在线问诊 Python、FastAPI、Neo4j — 创建 节点关系
relationship_data.csv
症状,检查,疾病,药品,宜吃,忌吃
"上下楼梯疼,不能久站,感觉有点肿","膝关节核磁","右膝髌上囊及关节腔少量积液","扶他林","西红柿,香蕉","辣椒,大蒜"
"眼睛胀痛,干涩,畏光,眼胀,眼痛,看东西有时候清楚有时候不清楚","视力,眼底","干眼","施图伦","胡萝卜,核桃仁,菠菜","海鲜,芥末"
关系:症状-检查
def generate_examine() -> list:
"""
关系:疾病-检查
"""
rels_check = []
df = pd.read_csv('relationship_data.csv')
for idx, row in df.iterrows():
for symptom in row['检查'].split(','):
for exam in row['症状'].split(','):
rels_check.append([exam, symptom])
rels_check = deduplicate(rels_check)
return rels_check
def relationship_rels_check():
"""
# 创建关系
match(p:Symptom),(q:Examine) where p.name='上下楼梯疼' and q.name='膝关节核磁' create (p)-[rel:need_check{name:'症状检查'}]->(q)
# 删除关系
MATCH(p: Symptom)-[r: need_check]-(q:Examine)
WHERE p.name = '上下楼梯疼' and q.name = '膝关节核磁'
DELETE r
"""
cql = "MATCH(p:Symptom)-[r:need_check]-(q:Examine) DELETE r"
neo4j.execute_write(cql)
print("删除成功 => need_check")
# 症状 需要 做哪些检查
rels_check = generate_examine()
print(rels_check)
cql_list = generate_cql('Symptom', 'Examine', rels_check, 'need_check', '症状检查')
for cql in cql_list:
neo4j.execute_write(cql)
print(cql)
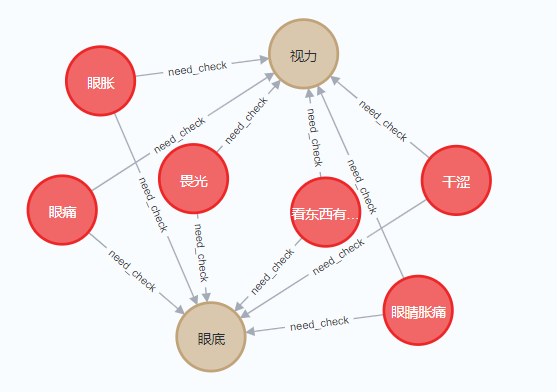
关系:疾病-症状
def generate_symptom() -> list:
"""
关系:疾病-症状 (疾病有哪些症状)
"""
rels_check = []
df = pd.read_csv('relationship_data.csv')
for idx, row in df.iterrows():
for symptom in row['症状'].split(','):
for exam in row['疾病'].split(','):
rels_check.append([exam, symptom])
rels_check = deduplicate(rels_check)
return rels_check
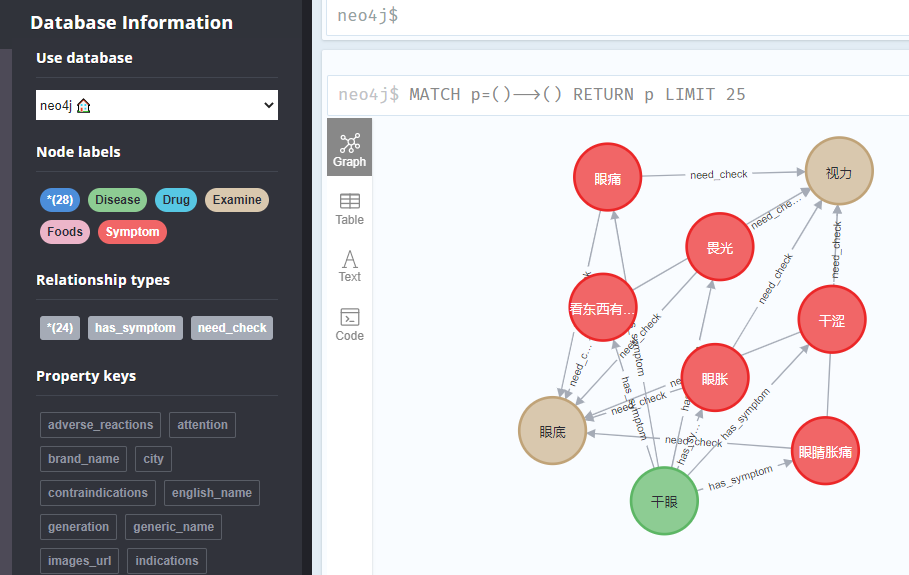
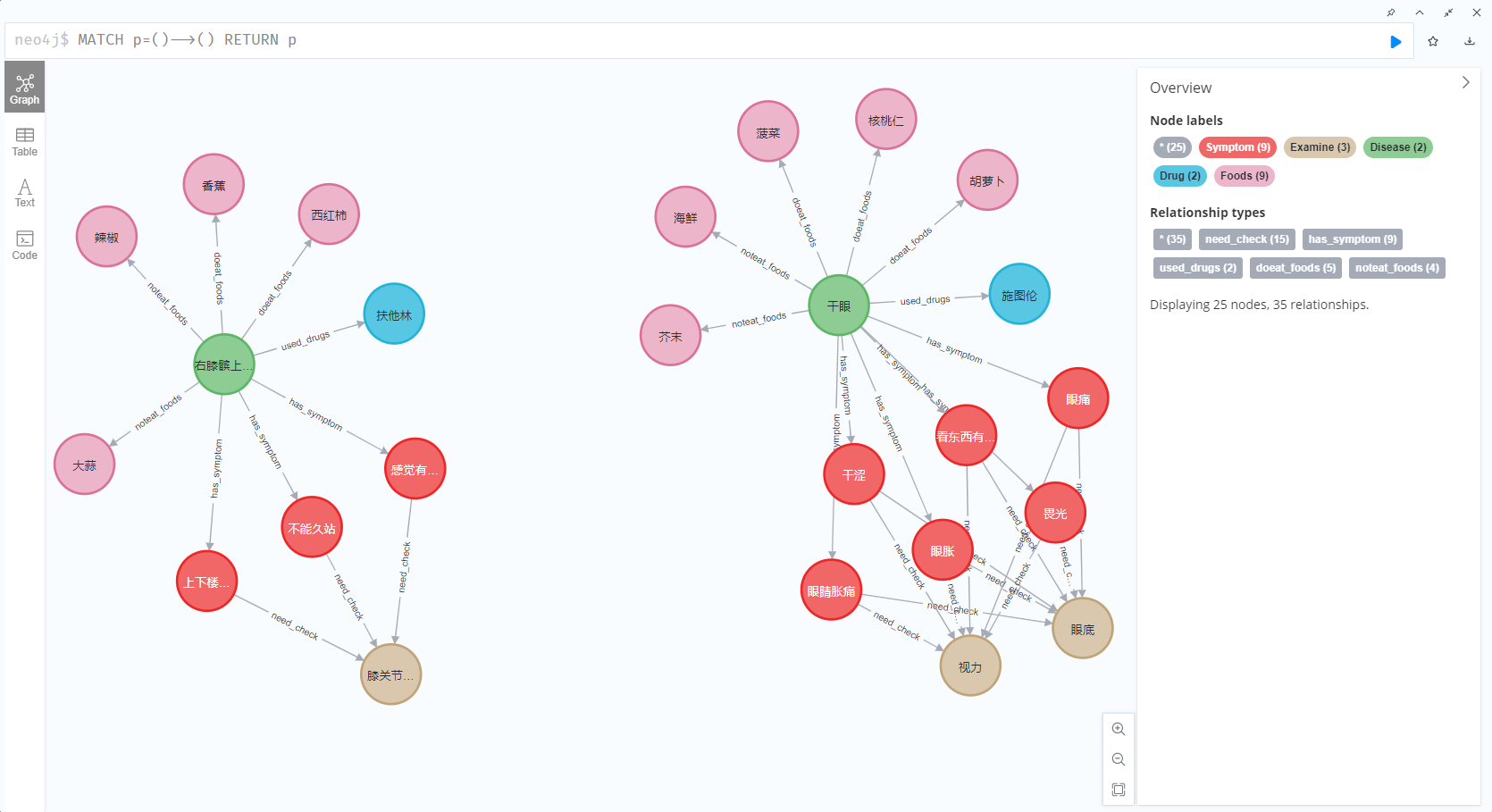
代码重构
包括疾病用药,食物能吃,食物不能吃的关系。
详细代码如下
import logging
from utils.neo4j_provider import neo4j
import pandas as pd
logging.root.setLevel(logging.INFO)
