Unpaired/Partially/Unsupervised Image Captioning
这篇涉及到以下三篇论文:
Unpaired Image Captioning by Language Pivoting (ECCV 2018)
Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data (ECCV 2018)
Unsupervised Image Caption (CVPR 2019)
1. Unpaired Image Captioning by Language Pivoting (ECCV 2018)
Abstract
作者提出了一种通过语言枢轴(language pivoting)的方法来解决没有成对的图片和描述的image caption问题(unpaired image captioning problem)。
Our method can effectively capture the characteristics of an image captioner from the pivot language(Chinese) and align it to the target language (English) using another pivot-target (Chinese-English) sentence parallel corpus.
Introduction
由于encoder-decoder结构需要大量的image-caption pairs来训练,通常这样的大规模标记数据是难以获得的,研究人员开始思考通过非成对的数据或者是用半监督的方法来利用其他领域成对的标记数据来实现无监督学习的目的。在本文中,作者希望通过使用源语言——中文作为枢轴语言,来消除输入图片和目标语言——英文描述之间的间隔,这需要有图片——中文描述以及中文——英文两个成对的数据集,从而达到不需要有图片——英文描述成对数据集来实现图片到英文描述生成的目的。
作者说这种思想来源于机器翻译领域的相关研究,使用这种策略的机器翻译方法通常分为两步,首先将源语言翻译成枢轴语言,然后将枢轴语言翻译成目标语言。但是image caption与机器翻译又有很多不同的地方:1.image-Chinese caption和Chinese-English中句子的风格和词汇分布有很大区别;2.source-to-pivot转换的错误会传递到pivot-to-target
Use AIC-ICC and AIC-MT as the training datasets and two datasets (MSCOCO and Flickr30K) as the validation datasets
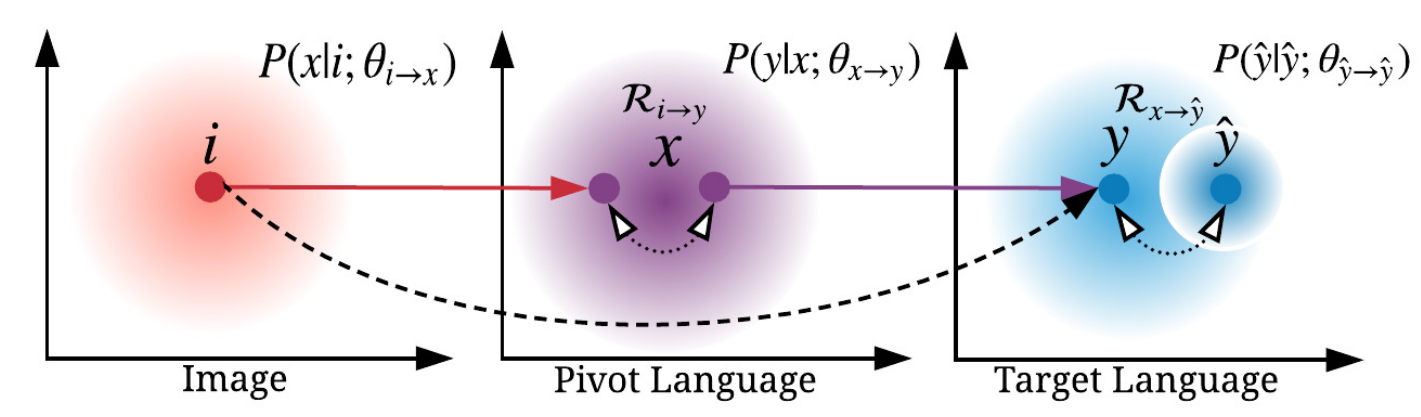
