10倍!BoostKit鲲鹏全局缓存3大创新技术助力Ceph性能提升
摘要:本文从四个方面阐述了BoostKit鲲鹏全局缓存技术,该技术针对Ceph开源存储方案存在的痛点,采用三大创新技术,有效的提高了Ceph的性能,最高可以将Ceph性能提升10倍。
本文分享自华为云社区《【云驻共创】BoostKit鲲鹏全局缓存技术助力Ceph性能提升10倍,真香》,作者:码农飞哥。
1. 存储行业特点及挑战
有统计数据显示,企业应用每增加100ms存储时延会造成1%的销售损失。如下图所示:
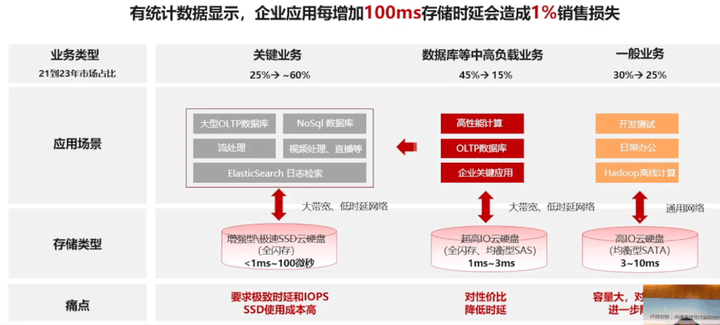
从21年到23年,关键业务的占比从25%增加到60%,数据库等中高负载业务从45%减少到15%,一般业务从 30%减少到25%。
对于关键业务一般使用的存储类型是 增强型\极速SSD云硬盘(全闪存),这种方式主要的痛点是 要求极致时延和IOPS SSD使用成本高。
对于数据库等中高负载业务使用的存储类型是超高IO云硬盘(全闪存、均衡型SAS),这种方式的主要痛点是对性价比降低时延。
对于一般业务使用的是高IO云硬盘(均衡型SATA)
1.1.Ceph开源存储方案面临的性能挑战

Ceph开源存储方案面临的性能挑战主要是: IOPS性能低,IO时延高。 而造成这种情况的原因主要有如下三个方面:
- IO请求流程多,线程切换开销大
- IO处理流程长,队列等待多,端到端时延高。
- IO随机性大,磁盘带宽利用率低。
IO的写入流程是:
- Message 接受入队
- 三副本数据处理
- 数据持久化
- 元数据持久化
- 资源释放,响应完成。
我们可以看到一个完整的IO写入流程包括了5大流程,流程真的很长。
那么BoostKit鲲鹏全局缓存技术又是如何应对这些挑战的呢?
2. 全局缓存创新与价值
BoostKit鲲鹏全局缓存技术主要有三大创新技术,通过三大创新技术可以实现存储性能飞跃式提升。
- 缓存前后台分离,缩短IO路径
- IO聚合,实现磁盘带宽性能