# 关系去重函数
def deduplicate(relation_old) -> list:
relation_new = []
for each in relation_old:
if each not in relation_new:
relation_new.append(each)
return relation_new
def generate_cql(start_node, end_node, edges, rel_type, rel_name) -> str:
"""
生成 CQL
"""
cql = []
for edge in edges:
p = edge[0]
q = edge[1]
# 创建关系的 Cypher 语句
cql.append(
"MATCH(p:%s),(q:%s) WHERE p.name='%s' and q.name='%s' CREATE (p)-[rel:%s{name:'%s'}]->(q)" % (start_node, end_node, p, q, rel_type, rel_name))
print('创建关系 {}-{}->{}'.format(p, rel_type, q))
return cql
def generate_relation(l_name, r_name) -> list:
relation_list = []
df = pd.read_csv('relationship_data.csv')
for idx, row in df.iterrows():
for l_node in row[l_name].split(','):
for r_node in row[r_name].split(','):
relation_list.append([l_node, r_node])
return deduplicate(relation_list)
def create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, relation_name):
"""
创建关系
:param l_node: 左节点 name
:param r_node: 右节点 name
:param relationship: 关系
:param l_data_name: 左数据列名
:param r_data_name: 右数据列名
:param relation_name: 关系 name
:return:
"""
neo4j.delete_relationship(l_node, r_node, relationship)
relation_list = generate_relation(l_data_name, r_data_name)
print(relation_list)
cql_list = generate_cql(l_node, r_node, relation_list, relationship, relation_name)
for cql in cql_list:
neo4j.execute_write(cql)
print(cql)
def relationship_relation_check():
l_node = "Symptom"
r_node = "Examine"
relationship = "need_check"
l_data_name = '症状'
r_data_name = '检查'
rel_name = '症状检查'
create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, rel_name)
def relationship_has_symptom():
l_node = "Disease"
r_node = "Symptom"
