纪录:Solr6.4.2+Flume1.7.0 +morphline+kafka集成
当前大多数企业版hadoop的solr版本都还停留在solr4.x,由于这个版本的solr本身的bug较多,使用起来会出很多奇怪的问题。如部分更新日期字段失败的问题。
最新的solr版本不仅修复了以前的一些常见bug,还提供了更简便易用的功能,如ManagedSchema替代schema.xml来管理索引的schema。
由于solr自带的接口和入库工具需要一些定制开发,所以通常用flume来作为数据采集的工具。数据流图如下:

具体见前文:《json数据处理实战:Kafka+Flume+Morphline+Solr+Hue数据组合索引》
在Cloudera等企业版hadoop中,Solr和Flume已经集成,并能互通。如果你目前的情况是使用Cloudera企业版,请看上面这篇文章。
然而由于集成的版本跟不上开源社区最新版本,还是很嫌弃的。于是就有了下面的配置最新版本的Solr和Flume互通:
1.Solr最新版服务部署及入门:
见solr官网quickstart。
http://lucene.apache.org/solr/quickstart.html
说明:创建Solr集合的部分,不是本章重点,所以这里没有介绍。
另,本例中和前文不同,使用的不是SolrCloud模式,而是单机的Solr。
2.Flume最新版部署及入门
下载地址:http://flume.apache.org/download.html
入门介绍:https://cwiki.apache.org//confluence/display/FLUME/Getting+Started
详细配置介绍:http://flume.apache.org/FlumeUserGuide.html
详细配置介绍中,需要关注的是KafkaSource和MorphlineSolrSink。
最终的flume.conf配置为:
kafka2solr.sources = source_from_kafka
kafka2solr.channels = customer_doc_channel
kafka2solr.sinks = solr_sink1 # For each one of the sources, the type is defined
kafka2solr.sources.source_from_kafka.type = org.apache.flume.source.kafka.KafkaSource
kafka2solr.sources.source_from_kafka.channels = customer_doc_channel
kafka2solr.sources.source_from_kafka.batchSize =
kafka2solr.sources.source_from_kafka.useFlumeEventFormat=false
kafka2solr.sources.source_from_kafka.kafka.bootstrap.servers= kafkanode0:,kafkanode1:,kafkanode2:
kafka2solr.sources.source_from_kafka.kafka.topics = tablecardLogin
kafka2solr.sources.source_from_kafka.kafka.consumer.group.id = catering_customer_core_070327
kafka2solr.sources.source_from_kafka.kafka.consumer.auto.offset.reset=earliest # Other config values specific to each type of channel(sink or source)
# can be defined as well
kafka2solr.channels.customer_doc_channel.type = file
kafka2solr.channels.customer_doc_channel.capacity=
kafka2solr.channels.customer_doc_channel.checkpointDir = /home/arli/data/flume-ng/customer_doc/checkpoint
kafka2solr.channels.customer_doc_channel.dataDirs = /home/arli/data/flume-ng/customer_doc/data kafka2solr.sinks.solr_sink1.type = org.apache.flume.sink.solr.morphline.MorphlineSolrSink
kafka2solr.sinks.solr_sink1.channel = customer_doc_channel
kafka2solr.sinks.solr_sink1.batchSize =
kafka2solr.sinks.solr_sink1.batchDurationMillis =
kafka2solr.sinks.solr_sink1.morphlineFile = /home/arli/flume-config/morphlines.conf
kafka2solr.sinks.solr_sink1.morphlineId=morphline1
kafka2solr.sinks.solr_sink1.isIgnoringRecoverableExceptions=true
#kafka2solr.sinks.solr_sink1.isProductionMode=true
3.新建一个Flume配置目录,下面四个文件是比较重要的。

flume.conf 来自上一节的配置。
flume-env.sh 来自安装目录conf下的flume-env.sh.template。需要改动。
log4j.properties 在调试过程中可以开启更低级别的日志打印。
morphline.conf 参考Morphline的文档:http://kitesdk.org/docs/current/morphlines/morphlines-reference-guide.html
4.接下来详细介绍上面的后三个配置文件。
1)flume-env.sh

需要改动的地方如上:
#默认的内存是不够的。需要扩大内存。
export JAVA_OPTS="-Xms100m -Xmx500m -Dcom.sun.management.jmxremote" #Flume官方下载的包少了一些Solr相关的包,需要把solr的lib目录加到flume的classpath下。
FLUME_CLASSPATH="/xxx/solr-6.4.2/contrib/morphlines-core/lib/*:/xxxi/solr-6.4.2/dist/*:/xxx/solr-6.4.2/dist/solrj-lib/*:/xxx/solr-6.4.2/server/solr-webapp/webapp/WEB-INF/lib/*"