i: source image, x: pivot language sentence, y: target language, y_hat: ground truth captions in target language(对于这里的y_hat,是从MSCOCO训练集里面随机抽取的描述性语句(captions),用来训练下autoencoder)
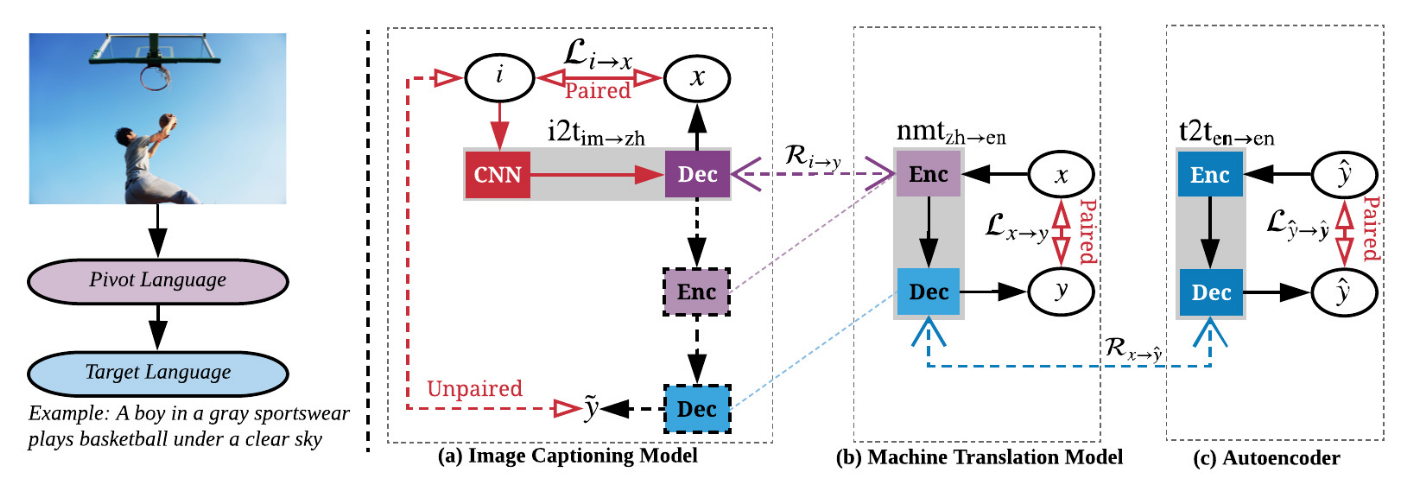
这篇文章的思想比较容易理解,难点是把Image-to-Pivot和Pivot-to-Target联系起来,克服两个数据集语言风格和词汇分布不一致这两个问题。
2. Show, Tell and Discriminate: Image Captioning by Self-retrieval with Partially Labeled Data (ECCV 2018)
作者在这篇文章中指出,目前已有的caption模型倾向于复制训练集中的句子或短语,生成的描述通常是泛化和模板化的,缺乏生成区分性描述的能力。
基于GAN的caption模型可以提升句子的多样性,但在标准的评价指标上会有比较差的表现。
作者提出在Captioning Module上结合一个Self-retrieval Module,来达到generate discriminative captions的目的。
3. Unsupervised Image Caption (CVPR 2019)
这是一篇真正的无监督方法来做Image Caption的文章,不 rely on any labeled image sentence pairs
与Unsupervised Machine Translation相比,Unsupervised Image Caption任务更具挑战是因为图像和文本是两个不同的模态,有很大的差别。
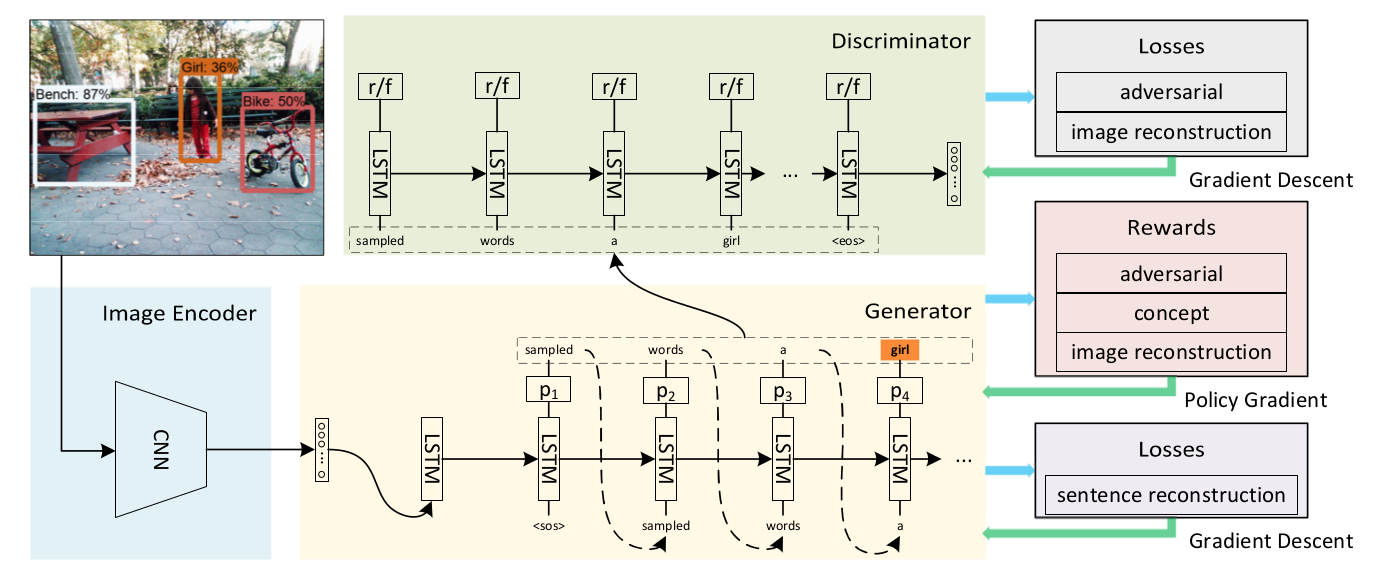
模型由an image encoder, a sentence generator,a sentence discriminator组成。
Encoder:
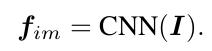
普通的image encoder即可,作者采用的是Inception-V4
Generator:
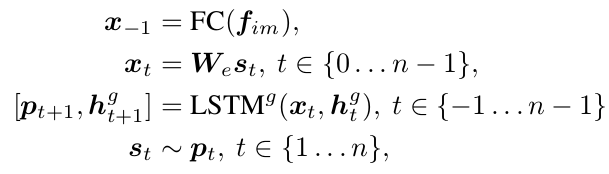
由LSTM组成的decoder
Discriminator:
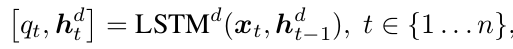
由LSTM来实现,用来distinguish whether a partial sentence is a real sentence from the corpus or is generated by the model.
