kafka分区分配策略
前言
现有主流消息中间件都是生产者-消费者模型,主要角色都是:Producer -> Broker -> Consumer,上手起来非常简单,但仍有需要知识点需要我们关注,才能避免一些错误的使用情况,或者使用起来更加高效,例如本篇要讲的kafka分区分配策略。
在开始前我们先简单回顾一下kafka消息存储设计,如下图:
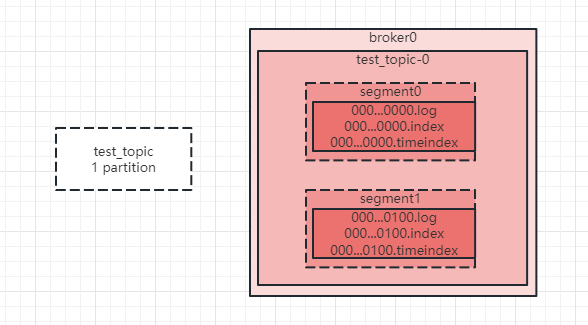
topic是一个逻辑概念,一个topic可以包含多个partition,partition才是物理概念,kafka将partition存储在broker磁盘上。如图,test_topic只有一个partition,那么在broker上就会一个test_topic-0的文件夹。在partition内部,kafka为方便管理和高效处理消息,进一步将消息的存储划分为多个segment,segment也是个逻辑概念,一个segment下主要包含:.log消息日志文件,存储实际消息的地方,.index索引文件,.timeindex时间索引文件。segment是滚动的,当达到配置的大小或者时间,kafka就会重新创建一个新的segment,并且会在一定的时间后将过期的segment删除。
其中每一个部分都是一个大的知识点,本次我们主要关注partition。一个partition会分配给一个consumer group中的一个consumer消费,partition是可扩展的,这为kafka消息消费提供强大扩展能力,如上只有一个patition,那么所有的消息都会发到这里,并且只能由一个消费者消费,这无疑会很慢。我们可以创建两个partition,然后起两个消费者,这样kafka就会为每个消费者分配一个分区,它们可以并发消费,消费速度得以提升。
那如果有3个partition呢,这个时候是怎么分的?如果有多个topic呢,这个时候又是怎么分的?如果有consumer上下线,又是怎么分呢?这就是我们接下来要讨论分区分配策略。
rebalance
