Python2下载单张图片和爬取网页图片
一、需求分析
1、知道图片的url地址,将图片下载到本地。
2、知道网页地址,将图片列表中的图片全部下载到本地。
二、准备工作
1、开发系统:win7 64位。
2、开发环境:python2.7。
3、开发工具:PyCharm。
4、浏览器:Chrome。
三、操作步骤
A.知道图片的url地址,将图片下载到本地。
a1、打开Chrome,随意找到一个图片网站。
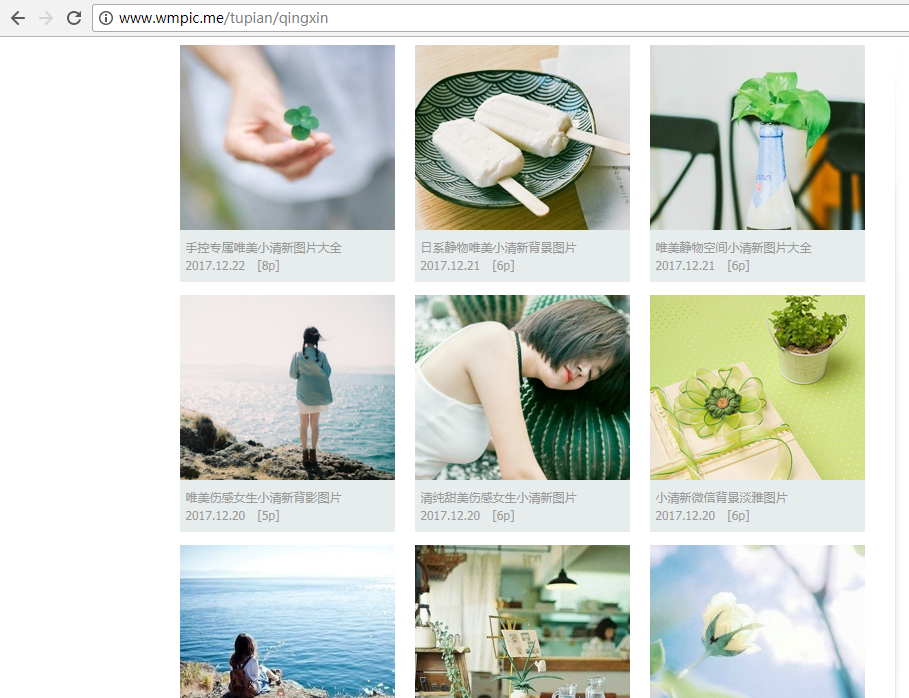
a2、打开开发者工具(f12键或者fn+f12键),选择第一张图片,可以看到它的src属性就是图片的地址,复制出来。
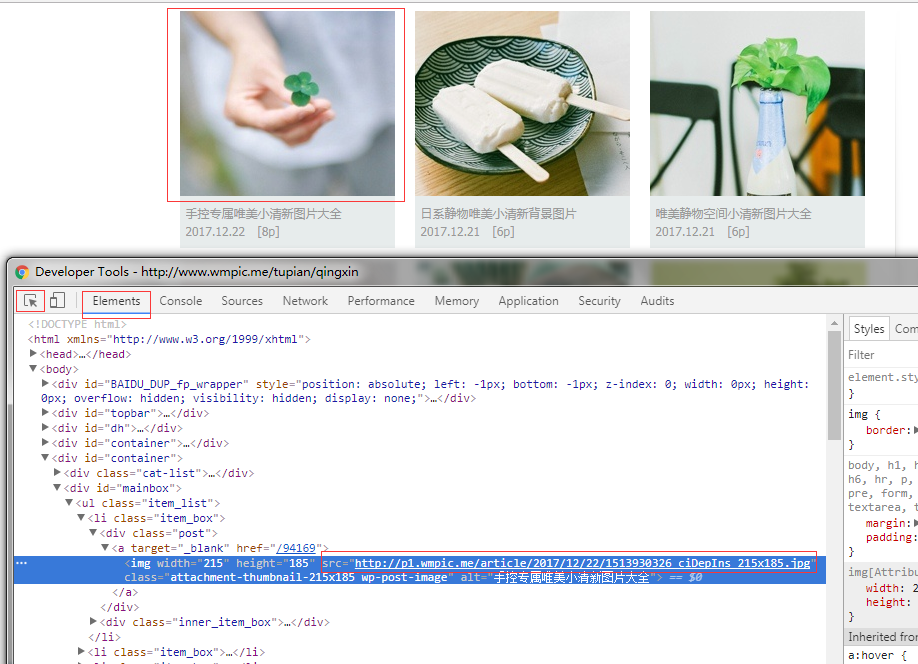
a3、编写代码。这里需要引用urllib库以及使用Python IO相关的知识。
# -*- coding:utf-8 -*
'''
知道图片地址,下载图片到本地
'''
import urllib #图片url地址
url = 'http://p1.wmpic.me/article/2017/12/22/1513930326_ciDepIns_215x185.jpg'
#方法一
#获取图片数据
res = urllib.urlopen(url).read()
#文件要保存的路径名和文件名
path = "e:\dlimg\pic2.jpg"
#使用io写入图片
f = open(path , "wb")
f.write(res)
f.close()
#方法二
res2 = urllib.urlretrieve(url , 'e:\dlimg\pic3.jpg')
B.知道网页地址,将图片列表中的图片全部下载到本地。
b1、还是以上面的网页为爬取对象,在该网页下,图片列表中有30张照片,获取每张图片的src属性值,再来下载即可。