2)log4j.properties
100MB改成10MB,以防打日志太多日志文件过大。
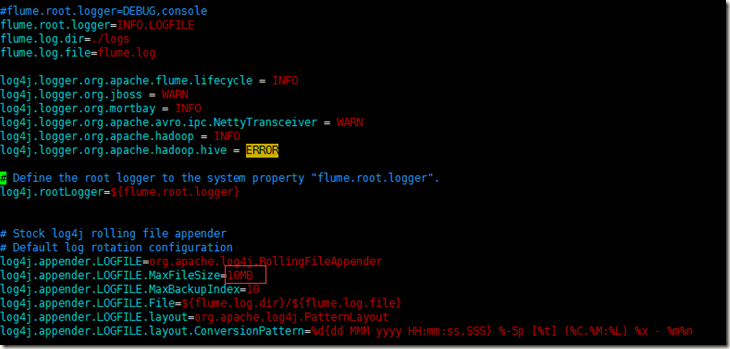
在调试阶段,加上如下两行会省心很多,调试完再去掉。
log4j.logger.org.apache.flume.sink.solr=DEBUG
log4j.logger.org.kitesdk.morphline=TRACE
3)morphline.conf
大部分和前文:《json数据处理实战:Kafka+Flume+Morphline+Solr+Hue数据组合索引》雷同。由于我使用的是单机版本的Solr,所以在配置时如下。
注意solrUrl和solrHomeDir的配置,在官网中没有介绍(因为morphline是cloudera开发并开源的,cloudera的solr默认是solrCloud),但是在源码阅读时可以看到这两个单机solr配置参数。
SOLR_LOCATOR : {
solrUrl : "http:\/\/localhost:8983\/solr\/catering_customer_core1"
solrHomeDir : "/xxx/server/solr/catering_customer_core1/conf"
}
morphlines : [
{
#customer morphline
id : morphline1
# Import all morphline commands in these java packages and their subpackages.
# Other commands that may be present on the classpath are not visible to this morphline.
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readJson {}
}
{
tryRules
{
catchExceptions : false
throwExceptionIfAllRulesFailed : true
rules : [
{
commands : [
{
contains {topic : [tablecardLogin] }
}
#field need to be indexed from json.
{
extractJsonPaths {
flatten : false
paths : {
account:/account
customer_id:/customerId
history_signin_dates:/opt_time
history_signin_timestamps:/opt_time
name:/name
sex:/sex
}
}
}
]
}
# if desired, the last rule can serve as a fallback mechanism
# for records that don't match any rule:
{
commands : [
{ logWarn { format : "Ignoring record with unsupported input format: {}", args : ["@{}"] } }
{ dropRecord {} }
]
}
]
}
}
{
convertTimestamp {
field : history_signin_dates
inputFormats : ["yyyy-MM-dd HH:mm:ss"]
inputTimezone : Asia/Shanghai
outputFormat : "yyyy-MM-dd'T'HH:mm:ss'Z/SECOND'"
outputTimezone : Asia/Shanghai
}
}
{
convertTimestamp {
field : history_signin_timestamps
inputFormats : ["yyyy-MM-dd HH:mm:ss"]
inputTimezone : Asia/Shanghai
outputFormat : "unixTimeInMillis"
outputTimezone : UTC
}
}
{
java {
imports : "import java.util.*;import org.kitesdk.morphline.api.Command;import org.kitesdk.morphline.api.Record;"
code: """
Object customerId = record.getFirstValue("customer_id");
Object account = record.getFirstValue("account");
record.put("id", account + "@" + customerId);
return child.process(record);
"""
}
}
{sanitizeUnknownSolrFields {solrLocator : ${SOLR_LOCATOR}}}
#将数据导入到solr中
{loadSolr {solrLocator : ${SOLR_LOCATOR}}}
]
}
]
4.Morphline中的sanitizeUnknownSolrFields命令需要有schema.xml才能使用。
Solr6.4.2的schema默认是用managed-schema文件管理的。如果上面配置中的solrHomeDir目录下没有shema.xml文件,则会报错。
好在managed-schema和之前schema.xml文件内容几乎一致。执行如下命令即可。
cp managed-schema schema.xml
5.解决Flume1.7.0和solr6.4.2的jar包冲突问题。
Flume1.7在编译时使用的是Solr4.10.1的包,而其中lib目录下,Solrj依赖的httpcore-4.1.3包已与最新的Solrj不兼容,因此在solr目录dist/solrj-lib下找到对应的包然后替换。

另外还需要清理的两种包:1.Flume的lib目录老的solr版本相关的包,2.若存在kite-morphline-solr-core(因为solr自己发布的版本已经包含了等价的solr-morphline-core包)则需要清理。(由于本文在写作时相应的包都已经清理了,所以记录的不够细节,望见谅。)
6.启动flume。调试时可以先在控制台启动,去掉最后的&。
bin/flume-ng agent --conf ~/flume-config/ -f ~/flume-config/flume.conf -n kafka2solr &
纪录:Solr6.4.2+Flume1.7.0 +morphline+kafka集成的更多相关文章
- flume-1.6.0单节点部署
这个不多说,直接上干货,部署很简单! 步骤一:flume的下载 当然,这里也可以使用wget命令在线下载,很简单,不多说. 步骤二:flume的上传 [hadoop@djt002 flume]$ ls ...