Training:
由于do not have any paired image-sentence,就不能用有监督的方式来训练模型了,于是作者设计了三种目标函数来实现Unsupervised Image Captioning
Adversarial Caption Generation:
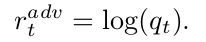
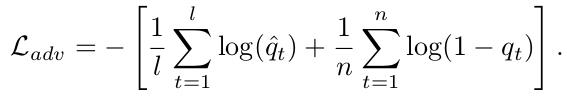
Visual Concept Distillation:

Bi-directional Image-Sentence Reconstruction:
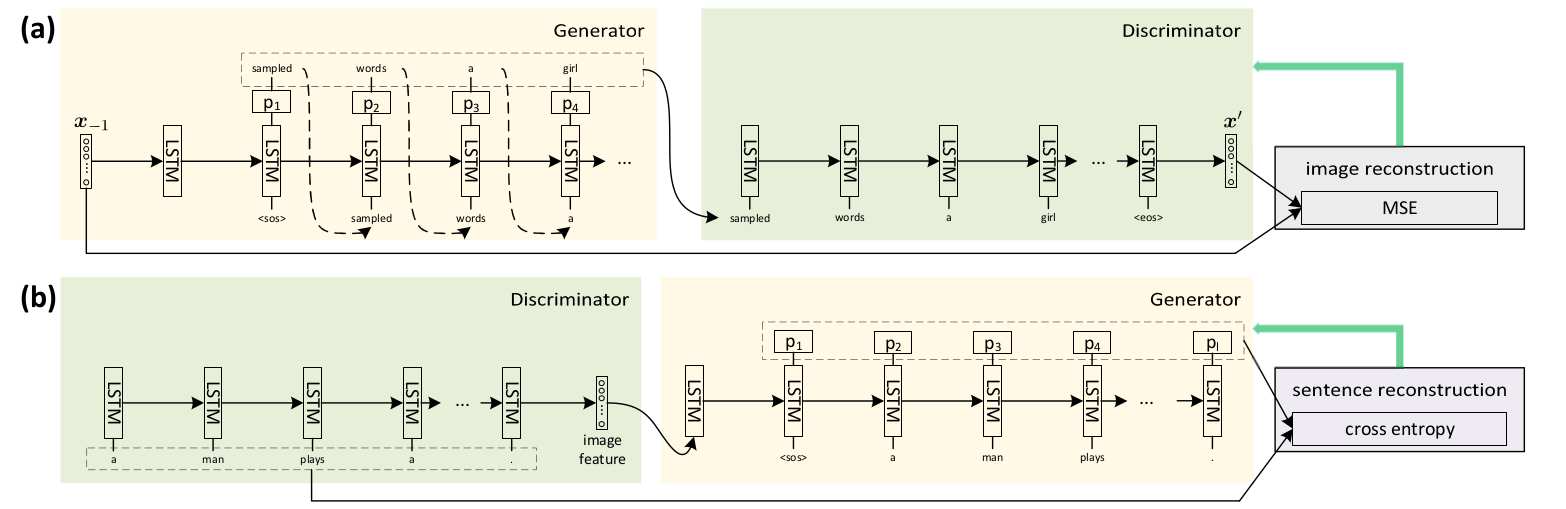
Image Reconstruction: reconstruct the image features instead of the full image
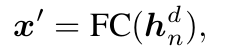
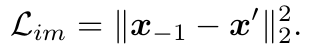
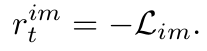
Sentence Reconstruction: the discriminator can encode one sentence and project it into the common latent space, which can be viewed as one image representation related to the given sentence. The generator can reconstruct the sentence based on the obtained representation.
