.getValue().getInputStream();
Map<Integer, String> head = new HashMap<>();
List<Map<Integer, String>> data = new LinkedList<>();
EasyExcel.read(inputStream).sheet()
.registerReadListener(new AnalysisEventListener<Map<Integer, String>>() {
@Override
public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) {
head.putAll(headMap);
}
@Override
public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) {
data.add(row);
}
@Override
public void doAfterAllAnalysed(AnalysisContext analysisContext) {
log.info("读取文件[{}]成功,一共:{}行......", part.getKey(), data.size());
}
}).doRead();
// 其他业务逻辑
}
return ResponseEntity.ok("success");
}
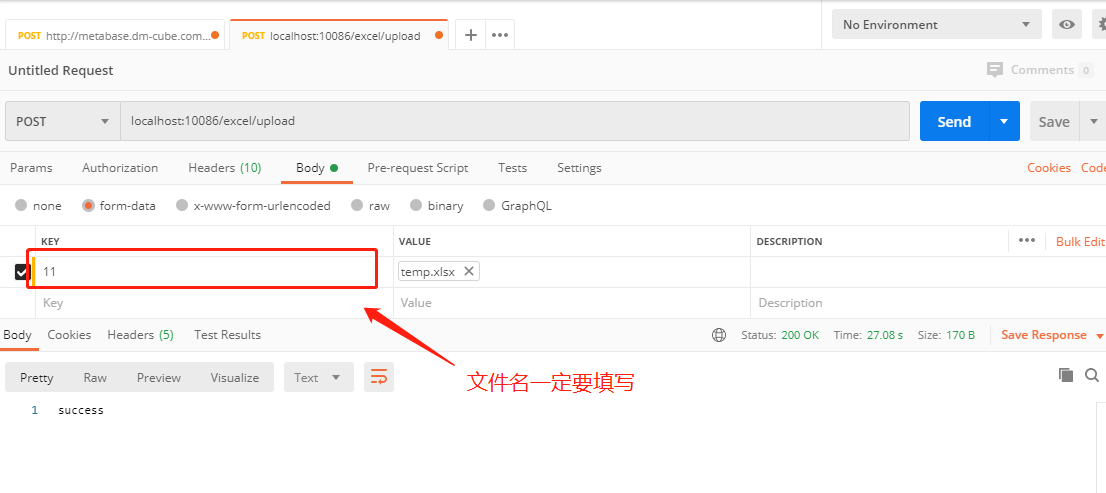
使用Postman请求如下:
使用EasyExcel进行Excel文件导出也比较简单,只需要把响应对象HttpServletResponse中携带的OutputStream对象附着到EasyExcel的ExcelWriter实例即可:
@GetMapping(path = "/download")
public void download(HttpServletResponse response) throws Exception {
// 这里文件名如果涉及中文一定要使用URL编码,否则会乱码
String fileName = URLEncoder.encode("文件名.xlsx", StandardCharsets.UTF_8.toString());
// 封装标题行
List<List<String>> head = new ArrayList<>();
// 封装数据
List<List<String>> data = new LinkedList<>();
response.setContentType("application/force-download");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
EasyExcel.write(response.getOutputStream())
.head(head)
.autoCloseStream(true)
.excelType(ExcelTypeEnum.XLSX)
.sheet("Sheet名字")
.doWrite(data);
}
这里需要注意一下:
- 文件名如果包含中文,需要进行
URL编码,否则一定会乱码。 - 无论导入或者导出,如果数据量大比较耗时,使用了
Nginx的话记得调整Nginx中的连接、读写超时时间的上限配置。 - 使用
SpringBoot需要调整spring.servlet.multipart.max-request-size和spring.servlet.multipart.max-file-size的配置值,避免上传的文件过大出现异常。
小结
EasyExcel的API设计简单易用,可以使用他快速开发有Excel数据导入或者导出的场景,实属提数工具人的喜爱的工具之一。
(本文完 c-3-d e-a-20200909)
阿里出品Excel工具EasyExcel使用小结的更多相关文章
- 阿里巴巴excel工具easyexcel 助你快速简单避免OOM
Java解析.生成Excel比较有名的框架有Apache poi.jxl.但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有 ...