- 智能预取,提高读缓存命中率。
下面我分别就这三大创新技术进行一个简要的说明。
2.1. 缓存前后台分离,缩短IO路径
- 在计算侧(前台)重定向到全局缓存,读写IO请求直接在缓存中命中并实时反馈给上层应用。
- 全局缓存的IO数据异步下刷到后端存储侧(后台)或提前预取数据到全局缓存
其实现流程如下图所示:
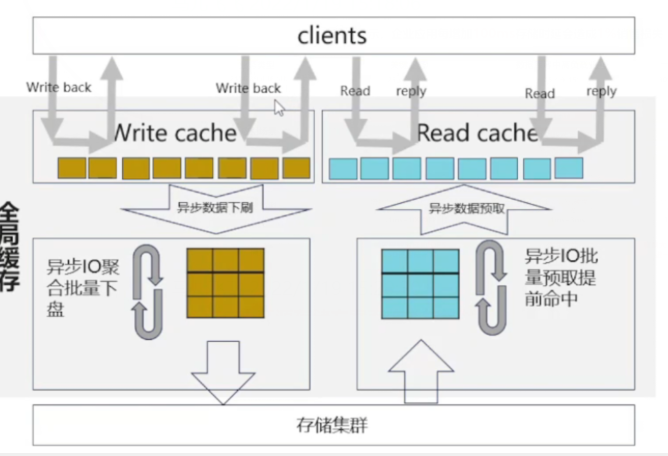
从图中可以看出读IO和写IO都是在全局缓存中实现的。
写IO首先将数据写入缓存中,然后异步下刷到磁盘中。
异步IO批量预取提前命中,异步数据预取,读IO直接从缓存中取数据。
这样做的好处就是 提高了异步刷盘速率,保证写缓存100%命中,降低写时延。
提高预取准确率,加大缓存容量,保证读缓存80%命中,降低读时延。
如下图所示:展示了缓存前后台的具体实现。
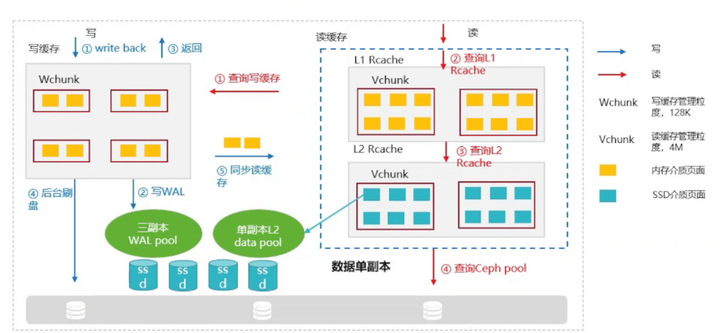
- 流程解耦:写缓存刷盘,读缓存淘汰无需互斥,可灵活控制各自水位。
- 资源解耦:读写缓存并发,Quota资源等解耦,避免相互影响。
- 介质类型解耦:读写缓存可分为管理异构缓存介质(RAM,NVMeSSD),实现介质分离。
- 冗余策略优化:读cache使用单副本,提高cache空间利用率,写cache使用三副本,保证数据可靠性。
2.2. IO聚合,实现磁盘带宽性能
- IO聚合:通过聚合算法,回写策略和垃圾回收等能力,实现随机写小IO聚合成顺序写大IO,实现磁盘带宽的利用率,使性能得到大幅提升。
- 按需读取:从元数据中获取小IO映射关系,下盘读取小IO数据,无读放大。
- 通过高效的索引算法和数据排列,仅提高有效数据块,并和新写入的数据进行IO聚合,减少IO开销和降低垃圾对业务的影响。
具体实现如下图所示:

2.3. 智能预取,提高读缓存命中率
基于创新的负载识别算法,识别不同应用访问Pattern(如流式、关联、热点等),并通过归一化特征模型制定最优参数(预取门限,长度等),实现80%以上缓存命中率和2倍+读性能提升。