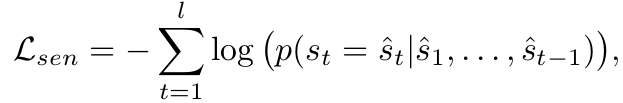
Integration:Generator:

Discriminator:
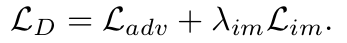
Initialization
It challenging to adequately train our image captioning model from scratch with the given unpaired data, need an initialization pipeline to pre-train the generator and discriminator.
For generator:
Firstly, build a concept dictionary consisting of the object classes in the OpenImages dataset
Second, train a concept-to-sentence(con2sen) model using the sentence corpus only
Third, detect the visual concepts in each image using the existing visual concept detector. Use the detected concepts and the concept-to-sentence model to generate a pseudo caption for each image
Fourth, train the generator with the pseudo image-caption pairs
For discriminator, initialized by training an adversarial sentence generation model on the sentence corpus.
Unpaired/Partially/Unsupervised Image Captioning的更多相关文章
- Image Captioning代码复现
Image caption generation: https://github.com/eladhoffer/captionGen Simple encoder-decoder image capt ...
- ( 转) Awesome Image Captioning
Awesome Image Captioning 2018-12-03 19:19:56 From: https://github.com/zhjohnchan/awesome-image-capti ...
- 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》论文笔记
Code Address:https://github.com/junyanz/CycleGAN. Abstract 引出Image Translating的概念(greyscale to color ...
- Image Captioning 经典论文合辑
Image Caption: Automatically describing the content of an image domain:CV+NLP Category:(by myself, y ...
- Video Captioning 综述
1.Unsupervised learning of video representations using LSTMs 方法:从先前的帧编码预测未来帧序列 相似于Sequence to sequen ...
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- 论文笔记之:Deep Recurrent Q-Learning for Partially Observable MDPs
Deep Recurrent Q-Learning for Partially Observable MDPs 摘要:DQN 的两个缺陷,分别是:limited memory 和 rely on b ...
- Unsupervised Classification - Sprawl Classification Algorithm
Idea Points (data) in same cluster are near each others, or are connected by each others. So: For a ...
随机推荐
- 关于http传输base64加密串的问题
问题场景: 在使用luacurl进行http post请求的时候,post的内容是一串json串.json传里面的某个字段带上了base64加密的串. 如post的内容如下: xxxxxx{" ...
- 【u207】最小值
Time Limit: 1 second Memory Limit: 128 MB [问题描述] N个数排成一排,你可以任意选择连续的若干个数,算出它们的和.问该如何选择才能使得和的绝对值最小. 如: ...
- 《学习opencv》笔记——关于一些画图的函数
画图函数 (1)直线cvLine函数 其结构 void cvLine(//画直线 CvArr* array,//画布图像 CvPoint pt1,//起始点 CvPoint pt2,//终点 CvSc ...
- JavaScript经典面试题(二)
前言: 近年来T行业就业者越来越多,有关于编程行业的高薪工作也变得越来越难找,竞争力越来越大,想要在众多的应聘者当中脱颖而出,面试题和笔试题一定要多加研究和琢磨,以下记录的是自己的面试过程之中遇到的一 ...
- erlang与c之间的连接
http://blog.chinaunix.net/uid-22566367-id-382012.html erlang与c之间的连接参考资料:网络资料作者:Sunny 在Programming ...
- java中<T> T和T的区别?
如果你希望 getMax 方法的返回值类型为 T,就要这样去定义getMax方法: public T getMax() 如果你希望 getMax 方法返回值的类型由调用者决定,那么就这么去定义 get ...
- 【56.74%】【codeforces 732B】Cormen --- The Best Friend Of a Man
time limit per test1 second memory limit per test256 megabytes inputstandard input outputstandard ou ...
- AbsoluteLayout绝对布局
1.四大控制属性(单位都是dp): ①控制大小: android:layout_width:组件宽度 android:layout_height:组件高度 ②控制位置: android:layout_ ...
- Python Tricks(二十二)—— small tricks
多次 import import numpy as np, matplotlib.pyplot as plt ndarray 的强制类型转换 v = v.astype(np.int) python 的 ...
- XamlReader 动态加载XAML
原文:XamlReader 动态加载XAML XAML: <Grid xmlns:x="http://schemas.microsoft.com/client/2006" x ...