【转载】 NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研
原文地址:
https://www.cnblogs.com/xuyaowen/p/nccl-learning.html
------------------------------------------------------------------------------------------
为了了解,上来先看几篇中文博客进行简单了解:
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章)
- 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式测试)
- nvidia-nccl 学习笔记 (主要是一些接口介绍)
- https://developer.nvidia.com/nccl (官方网站)
- https://github.com/NVIDIA/nccl (官方仓库)
- https://www.cnblogs.com/xuyaowen/p/heterogeneous-system-architecture.html GPU 相关架构
- https://www.nvidia.cn/data-center/nvlink/ (NVLink)
- https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/overview.html (nccl doc)
内容摘录:
- 通信性能(应该主要侧重延迟)是pcie switch > 同 root complex (一个cpu接几个卡) > 不同root complex(跨cpu 走qpi)。ib(Infiniband?)的gpu direct rdma比跨cpu要快,所以甚至单机八卡要按cpu分成两组,每组一个switch,下面四个卡,一个ib,不通过cpu的qpi通信,而是通过ib通信。------------------ 摘自评论
- 对于多个GPU卡之间相互通信,硬件层面上的实现有Nvlink、PCIe switch(不经过CPU)、Infiniband、以及PCIe Host Bridge(通常就是借助CPU进行交换)这4种方式。而NCCL是Nvidia在软件层面对这些通信方式的封装。
保持更新,更多内容,请参考cnblogs.com/xuyaowen;
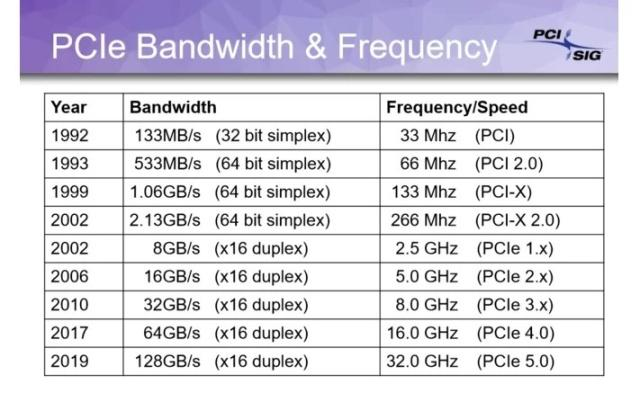
z390 芯片组资料:
https://ark.intel.com/content/www/cn/zh/ark/products/133293/intel-z390-chipset.html
P2P 显卡通信性能测试:
cuda/samples/1_Utilities/p2pBandwidthLatencyTest
nvidia 驱动安装:
https://www.cnblogs.com/xuyaowen/p/nvidia-driver-cuda-installation.html
nccl 编译安装过程:
git clone git@github.com:NVIDIA/nccl.git
cd nccl
make -j src.build (进行编译)
cd build
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/yourname/nccl/build/lib # 添加环境变量;也可以配置环境变量.bashrc;
export C_INCLUDE_PATH=/home/yourname/nccl/build/include (设置 C 头文件路径)
export CPLUS_INCLUDE_PATH=/home/yourname/nccl/build/include (设置C++头文件路径)
测试是否安装成功:
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl (具体编译,可以参考官方文档)
./build/all_reduce_perf -b 8 -e 256M -f 2 -g <ngpus>
才是
【转载】 NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研的更多相关文章
- NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;
为了了解,上来先看几篇中文博客进行简单了解: 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章) 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式 ...
- 基于英伟达Jetson TX1的GPU处理平台
基于英伟达Jetson TX1 GPU的HDMI图像输入的深度学习套件 [309] 本平台基于英伟达的Jetson TX1视觉计算的全功能开发板,配合本公司研发的HDMI输入图像采集板:Jetson ...
- 英伟达GPU 嵌入式开发平台
英伟达GPU 嵌入式开发平台 1. JETSON TX1 开发者组件 JETSON TX1 开发者组件是视觉计算的全功能 开发平台,旨在让您能够快速地安装和运行. 该组件带有 Lin ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 英伟达GPU虚拟化---申请英伟达测试License
此文基于全新的License 2.0系统,针对vGPU License的试用申请以及软件下载和License管理进行了详细的说明,方便今后我们申请测试License,快速验证GPU的功能. 试用步骤: ...
- Linux查看英伟达GPU信息
命令: nvidia-smi 结果:
- 【转载】failed to initialize nvml driver/library version mismatch ubuntu
英伟达驱动版本是384.130 显示的NVRM version: NVIDIA UNIX x86_64 Kernel Module是:384.130. 若是旧的版本就会出现如下问题. 这个问题出现的原 ...
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- 【转载】 os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"] = "0" (---------tensorflow中设置GPU可见顺序和选取)
原文地址: https://blog.csdn.net/Jamesjjjjj/article/details/83414680 ------------------------------------ ...
- MLHPC 2018 | Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
这篇文章主要介绍了一个名为Aluminum通信库,在这个库中主要针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 通信何时发生 一 ...
随机推荐
- Css var 简述
Css var 语法 var(custom-property-name, value) - custom-property-name 必须 变量必须以 --开头 后面可以是英文.数字连接符,区分大小写 ...
- 如何拥抱AI
从去年年初开始,AI技术真正走入了我们的日常生活.从OpenAI到如今字节跳动的coze,我们通过AI大模型可以做很多事情,工具和平台众多,如何选择和使用有必要总结一下. 编程和debug方面 尽管g ...
- 日志之log4j2和springboot
log4j2比logback好用. 现在之所有以spring采用logback,根据我个人的理解应该是某种非常特殊的理由.否则log4j2的性能比logback更好,且异步性能极好! 异步日志是log ...
- CLR via C# 笔记 -- 计算限制的异步操作(27)
1. 线程池基础. 创建和销毁线程是一个昂贵的操作,要耗费大量时间.太多的线程会浪费内存资源.由于操作系统必须调度可运行的线程并执行上下文切换,所以大多的线程还对性能不利.为了改善这个情况,CLR包含 ...
- 生成数字csv
csv文件: import time import mcpi.minecraft as minecraft import mcpi.block as block mc = minecraft.Mine ...
- uniapp+thinkphp5实现微信登录
前言 之前做了微信登录,所以总结一下微信授权登录并获取用户信息这个功能的开发流程. 配置 1.首先得在微信公众平台申请一下微信小程序账号并获取到小程序的AppID和AppSecret https:// ...
- xlookup与vlookup的区别
区别还是很大的,vlookup暂时扔不了.
- MySQL与Redis数据双写一致性工程落地案例
复习-面试题 多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它. 其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存. 后面的线程 ...
- Dawwin首位人工智能编程师,未来又会怎么样?
Darwinai是一家快速发展的视觉质量检测公司,为制造商提供端到端解决方案,以提高产品质量并提高生产效率.该公司的专利可解释人工智能(XAI)平台已被众多财富500强公司采用,可以轻松集成值得信赖的 ...
- [oeasy]python0090_极客起源_wozniac_苹果公司_Jobs_Wozniac
极客起源 回忆上次内容 上次回顾了 DEC公司的兴起 从IBM的大型机 到DEC的小型机Mini Computer 再到DEC的终端 VT-100 计算机基础元器件发生了进化 从ENIAC的 电子管 ...