zookeeper+activemq高可用集群搭建
一、准备工作:
准备三台机器:
192.168.35.111
192.168.35.112
192.168.35.113
二、搭建zookeeper
三台机器上均要搭建zookeeper服务
// 下载zookeeper安装包
# wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
# tar -xvf zookeeper-3.4..tar.gz -C /opt
# cd /opt/zookeeper-3.4./conf/
# cp zoo_sample.cfg zoo.cfg
// 修改zoo.cfg文件
# grep -Ev '#|^$' zoo.cfg
tickTime=
initLimit=
syncLimit=
dataDir=/opt/zookeeper-3.4./data_zookeeper
clientPort=
server.=192.168.35.111::
server.=192.168.35.112::
server.=192.168.35.113::
// 第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
这一步很重要,如果顺序对应的数字不对,,会导致zookeeper服务启动失败
server.1服务器:echo 1 > /opt/zookeeper-3.4.10/zookeeper/myid
server.2服务器:echo 2 > /opt/zookeeper-3.4.10/zookeeper/myid
server.3服务器:echo 3 > /opt/zookeeper-3.4.10/zookeeper/myid
// 启动zookeeper服务
# /opt/zookeeper-3.4./bin/zkServer.sh start #启动服务
# /opt/zookeeper-3.4./bin/zkServer.sh stop #停止服务
# /opt/zookeeper-3.4./bin/zkServer.sh restart #重启服务
# /opt/zookeeper-3.4./bin/zkCli.sh #连接集群
三、搭建activemq集群
三台机器上均要搭建activemq服务
// 下载activemq安装包
# wget https://archive.apache.org/dist/activemq/5.12.0/apache-activemq-5.12.0-bin.tar.gz
# tar -xvf apache-activemq-5.12.-bin.tar.gz -C /opt
// 修改配置文件 activemq.xml,使用性能比较好的LevelDB替换掉默认的KahaDB
brokerName 一定要设置相同
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="activemq-test" dataDirectory="${activemq.data}">
禁掉 原来的 < kahaDB directory="${activemq.data}/kahadb"/ >
<persistenceAdapter>
<!--kahaDB directory="${activemq.data}/kahadb"/ -->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:62621"
zkAddress="192.168.35.111:2181,192.168.35.112:2182,192.168.35.113:2183"
hostname="192.168.37.111" # 设为当前主机的ip
zkPath="/activemq/leveldb-stores"/>
</persistenceAdapter>
配置项说明:
directory:持久化数据存放地址
replicas:集群中节点的个数
bind:集群通信端口
zkAddress:ZooKeeper集群地址
hostname:当前服务器的IP地址,如果集群启动的时候报未知主机名错误,那么就需要配置主机名到IP地址的映射关系。
zkPath:ZooKeeper数据挂载点
至此,ActiveMQ的高可用集群搭建完成。
四、启动集群
前提:ZooKeeper集群已启动
分别启动三台ActiveMQ服务器
# /opt/apache-activemq-5.12./bin/activemq start // 启动activemq服务
# /opt/apache-activemq-5.12./bin/activemq stop // 结束activemq服务
# /opt/apache-activemq-5.12./bin/activemq restart // 重启activemq服务
# /opt/apache-activemq-5.12./bin/activemq status // 查看activemq服务状态
集群启动成功后,ActiveMQ会往ZooKeeper中注册集群信息。为了方便,我们使用ZooInspector工具来查看具体的内容。
第一条注册信息:
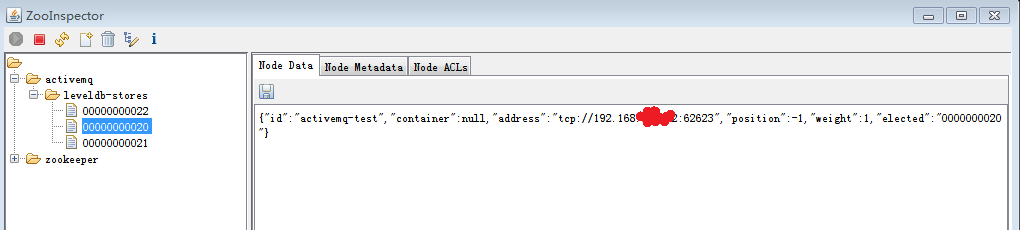
其他两个
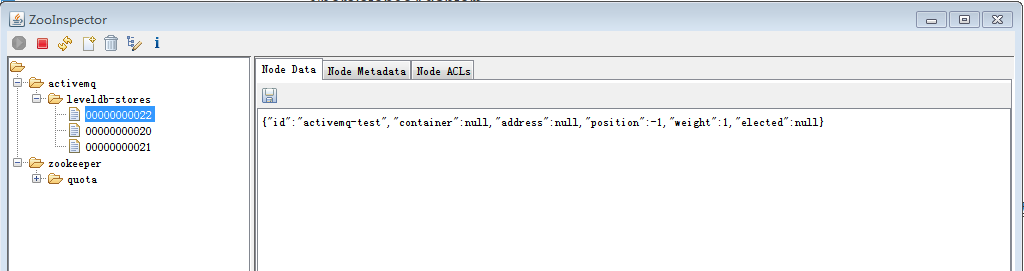
从以上三条注册信息的内容我们可以看出,(192.168.35.182)被选举为主节点,并对外提供服务,其余两个节点作为从节点,处于待机状态,不提供服务。
知道了ActiveMQ集群的主节点后,我们可以使用浏览器来访问它的管理页面,查看它是否能正常提供服务.