如下图所示:展示了智能预取分离技术架构:
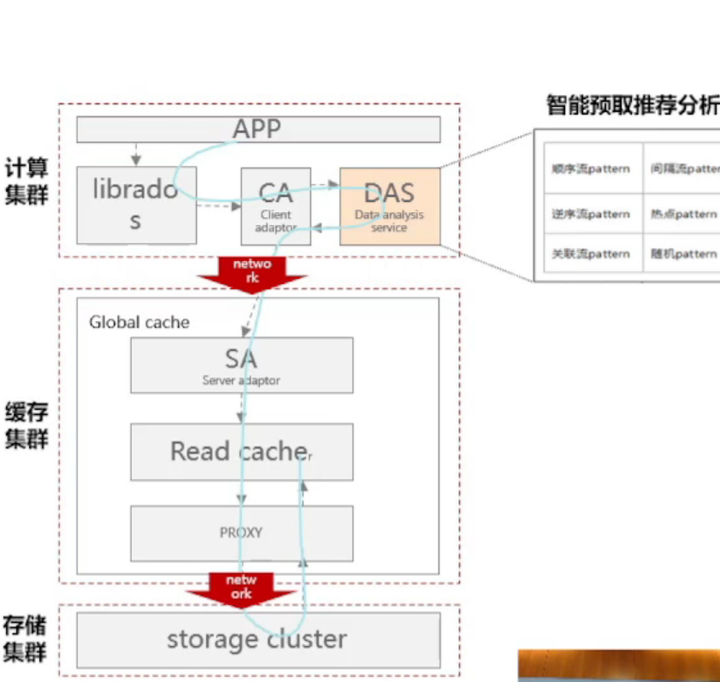
这里主要有两个技术
- 双引擎分离:创新性的Client端推荐引擎+Server端执行引擎分离的智能预取架构。
- 全局精准推荐:推荐引擎拥有全局数据访问视图,从而进行全局精准推荐。
3. 全局缓存功能介绍
3.1. 全局缓存技术的整体架构
说完了全局缓存的创新点之后,接下来让我们来看看全局缓存的各个核心功能。
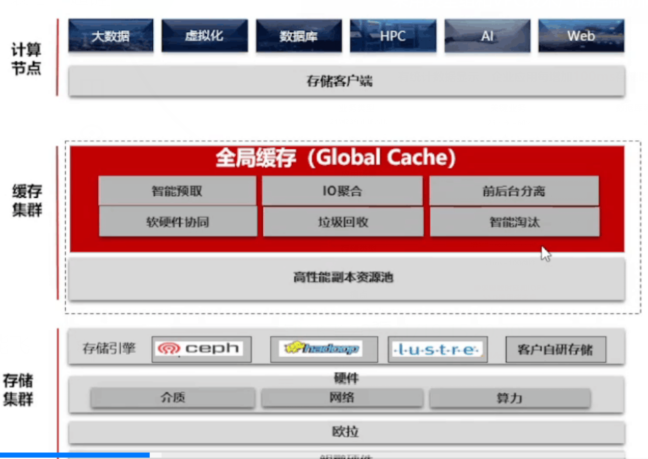
全局缓存技术的整体架构如下图所示:
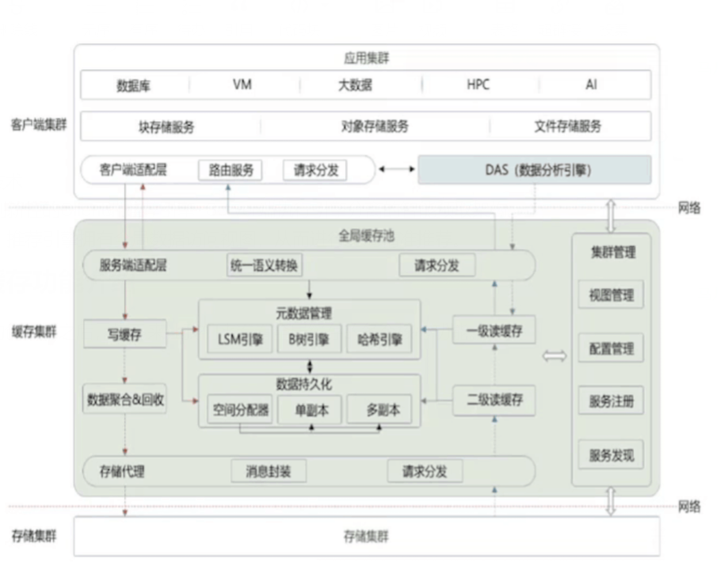
可以用三横+两纵来总结全局缓存技术框架。
三横:客户端集群、缓存集群、存储集群
两纵:读写路径分离双驱加速的逻辑布局。
- 写缓存:数据写入、删除功能、保证Cache前后台写低时延、
- 读缓存:数据读取功能,数据预取和淘汰、保证高Cache命中。
- 元数据管理:高性能元数据管理引擎、小IO聚合、垃圾回收
- 集群管理:集群管理、运行状态管理,故障处理框架。
- 持久化:数据持久化存储,三副本资源池,介质管理。
- 适配层:对接开源Ceph存储,终结Ceph语义。
- 基础设施:系统启动、内存管理、日志、命令行、系统调度。
3.2. 全局缓存功能规格一览
1. 高性能
支持单节点 14W IOPS,1ms时延。
2. 集群兼容性
- 提供无侵入式接口API支持主流ceph集群接入
- 支持块存储服务,对象存储服务
- 支持快照及克隆功能
- 支持鲲鹏平台硬件,openEuler,RedHat系统
3. 可靠性
- 数据持久化存储防掉电丢失。
- 数据三副本以节点域存储,防止单点故障。
- 支持集群故障自动检测,自动故障切换和恢复。
4. 安全性
- 数据通道和管理通道默认支持TLS1.3 安全传输
5. 扩展性
- 支持按需增加缓存节点扩展缓存规模