relationship = "has_symptom"
l_data_name = '疾病'
r_data_name = '症状'
rel_name = '症状'
create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, rel_name)
def relationship_used_drugs():
l_node = "Disease"
r_node = "Drug"
relationship = "used_drugs"
l_data_name = '疾病'
r_data_name = '药品'
rel_name = '常用药品'
create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, rel_name)
def relationship_doeat_foods():
l_node = "Disease"
r_node = "Foods"
relationship = "doeat_foods"
l_data_name = '疾病'
r_data_name = '宜吃'
rel_name = '推荐食物'
create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, rel_name)
def relationship_noteat_foods():
l_node = "Disease"
r_node = "Foods"
relationship = "noteat_foods"
l_data_name = '疾病'
r_data_name = '忌吃'
rel_name = '忌吃食物'
create_relationship(l_node, r_node, relationship, l_data_name, r_data_name, rel_name)
if __name__ == "__main__":
# 有症状需要做哪些检查
relationship_relation_check()
# 疾病有哪些症状
relationship_has_symptom()
# 疾病常用药物
relationship_used_drugs()
# 推荐饮食
relationship_doeat_foods()
# 不宜饮食
relationship_noteat_foods()
源代码地址:https://gitee.com/VipSoft/VipQA
在线问诊 Python、FastAPI、Neo4j — 创建 节点关系的更多相关文章
- python 查询Neo4j多节点的多层关系
需求:查询出满足3人及3案有关系的集合 # -*- coding: utf-8 -*- from py2neo import Graph import psycopg2 # 二维数组查找 def fi ...
- python将知识图谱的节点关系(CSV或其他格式)转换成Echarts所需的json格式
python将知识图谱的节点关系(CSV或其他格式)转换成Echarts所需的json格式 前言: 1. 此代码以如下(CSV)格式的数据为例, 故事 时间 地点 人物 xx 2020 安徽合肥 小戈 ...
- Eclipse下maven使用嵌入式(Embedded)Neo4j创建Hello World项目
Eclipse下maven使用嵌入式(Embedded)Neo4j创建Hello World项目 新建一个maven工程,这里不赘述如何新建maven工程. 添加Neo4j jar到你的工程 有两种方 ...
- Neo4j创建自动索引
一.创建Neo4j的Legacy indexing 1.为节点创建索引 官方API的创建示例为: 将一节点添加至索引: public static void AddNodeIndex(String n ...