在开始讨论分区分配策略之前,我们先了解一下rebalance这个概念。rebalance重平衡,是指在一定情况下,kafka将分区重新分配的过程。正常情况下我们的服务起来,分区分配好后,就稳定运行了,但一些情况下会导致kafka进行rebalance,将分区都重新分配一遍,这种情况主要包括:
- topic数发生了变化
- partition数发生了变化
- 消费者数发生了变化
- 消费者消费速度太慢,超过限制时间
举个例子,我们滚动发版,必然有的应用要先下线,再重新上线,这个时候对于kafka来说消费者就发生了变化,就会发生rebalance,rebalance也是按照我们配置的分区分配策略进行重新分配。
分区分配策略作用是将所有topic的partition按照一定规则分配给消费者,主要有4种分区分配策略,它们都实现了ConsumerPartitionAssignor接口,也可以实现该接口自定义分区分配算法。

分区的分配很容易会想到是有kafka server端计算和分配的,但其实不是,当触发分区分配时,kafka会从consumer中挑选一个作为leader,leader根据客户端配置的分配策略计算分区结果,然后发送回给kafka,再由kafka同步给其它的consumer follower。
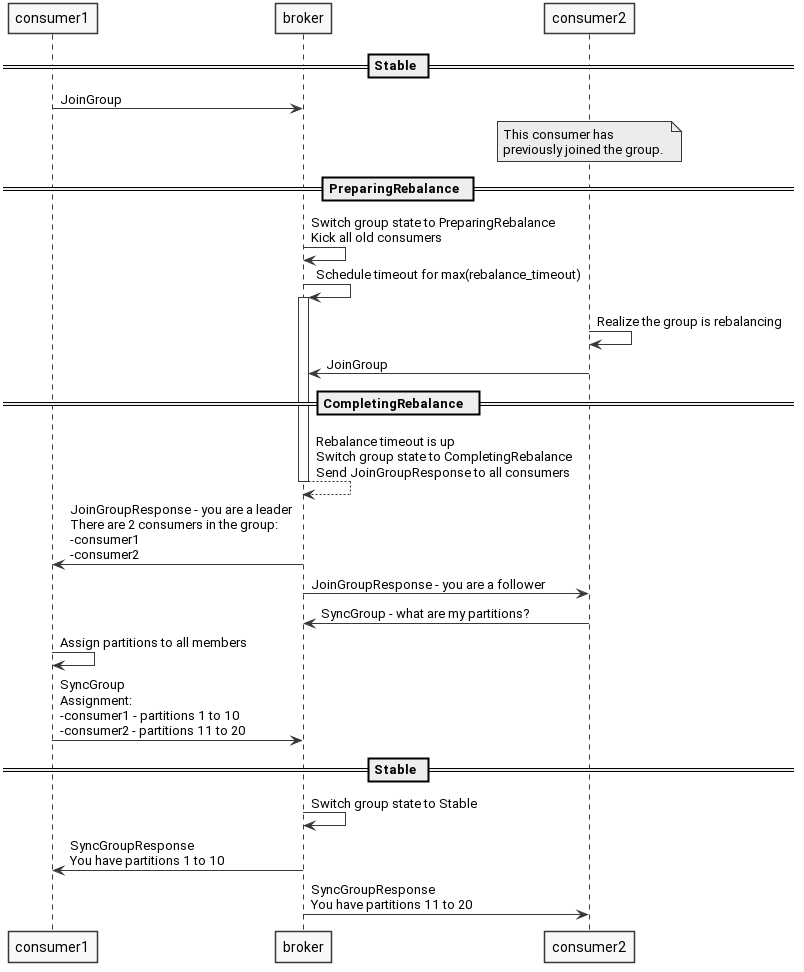
举个例子,新增了一个消费者,rebalance过程大致如下:
该消费者发送一个请求告诉kafka,要加入消费者组。
kafka将消费者组状态切换到准备rebalance,关闭和消费者的所有链接,等待它们重新加入。
客户端重新申请加入,kafka从消费者组中挑选一个作为leader,其它的作为follower。
kafka将一些元信息同步给所有消费者。
follower不断发送请求给kafka,请求它们的partition。
leader根据分区分配策略计算分区结果,并将结果返回给kafka。
kafka将计算结果返回给follower。
所有消费者根据分区结果开始消费消息。
注意,rebalance的发生不是个好事情,kafka需要重新计算分区信息,重新分配,清理资源,当你的集群比较大的时候,频繁rebalance可能会影响性能。
4种分区分配策略
RangeAssignor
范围分配,按照每个topic的partition数计算出每个消费者应该分配的分区数量,然后分配。