- 支持在线升级
- 数据持久化存储防掉电丢失
- 数据三副本以节点域存储,防止单点故障
- 支持集群故障自动检测,自动故障切换和恢复。
4. 全局缓存使用介绍
说完了那么多BoostKit鲲鹏全局缓存技术的功能和好处,那么如何使用BoostKit鲲鹏全局缓存呢?
首先找到用户指南,指南地址是:https://support.huawei.com/enterprise/zh/doc/EDOC1100228002?idPath=23710424%7C251364417%7C9856629%7C253662285
按照用户指南一步步去操作使用吧!!!!
总结
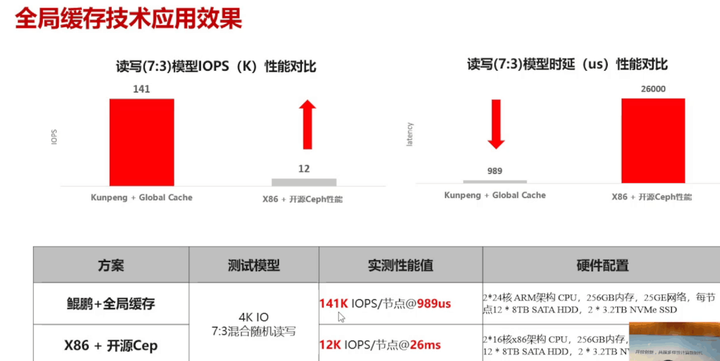
本文从四个方面阐述了BoostKit鲲鹏全局缓存技术,该技术针对Ceph开源存储方案存在的痛点,采用三大创新技术,有效的提高了Ceph的性能,最高可以将Ceph性能提升10倍。如下图所示:
10倍!BoostKit鲲鹏全局缓存3大创新技术助力Ceph性能提升的更多相关文章
- 如何利用缓存机制实现JAVA类反射性能提升30倍
一次性能提高30倍的JAVA类反射性能优化实践 文章来源:宜信技术学院 & 宜信支付结算团队技术分享第4期-支付结算部支付研发团队高级工程师陶红<JAVA类反射技术&优化> ...
- Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创)
我们兴奋的宣布Databricks缓存的通用可用性,作为统一分析平台一部分的 Databricks 运行时特性,它可以将Spark工作负载的扫描速度提升10倍,并且这种改变无需任何代码修改. 1.在本 ...
- nginx缓存静态资源,只需几个配置提升10倍页面加载速度
nginx缓存静态资源,只需几个配置提升10倍页面加载速度 首先我们看图说话 这是在没有缓存的情况下,这个页面发送了很多静态资源的请求: 1.png 可以看到,静态资源占用了整个页面加载用时的90 ...
