1.1 Introduction中 Consumers官网剖析(博主推荐)
不多说,直接上干货!
一切来源于官网
http://kafka.apache.org/documentation/

Consumers
消费者(Consumers)
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。
队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。
在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。
Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。
消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
假如所有的消费者都在一个组中,那么这就变成了queue模型。
假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。
更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。
每个组包含数目不等的消费者, 一个组内多个消费者可以用来扩展性能和容错。正如下图所示:
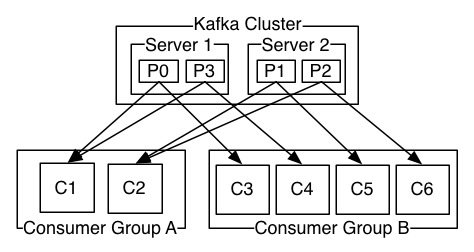
A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
2个kafka集群托管4个分区(P0-P3),2个消费者组,消费组A有2个消费者实例,消费组B有4个。
More commonly, however, we have found that topics have a small number of consumer groups, one for each "logical subscriber". Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.
The way consumption is implemented in Kafka is by dividing up the partitions in the log over the consumer instances so that each instance is the exclusive consumer of a "fair share" of partitions at any point in time. This process of maintaining membership in the group is handled by the Kafka protocol dynamically. If new instances join the group they will take over some partitions from other members of the group; if an instance dies, its partitions will be distributed to the remaining instances.
Kafka only provides a total order over records within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over records this can be achieved with a topic that has only one partition, though this will mean only one consumer process per consumer group.
正像传统的消息系统一样,Kafka保证消息的顺序不变。
再详细扯几句。传统的队列模型保持消息,并且保证它们的先后顺序不变。
但是, 尽管服务器保证了消息的顺序,消息还是异步的发送给各个消费者,消费者收到消息的先后顺序不能保证了。
这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚,消息的顺序处理很让人头痛。
如果只让一个消费者处理消息,又违背了并行处理的初衷。 在这一点上Kafka做的更好,尽管并没有完全解决上述问题。
Kafka采用了一种分而治之的策略:分区。
因为Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。
但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。
所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
1.1 Introduction中 Consumers官网剖析(博主推荐)的更多相关文章
- Flume Channel Selectors官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) 一切来源于flume官网 http://flume.apache.org/Flu ...
- Flume Channels官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) 一切来源于flume官网 http://flume.apache.org/FlumeUserGuide.html Flume Ch ...
- Flume Source官网剖析(博主推荐)
不多说,直接上干货! 一切来源于flume官网 http://flume.apache.org/FlumeUserGuide.html Flume Sources Avro Source Thrift ...
- 1.1 Introduction中 Guarantees官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Guarantees Kafka的保证(Guarantees) At a high- ...
- 1.1 Introduction中 Producers官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Producers 生产者(Producers) Producers publish ...
- 1.1 Introduction中 Distribution官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Distribution 分布式(Distribution) The partiti ...
- 1.2 Use Cases中 Metrics官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Metrics 指标 Kafka is often used for operati ...
- 1.2 Use Cases中 Messaging官网剖析(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ 下面是一些关于Apache kafka 流行的使用场景.这些领域的概述,可查看博客文 ...
- Flume Interceptors官网剖析(博主推荐)
不多说,直接上干货! Flume Sources官网剖析(博主推荐) Flume Channels官网剖析(博主推荐) Flume Channel Selectors官网剖析(博主推荐) Flume ...
随机推荐
- [Chromium文档转载,第001章] Mojo Migration Guide
For Developers > Design Documents > Mojo > Mojo Migration Guide 目录 1 Summary 2 H ...
- Python正则表达式初识(六)
继续分享Python正则表达式基础,今天给大家分享的正则表达式特殊符号是“[]”.中括号十分实用,其有特殊含义,其代表的意思是中括号中的字符只要满足其中任意一个就可以.其用法一共有三种,分别对其进行具 ...
- 《三》build 快速创建模块
一.将build.php文件复制一份放在 application目录下 二.修改build.php文件代码 <?php return [ 'home' => [ //需要生成的目录 '__ ...
- sublime text 2 licence
----- BEGIN LICENSE ----- Andrew Weber Single User License EA7E-855605 813A03DD 5E4AD9E6 6C0EEB94 BC ...
- Mirai僵尸网络重出江湖
近年数度感染数十万台路由器的僵尸网络程序Mirai,虽然原创者已经落网判刑,但是Mirai余孽却在网络上持续变种,现在安全人员发现,Mirai已经将焦点转向Linux服务器了. 安全公司Netcout ...
- IntelliJ IDEA 详细图解最常用的配置 ,适合刚刚用的新人。(转)
IntelliJ IDEA使用教程 (总目录篇) 刚刚使用IntelliJ IDEA 编辑器的时候,会有很多设置,会方便以后的开发,磨刀不误砍柴工. 比如:设置文件字体大小,代码自动完成提示,版本管理 ...
- Volley简单学习使用五—— 源代码分析三
一.Volley工作流程图: 二.Network 在NetworkDispatcher中须要处理的网络请求.由以下进行处理: NetworkResponse networkResponse = ...
- Redisclient连接方式Hiredis简单封装使用,连接池、屏蔽连接细节
工作须要对Hiredis进行了简单封装,实现功能: 1.API进行统一,对外仅仅提供一个接口. 2.屏蔽上层应用对连接的细节处理: 3.底层採用队列的方式保持连接池,保存连接会话. 4.重连时採用时间 ...
- idea python notebook连接pyspark
1.启动pyspark 2.查看pyspark服务的token jupyter notebook list 查看正在运行的notebook服务以及他们的token 3.在idea里运行noteboo ...
- inode与ln命令
inode可以看: http://www.cnblogs.com/itech/archive/2012/05/15/2502284.html 每个inode节点的大小,一般是128字节或256字节.i ...