假设有2个topic,每个topic有2个分区,如下:
T0:P00,P01
T1:P10,P11
有两个消费者C0,C1,那么range分配结果如下:
C0:P00,P10
C1:P01,P11
看起来很顺畅,也很均衡,但如果T0新增一个P02呢,那么分配就会如下:
C0:P00,P01,P10
C1:P02,P11
看起来也还好,毕竟两个人分3个苹果,会有人多一个。那如果T1也新增一个P12呢,那么分配就会如下:
C0:P00,P01,P10,P11
C1:P02,P12
看起来好像不怎么好了,C0又多了一个分区,如果有更多的topic有这种情况,那么C0的压力无疑会比C1大很多。
这是由于range分配是按照每个topic来计算的,这可能会导致consumer的分配不均匀。
RoundRobinAssignor
循环分配,按照所有topic的partition循环分配。
假设有2个topic,每个topic有2个分区,如下:
T0:P00,P01
T1:P10,P11
有两个消费者C0,C1,那么循环分配结果如下:
C0:P00,P10
C1:P01,P11
如果T0新增一个P02呢,那么分配就会如下:
C0:P00,P02,P10
C1:P01,P11
如果T1也新增一个P12呢,那么分配就会如下:
C0:P00,P02,P11
C1:P01,P10,P12
和range不同这里每个消费者分到的分区数还是相等的。按照循环分配逻辑,消费者分配到分区数偏差不会超过1。
StickyAssignor
range和roundrobin的问题是,当发生rebalance的时候,分区的分配结果变化会很大,理想情况是分配结果不要有很大变化,例如消费者可能根据partition做了本地缓存,分配结果都变了相当于缓存都失效了,可能对消费者会有影响。所有有了StickAssignor,粘性分配,从字面理解,粘性分配就是原本是你的,还是尽量分配给你,例如发生rebalance的时候。粘性分配的核心思想是优先保证分区分配均衡,然后尽可能保留现有的分配结果。
假设有3个topic,每个topic有3个分区,如下:
T0:P00,P01,P02
T1:P10,P11,P12