- Python网络数据采集- 创建爬虫
1. 初见网络爬虫 1.1 网络连接 输出某个网页的全部 HTML 代码. urllib 是 Python 的标准库(就是说你不用额外安装就可以运行这个例子),包含了从网络请求数据,处理 cookie ...
- jacascript DOM节点——节点关系与操作
前言:这是笔者学习之后自己的理解与整理.如果有错误或者疑问的地方,请大家指正,我会持续更新! 节点关系 DOM可以将任何HTML描绘成一个由多层节点构成的结构.每个节点都拥有各自的特点.数据和方法,也 ...
- python之multiprocessing创建进程
python的multiprocessing模块是用来创建多进程的,下面对multiprocessing总结一下使用记录. multiprocessing创建多进程在windows和linux系统下的 ...
- neo4j 将一个节点的属性复制到另一个节点上
在使用Python操作Neo4j数据库的时候,经常会遇到重复的节点,需要将一个节点的属性复制到另一个节点,之后将该节点删除. def copy_node_properties(source_node_ ...
- Python | 面试必问,线程与进程的区别,Python中如何创建多线程?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是Python专题第20篇文章,我们来聊聊Python当中的多线程. 其实关于元类还有很多种用法,比如说如何在元类当中设置参数啦,以及一 ...
- 深入理解DOM节点关系
× 目录 [1]父级属性 [2]子级属性 [3]同级属性[4]包含方法[5]关系方法 前面的话 DOM可以将任何HTML描绘成一个由多层节点构成的结构.节点分为12种不同类型,每种类型分别表示文档中不 ...
随机推荐
- shell工具和脚本
Shell脚本 shell 脚本是一种更加复杂度的工具. 大多数shell都有自己的一套脚本语言,包括变量.控制流和自己的语法.shell脚本 与其他脚本语言不同之处在于,shell 脚本针对 she ...
- Hello Welcome to my blog!
Hello Welcome to my blog!
- Go语言中的结构体:灵活性与可扩展性的重要角色
1. 引言 结构体是Go语言中重要且灵活的概念之一.结构体的使用使得我们可以定义自己的数据类型,并将不同类型的字段组合在一起,实现更灵活的数据结构.本文旨在深入介绍Go语言中的结构体,揭示其重要性和灵 ...
- CSS3+Jquery实现带动画效果的下拉选择框
CSS3+JQuery实现带动画效果的下拉选择框. 元素结构为: 1 <div class="box"> 2 <p>this is the first li ...
- 【问题解决】 网关代理Nginx 301暴露自身端口号
一般项目上常用Nginx做负载均衡和静态资源服务器,本案例中项目上使用Nginx作为静态资源服务器出现了很奇怪的现象,我们一起来看看. "诡异"的现象 部署架构如下图,Nginx作 ...
- 浅谈TCP和UDP
简介 在计算机网络中,TCP(传输控制协议)和UDP(用户数据报协议)是两个常用的传输层协议.它们分别提供了可靠的数据传输和快速的数据传送,成为互联网世界中的双子星.本文将探讨TCP和UDP的特点.优 ...
- 使用 OpenAPI 构建 RESTful API 文档
作为一名开发者,往往需要编写程序的 API 文档,尤其是 Web 后端开发者,在跟前端对接 HTTP 接口的时候,一个好的 API 文档能够大大提高协作效率,降低沟通成本,本文就来聊聊如何使用 Ope ...
- 《Among Us》火爆全球,实时语音助力派对游戏开启第二春
今年在全球"宅经济"的影响下,社交派对类游戏意外的迎来了爆发. 8月份,<糖豆人:终极淘汰赛>突然爆火,创造了首日150万玩家.首周Steam 200万销量.单周Twi ...
- 如何根据oops函数偏移快速定位源码?
如何根据函数偏移快速定位源码? 在内核栈的输出中,你一定注意到每一个函数的输出格式都是函数名+偏移量,而这儿的偏移就是调用下一个函数的位置.那么,能不能根据函数名+偏移量直接定位源码的位置呢? 答案是 ...
- MAUI Blazor如何隐藏滚动条
MAUI Blazor如何隐藏滚动条 Windows 在Windows上是最简单的,改css就可以了,把下面这段添加到app.css中 ::-webkit-scrollbar { display: n ...