b2、利用BeautifulSoup解析网页,利用标签选择器获取每张图片的src属性值。
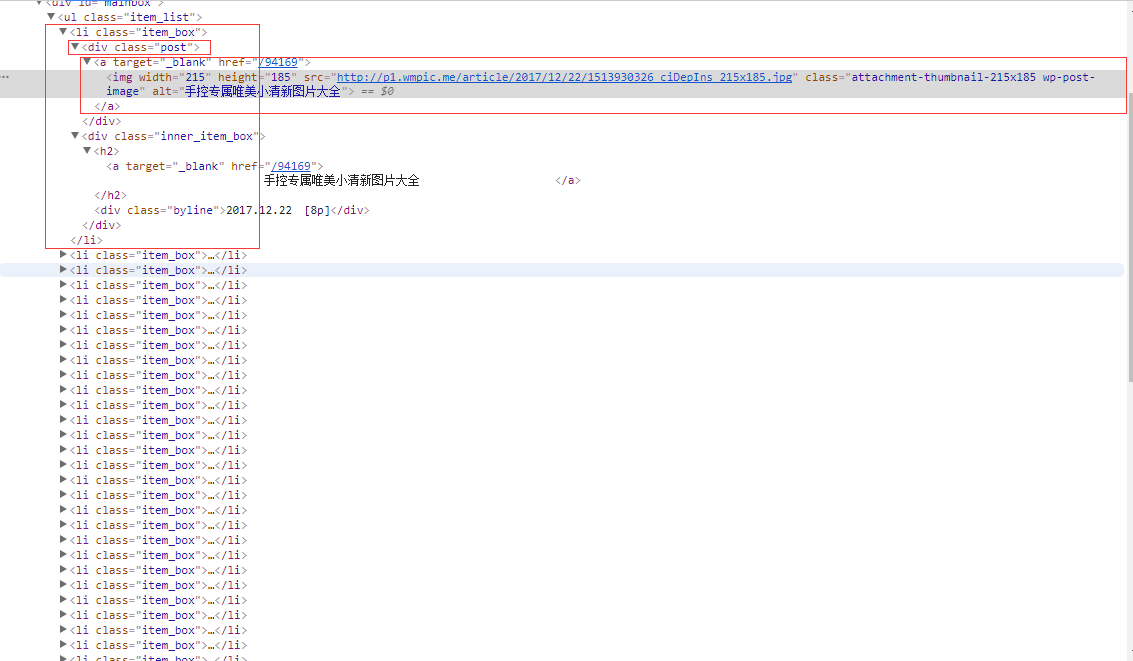
b3、编写代码。
# -*- coding: utf-8 -*- import requests
import urllib
from bs4 import BeautifulSoup url = 'http://www.wmpic.me/tupian/qingxin'
res = requests.get(url)
#使用BeautifulSoup解析网页
soup = BeautifulSoup(res.text , 'html.parser')
#通过标签选择器定位到图片位置(与css选择器差不多)
pic_list = soup.select('.item_box .post a img')
i = 0
for img_url in pic_list:
#获取每个img标签的src属性
url_list = img_url['src']
#保存路径,后面是文件名
save_path = 'E:\dlimg\\'+'downloadpic_'+str(i)+'.jpg'
#解析图片,写入到本地
pic_file = urllib.urlopen(url_list).read()
f = open(save_path, "wb")
f.write(pic_file)
f.close()
i = i+1
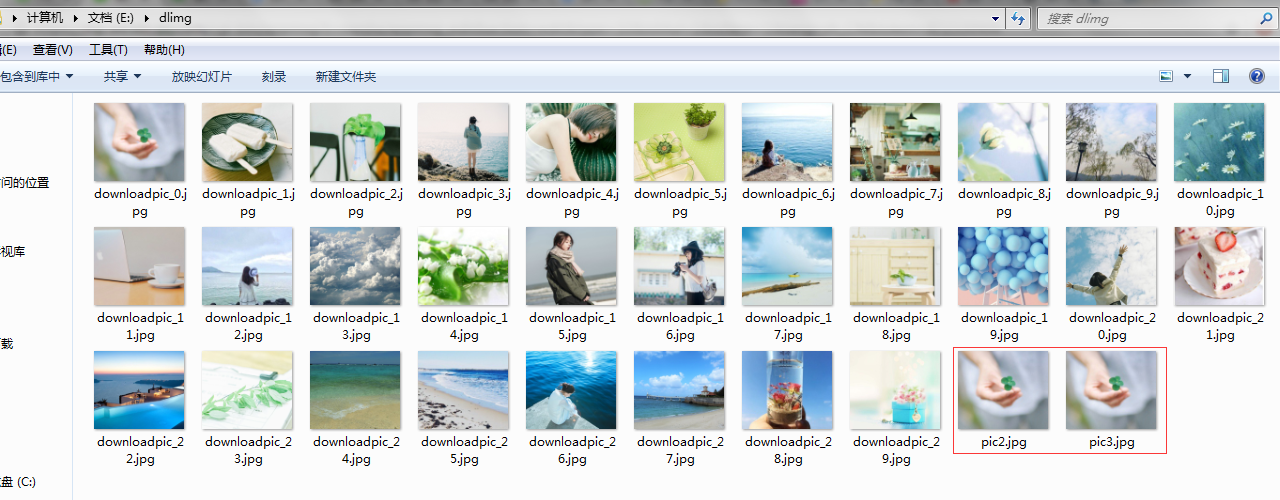
C.运行结果(红色框中pic2.jpg和pic3.jpg是A步骤运行结果,其余以downloadpic_*.jpg命名的图片是步骤B的运行结果)