T2:P20,P21,P22
有3个消费者C0,C1,C2,那么roundrobin分配结果如下:
C0:P00,P10,P20
C1:P01,P11,P21
C2:P02,P12,P22
假设C2下线了,触发了rebalance,roundrobin重新分配结果如下:
C0:P00,P02,P11,P20,P22
C1:P01,P10,P12,P21
可以看到T0,T1的也重新分配了,有4个partition重新分配了。如果使用sticky分配,结果就会是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
可以看到,T0,T1的没有任何变化,还是原来的消费者,这就是粘性的含义。
CooperativeStickAssignor
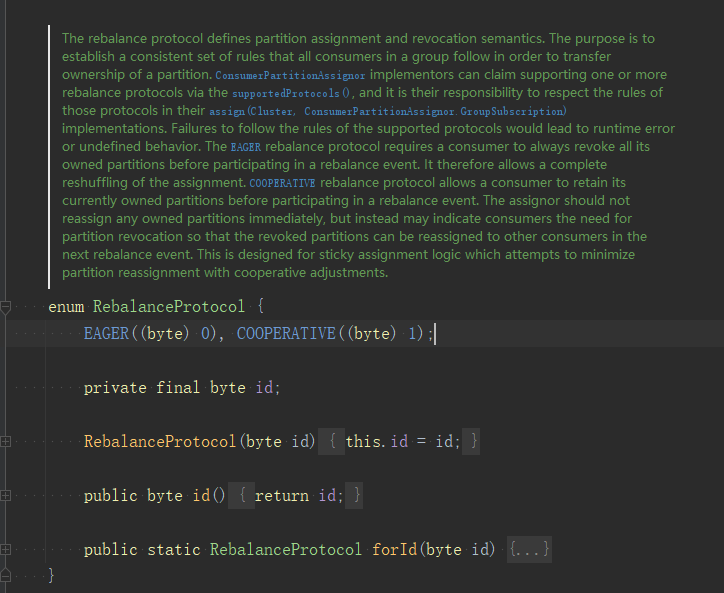
上面的3种分配策略使用的都是eager协议,eager协议的特点是整个rebalance会"stop the world",消费者会放弃当前的分区,关闭连接,资源清理,然后静静等待分配结果。
CooperativeStickAssignor是2.4版本开始提供的,使用的cooperative协议,在sticky的基础上,优化rebalance过程,可以从RebalanceProtocol源码中看到这两个协议的解释:
ConsumerPartitionAssignor接口默认就指定了eager协议,如图:
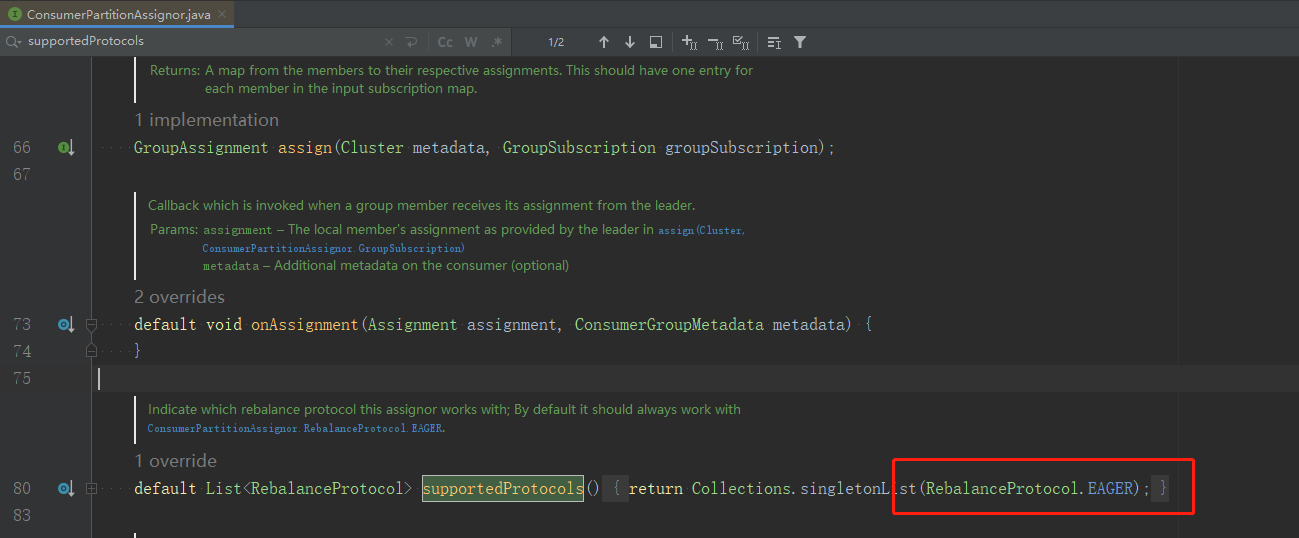
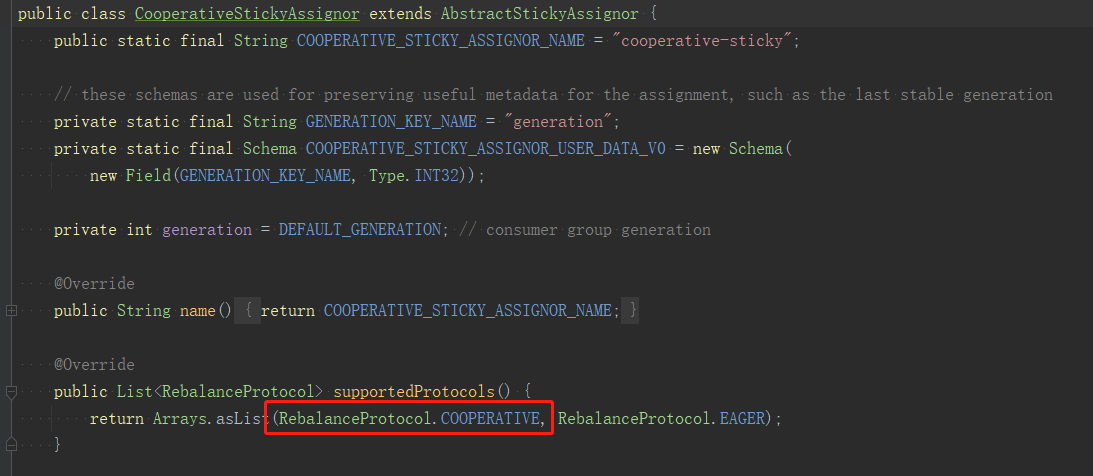
CooperativeStickAssignor重写了这个协议,使用cooperative,如图:
还是上面的例子,假设C2下线了,触发了rebalance,使用sticky分配,结果就会是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
看起来和sticky并没有什么区别,毕竟它们都是sticky,但实际过程上有很大的差别,sticky会先放弃所有的分区,清理数据,然后再重新分配,整个过程较复杂耗时,而coopertive则比较轻量,首先会将原来的分区分配给原来的持有者,再rebalance重新分配P20,P21,P22分区。