五、测试集群的高可用性
关掉主节点,使用ZooInspector工具来查看具体的内容,发现主节点的ip地址换了,并且节点显示只剩下两个。
zookeeper+activemq高可用集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- ActiveMQ 高可用集群安装、配置(ZooKeeper + LevelDB)
ActiveMQ 高可用集群安装.配置(ZooKeeper + LevelDB) 1.ActiveMQ 集群部署规划: 环境: JDK7 版本:ActiveMQ 5.11.1 ZooKeeper 集群 ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- Hbase 完全分布式 高可用 集群搭建
1.准备 Hadoop 版本:2.7.7 ZooKeeper 版本:3.4.14 Hbase 版本:2.0.5 四台主机: s0, s1, s2, s3 搭建目标如下: HMaster:s0,s1(备 ...
- HDFS-HA高可用集群搭建
HA高可用集群搭建 1.总体集群规划 在hadoop102.hadoop103和hadoop104三个节点上部署Zookeeper. hadoop102 hadoop103 hadoop104 Nam ...
- SpringCloud全家桶学习之服务注册与发现及Eureka高可用集群搭建(二)
一.Eureka服务注册与发现 (1)Eureka是什么? Eureka是NetFlix的一个子模块,也是核心模块之一.Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故 ...
随机推荐
- AESTest
using Gaea.MySql; using System; using System.Data; using System.IO; using System.Security.Cryptograp ...
- MySQL 查看约束,添加约束,删除约束 添加列,修改列,删除列
查看表的字段信息:desc 表名; 查看表的所有信息:show create table 表名; 添加主键约束:alter table 表名 add constraint 主键 (形如:PK_表名) ...
- Vim常用操作集合
基本上 vi/vim 共分为三种模式,分别是一般命令模式(Command mode),编辑模式(Insert mode)和命令行模式(Last line mode). 命令模式: 用户刚刚启动 vi/ ...
- 【VS开发】【Linux开发】【DSP开发】如何截获以太网帧并解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 3 ...
- Spring Boot(2)中的yaml配置简介
搞Spring Boot的小伙伴都知道,Spring Boot中的配置文件有两种格式,properties或者yaml,一般情况下,两者可以随意使用,选择自己顺手的就行了,那么这两者完全一样吗?肯定不 ...
- PHP 调用shell命令
可以使用的命令: popenfpassthrushell_execexecsystem 1.popen resource popen ( string command, string mode ) 打 ...
- Largest Number At Least Twice of Others
In a given integer array nums, there is always exactly one largest element. Find whether the largest ...
- 如何使用JavaScript实现前端导入和导出excel文件
一.SpreadJS 简介 SpreadJS 是一款基于 HTML5 的纯 JavaScript 电子表格和网格功能控件,以“高速低耗.纯前端.零依赖”为产品特色,可嵌入任何操作系统,同时满足 .NE ...
- 接口自动化框架 - httprunner 引用unittest
httprunner其中一个比较好的点就是利用type动态创建类,使用setattr动态增加方法和属性. 将维护的用例进行转变为继承unittest.Textcase的类,很好的与unittest结合 ...
- codeforces 842C Ilya And The Tree (01背包+dfs)
(点击此处查看原题) 题目分析 题意:在一个树中,有n个结点,记为 1~n ,其中根结点编号为1,每个结点都有一个值val[i],问从根结点到各个结点的路径中所有结点的值的gcd(最大公约数)最大是多 ...