- Web 应用性能提升 10 倍的 10 个建议
转载自http://blog.jobbole.com/94962/ 提升 Web 应用的性能变得越来越重要.线上经济活动的份额持续增长,当前发达世界中 5 % 的经济发生在互联网上(查看下面资源的统计 ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- 一次 Spark SQL 性能提升10倍的经历(转载)
1. 遇到了啥问题 是酱紫的,简单来说:并发执行 spark job 的时候,并发的提速很不明显. 嗯,且听我慢慢道来,啰嗦点说,类似于我们内部有一个系统给分析师用,他们写一些 sql,在我们的 sp ...
- 搜索 比MySQL快10倍?这可能是目前AWS Aurora最详解读!
作者介绍 朱阅岸,中国人民大学博士,现供职于腾讯云数据库团队.研究方向主要为数据库系统理论与实现.新硬件平台下的数据库系统以及TP+AP型混合系统. 编者按 Aurora作为AWS云上的关系数据库 ...
- openresty开发系列30--openresty中使用全局缓存
openresty开发系列30--openresty中使用全局缓存 Nginx全局内存---本地缓存 使用过如Java的朋友可能知道如Ehcache等这种进程内本地缓存.Nginx是一个Master进 ...
- [转帖]直击案发现场!TCP 10倍延迟的真相是?
直击案发现场!TCP 10倍延迟的真相是? http://zhuanlan.51cto.com/art/201911/605268.htm 内核参数调优 非常重要啊. 什么是经验?就是遇到问题,解决问 ...
- 如何把 MySQL 备份验证性能提升 10 倍
JuiceFS 非常适合用来做 MySQL 物理备份,具体使用参考我们的官方文档.最近有个客户在测试时反馈,备份验证的数据准备(xtrabackup --prepare)过程非常慢.我们借助 Juic ...
随机推荐
- 比较并交换(compare and swap, CAS)
比较并交换(compare and swap, CAS),是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生 ...
- Java IO教程- Java文件
创建文件 我们可以从中创建一个 File 对象 路径名 父路径名和子路径名 URI(统一资源标识符) 我们可以使用File类的以下构造函数之一创建一个文件: File(String pathname) ...
- Redis项目搭建
Redis项目搭建 Redis下载 搭建redis首先需要下载Redis,可是Redis官方并没有Windows安装,好在网上从不缺大牛,Github上可以找到Redis的Windows版 下载地址: ...
- 又拍云+PicGo搭建图床教程
具体搭建方法 https://blog.csdn.net/qq_41684621/article/details/114068076 这里有个细节 注意这里一定要加上 http:// 否则在自动生成 ...
- BIRCH算法全解析:从原理到实战
本文全面解析了BIRCH(平衡迭代削减聚类层次)算法,一种用于大规模数据聚类的高效工具.文章从基础概念到技术细节,再到实战应用与最佳实践,提供了一系列具体的指导和例子.无论你是数据科学新手,还是有经验 ...
- 【uniapp】学习笔记day03 | 页面制作【外包杯】
一.开发层级结构介绍 page.json 对uniapp进行全局配置,决定页面文件的路径.窗口样式.原生的导航栏.底部的原生tabbbar manifest.json 应用的配置文件,指定应用的名称. ...
- Android学习day04【Button】
出现的一些小状况: 小状况 报错,代码显示运行成功 但是无法在模拟机上显示 原因是没有在包含应有id 其二是关于设置背景颜色中 关于background与backgroundTint的区别 //这是b ...
- 大数据 - MapReduce:从原理到实战的全面指南
本文深入探讨了MapReduce的各个方面,从基础概念和工作原理到编程模型和实际应用场景,最后专注于性能优化的最佳实践. 关注[TechLeadCloud],分享互联网架构.云服务技术的全维度知识.作 ...
- VScode 中利用virtualenv建立 Python 虚拟环境
! https://zhuanlan.zhihu.com/p/638114885 VScode 建立 Python 虚拟环境 主要目的:创建一个与默认 python 版本不同的 python 虚拟环境 ...
- [ABC263G] Erasing Prime Pairs
Problem Statement There are integers with $N$ different values written on a blackboard. The $i$-th v ...