关于eager、cooperative协议可以参考这篇文章:https://www.cnblogs.com/listenfwind/p/14146727.html
总结
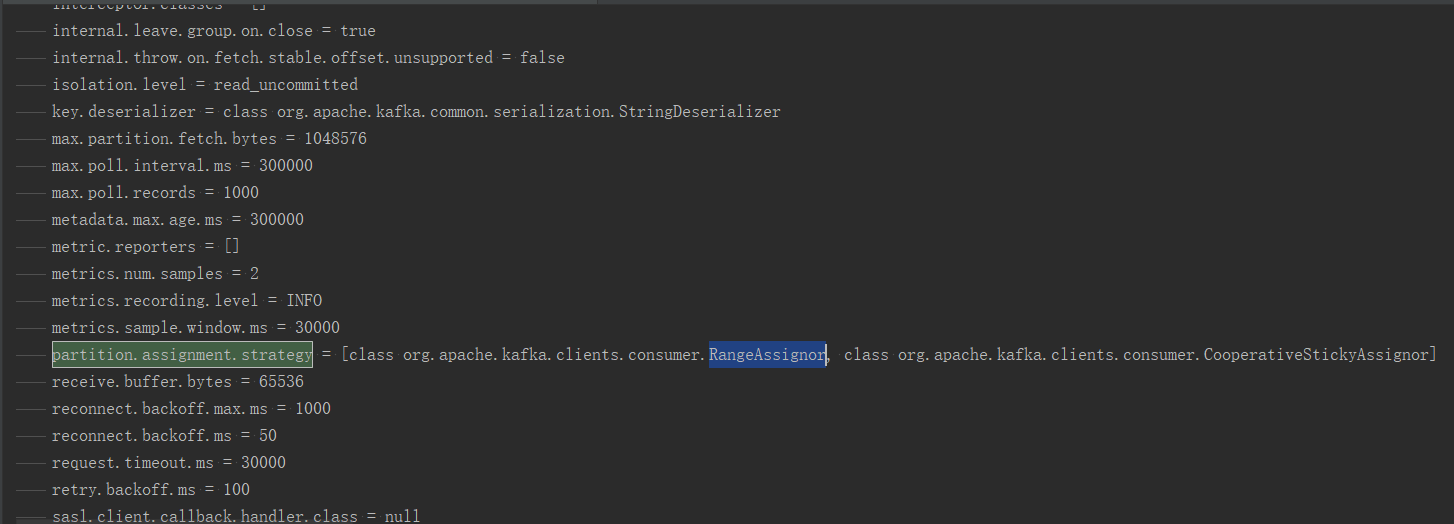
这4种分区分配策略是可以配置的,客户端通过partition.assignment.strategy参数进行设置,默认是RangeAssignor。
欢迎关注我的github:https://github.com/jmilktea/jtea
kafka分区分配策略的更多相关文章
- Kafka分区分配策略(Partition Assignment Strategy
问题 用过 Kafka 的同学用过都知道,每个 Topic 一般会有很多个 partitions.为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer ...
- Kafka分区分配策略分析——重点:StickyAssignor
“ 为什么Kafka在RangeAssigor.RoundRobinAssignor的基础上,又新增了PartitionAssignor,它解决了什么问题?” 背景 用过Kafka的同学应该都知道Ka ...
- Kafka分区分配策略-RangeAssignor、RoundRobinAssignor、StickyAssignor
引言按照Kafka默认的消费逻辑设定,一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者消费.假设目前某消费组内只有一个消费者C0,订阅了一个topic,这个topic包含7个分区 ...
- Kafka分区分配策略(Partition Assignment Strategy)
众所周知,Apache Kafka是基于生产者和消费者模型作为开源的分布式发布订阅消息系统(当然,目前Kafka定位于an open-source distributed event streamin ...