- Flume1.9.0的安装、部署、简单应用(含分布式、与Hadoop3.1.2、Hbase1.4.9的案例)
目录 目录 前言 什么是Flume? Flume的特点 Flume的可靠性 Flume的可恢复性 Flume的一些核心概念 Flume的官方网站在哪里? Flume在哪里下载以及如何安装? 设置环境变 ...
- Flume-1.4.0和Hbase-0.96.0整合
在使用Flume的时候,请确保你电脑里面已经搭建好Hadoop.Hbase.Zookeeper以及Flume.本文将以最新版的Hadoop-2.2.0.Hbase-0.96.0.Zookeeper-3 ...
- 在PHP应用中简化OAuth2.0身份验证集成:OAuth 2.0 Client
在PHP应用中简化OAuth2.0身份验证集成:OAuth 2.0 Client 阅读目录 验证代码流程 Refreshing a Token Built-In Providers 这个包能够让你 ...
- CDH下集成spark2.2.0与kafka(四十一):在spark+kafka流处理程序中抛出错误java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V
错误信息 19/01/15 19:36:40 WARN consumer.ConsumerConfig: The configuration max.poll.records = 1 was supp ...
- 如何在Cordova Android 7.0.0 以下版本集成最新插件 极光插件为例
前提 Cordova Android 7.0.0开始改变了项目安卓平台的架构.新建一个空项目分别添加Android 6.4.0 和 Android 7.0.0平台: cordova platform ...
- NET Core 2.0利用MassTransit集成RabbitMQ
NET Core 2.0利用MassTransit集成RabbitMQ https://www.cnblogs.com/Andre/p/9579764.html 在ASP.NET Core上利用Mas ...
- 使用 CircleCI 2.0 进行持续集成/持续部署
使用 CircleCI 2.0 进行持续集成/持续部署 - 简书https://www.jianshu.com/p/36af6af74dfc Signup - CircleCIhttps://circ ...
- Flume1.5.0的安装、部署、简单应用(含伪分布式、与hadoop2.2.0、hbase0.96的案例)
目录: 一.什么是Flume? 1)flume的特点 2)flume的可靠性 3)flume的可恢复性 4)flume 的 一些核心概念 二.flume的官方网站在哪里? 三.在哪里下载? 四.如何安 ...
随机推荐
- JS容易犯错的this和作用域
var someuser = { name: 'byvoid', func: function() { console.log(this.name); } }; var foo = { name: ' ...
- poj 2351 Farm Tour (最小费用最大流)
Farm Tour Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 17230 Accepted: 6647 Descri ...
- B1800 [Ahoi2009]fly 飞行棋 数学模拟
20分钟一遍AC,大水题,我的算法比较复杂,但是好理解,就是找可以凑出来一半周长的点来暴力枚举就行了. 题干: Description 给出圆周上的若干个点,已知点与点之间的弧长,其值均为正整数,并依 ...
- [Apple开发者帐户帮助]四、管理密钥(1)创建私钥以访问服务
私钥允许您访问和验证与某些应用服务(如APN,MusicKit和DeviceCheck)的通信.您将在对该服务的请求中使用JSON Web令牌(JWT)中的私钥. 所需角色:帐户持有人或管理员. 在“ ...
- 制作一个 JavaScript 小游戏
简评: 作者学习了编程两个月,边学边做了一个 JavaScript 小游戏,在文中总结了自己在这个过程中的一些体会,希望能给其他初学者一些帮助. 对于很多想学编程但一直没下定决心的同学来说,最大的问题 ...
- 基于CGAL的Delaunay三角网应用
目录 1. 背景 1.1 CGAL 1.2 cgal-bindings(Python包) 1.3 vtk-python 1.4 PyQt5 2. 功能设计 2.1 基本目标 2.2 待实现目标 3. ...
- Redis学习笔记(二)-key相关命令
Redis支持的各种数据类型包括string,list ,set ,sorted set 和hash . Redis本质上一个key-value db,所以我们首先来看看他的key.首先key也是字符 ...
- index seek和index scan 提高sql 效率
index seek和index scan 提高sql 效率解释解释index seek和index scan:索引是一颗B树,index seek是查找从B树的根节点开始,一级一级找到目标行.ind ...
- Linux rsync配置用于服务器之间传输大量的数据
Linux的rsync 配置,用于服务器之间远程传大量的数据 [教程主题]:rsync [课程录制]: 创E [主要内容] [1] rsync介绍 Rsync(Remote Synchronize ...
- (转)基于MVC4+EasyUI的Web开发框架经验总结(14)--自动生成图标样式文件和图标的选择操作
http://www.cnblogs.com/wuhuacong/p/4093778.html 在很多Web系统中,一般都可能提供一些图标的选择,方便配置按钮,菜单等界面元素的图标,从而是Web系统界 ...