- Excel解析工具easyexcel全面探索
1. Excel解析工具easyexcel全面探索 1.1. 简介 之前我们想到Excel解析一般是使用POI,但POI存在一个严重的问题,就是非常消耗内存.所以阿里人员对它进行了重写从而诞生了eas ...
- Excel解析easyexcel工具类
Excel解析easyexcel工具类 easyexcel解决POI解析Excel出现OOM <!-- https://mvnrepository.com/artifact/com.alibab ...
- 一行代码完成 Java的 Excel 读写--easyexcel
最近我在 Github 上查找一个可以快速开发 excel 导入导出工具,偶然发现由阿里开发 easyexcel 开源项目,尝试使用后感觉这款工具挺不错的,下面分享一下我的 easyexcel 案例使 ...
- excel工具类
excel工具类 import com.iport.framework.util.ValidateUtil; import org.apache.commons.lang3.StringUtils; ...
- 导入导出Excel工具类ExcelUtil
前言 前段时间做的分布式集成平台项目中,许多模块都用到了导入导出Excel的功能,于是决定封装一个ExcelUtil类,专门用来处理Excel的导入和导出 本项目的持久化层用的是JPA(底层用hibe ...
- 【原创】.NET读写Excel工具Spire.Xls使用(1)入门介绍
在.NET平台,操作Excel文件是一个非常常用的需求,目前比较常规的方法有以下几种: 1.Office Com组件的方式:这个方式非常累人,微软的东西总是这么的复杂,使用起来可能非常不便,需要安装E ...
- 【原创】.NET读写Excel工具Spire.Xls使用(2)Excel文件的控制
本博客所有文章分类的总目录:http://www.cnblogs.com/asxinyu/p/4288836.html .NET读写Excel工具Spire.Xls使用文章 ...
- 【原创】.NET读写Excel工具Spire.Xls使用(3)单元格控制
本博客所有文章分类的总目录:http://www.cnblogs.com/asxinyu/p/4288836.html .NET读写Excel工具Spire.Xls使用文章 ...
随机推荐
- 2020-06-16:Redis hgetall时间复杂度?
福哥答案2020-06-16: 时间复杂度是O(N).时间复杂度:O(N) where N is the size of the hash.
- Python参数解析工具ArgumentParser
通过命令行运行Python脚本时,可以通过ArgumentParser来高效地接受并解析命令行参数. 流程 新建一个ArgumentParser类对象,然后来添加若干个参数选项,最后通过parse_a ...
- 题解 UVA10457
题目大意:另s = 路径上的最大边权减最小边权,求u到v上的一条路径,使其s最小,输出这个s. 很容易想到枚举最小边然后跑最小瓶颈路. so,如何跑最小瓶颈路? 利用Kruskal,因为树上两点路径唯 ...
- STL函数库的应用第三弹——数据结构(栈)
Part 1:栈是什么 栈(stack)又名堆栈,它是一种运算受限的线性表.限定仅在表尾进行插入和删除操作的线性表. 这一端被称为栈顶,相对地,把另一端称为栈底. 向一个栈插入新元素又称作进栈.入栈或 ...
- 什么?Java9这些史诗级更新你都不知道?Java9特性一文打尽!
「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」. 当然 ...
- 9.oracle表查询关键字
1.使用逻辑操作符号问题:查询工资高于500或者是岗位为manager的雇员,同时还要满足他们的姓名首字母为大写的J? select * from emp where (sal > 500 or ...
- StructuredStreaming编程模型
StructuredStreaming编程模型 基本概念 ◆ Time ◆ Trigger ◆ Input ◆ Query ◆ Result ◆ Output 案例模型:实时处理流单词统计编程模型 ...
- ucore学习
1.启动操作系统的bootloader,用于了解操作系统启动前的状态和要做的准备工作,了解运行操作系统的硬件支持,操作系统如何加载到内存中,理解两类中断--"外设中断"," ...
- CentOS下删除物理磁盘,删除LVM
1.删除 dmsetup remove LV_name 2.vgreduce VG_name --removemissing 3.vgremove VG_name 4.pvremove disk
- dcoker 小应用(二)
sudo yum install epel-release vi /etc/yum.repos.d/epel.repo use base url instead of mirror url ...