- Kafka消费分组和分区分配策略
Kafka消费分组,消息消费原理 同一个消费组里的消费者不能消费同一个分区,不同消费组的消费组可以消费同一个分区 Kafka分区分配策略 在 Kafka 内部存在两种默认的分区分配策略:Range 和 ...
- kafka的分区分配策略
用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions.为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会 ...
- Kafka分区与消费者的关系
1. 前言 我们知道,生产者发送消息到主题,消费者订阅主题(以消费者组的名义订阅),而主题下是分区,消息是存储在分区中的,所以事实上生产者发送消息到分区,消费者则从分区读取消息,那么,这里问题来了, ...
- Kafka 消费组消费者分配策略
body { margin: 0 auto; font: 13px / 1 Helvetica, Arial, sans-serif; color: rgba(68, 68, 68, 1); padd ...
- Kafka分区策略
Kafka分区策略 所谓分区策略是决定生产者将消息发送到哪个分区的算法.Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略. 常见的分区策略包含以下几种:轮询策略.随机策略 .按消息 ...
- kafka分区及副本在broker的分配
kafka分区及副本在broker的分配 部分内容參考自:http://blog.csdn.net/lizhitao/article/details/41778193 以下以一个Kafka集群中4个B ...
随机推荐
- API Gateway vs Load Balancer:选择适合你的网络流量管理组件
本文从对比了 API Gateway 和 Load Balancer 的功能区别,帮助读者更好地了解他们在系统架构中扮演的角色. 作者陈泵,API7.ai 技术工程师. 原文链接 由于互联网技术的发展 ...
- 10分钟带你徒手做个Java线程池
摘要:花10分钟开发一个极简版的Java线程池,让小伙伴们更好的理解线程池的核心原理. 本文分享自华为云社区<放大招了,冰河带你10分钟手撸Java线程池,yyds,赶快收藏吧>,作者:冰 ...
- 笔记五:进程间的通信(IPC通信之共享内存)
IPC通信 IPC通信(Inter-Process Communication) 三种: 共享内存.消息队列.信号灯 这个IPC对象,肯定是存在于内核中.而且用户空间的文件系统中有没有IPC的文件类型 ...
- linux安装tomcat,mysql
环境:centos7.6 ssh连接工具:tabby 安装tomcat 创建目录 mkdir /opt/tomcat 获取tomcat: 1.自己百度下载 2.我这里提供百度网盘 链接:https:/ ...
- bean的作用域和@scope注解
bean的作用域由@scope注解来修改,该注解有五个不同的取值,分别是:singleton.prototype.request.session.global-session. singleton,在 ...
- 2022-04-24:用go语言重写ffmpeg的muxing.c示例。
2022-04-24:用go语言重写ffmpeg的muxing.c示例. 答案2022-04-24: 本程序的大体过程如下: 打开输出文件并写入头部信息. 添加音频和视频流,并为每个流创建 AVCod ...
- 2022-08-15:k8s安装pgadmin,yaml如何写?
2022-08-15:k8s安装pgadmin,yaml如何写? 答案2022-08-15: yaml如下: # 依赖postgres.yaml apiVersion: apps/v1 kind: D ...
- 2021-01-31:Redis集群方案不可用的情况有哪些?
福哥答案2021-01-31:[答案来自此链接:](https://www.zhihu.com/question/442112697)一个集群模式的官方推荐最小最佳实践方案是 6 个节点,3 个 Ma ...
- 2021-04-07:给定一个非负数组arr,长度为N,那么有N-1种方案可以把arr切成左右两部分,每一种方案都有,min{左部分累加和,右部分累加和},求这么多方案中,min{左部分累加和,右部分累加和}的最大值是多少? 整个过程要求时间复杂度O(N)。
2021-04-07:给定一个非负数组arr,长度为N,那么有N-1种方案可以把arr切成左右两部分,每一种方案都有,min{左部分累加和,右部分累加和},求这么多方案中,min{左部分累加和,右部分 ...
- docker安装es,单机集群模式.失败。
操作系统:mac系统. docker run -d --name es1 -p 9201:9200 -p 9301:9300 elasticsearch:7.14.0 docker run -d -- ...