文章首发于我的个人公众号:悦乐书。喜欢分享一路上听过的歌,看过的电影,读过的书,敲过的代码,深夜的沉思。期待你的关注!

Python2下载单张图片和爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- python爬取网页图片(二)
从一个网页爬取图片已经解决,现在想要把这个用户发的图片全部爬取. 首先:先找到这个用户的发帖页面: http://www.acfun.cn/u/1094623.aspx#page=1 然后从这个页面中 ...
- 利用Python爬取网页图片
最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片 ...
- Python3批量爬取网页图片
所谓爬取其实就是获取链接的内容保存到本地.所以爬之前需要先知道要爬的链接是什么. 要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_ico ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
- Python学习--两种方法爬取网页图片(requests/urllib)
实际上,简单的图片爬虫就三个步骤: 获取网页代码 使用正则表达式,寻找图片链接 下载图片链接资源到电脑 下面以博客园为例子,不同的网站可能需要更改正则表达式形式. requests版本: import ...
随机推荐
- 小米/红米导入VCF联系人乱码问题解决
PS:尽量不要用什么豌豆荚啊.微信啊.QQ啊之类的通讯录备份,那就等于把自己的通讯录免费送给腾讯他们了....还是自己手动的好一些,但是小白用户或者经常丢手机的卖就卖吧,总比联系人都丢了要好~~~ 默 ...
- IDEA搭建SSMM框架(详细过程)
IDEA搭建SSMM框架(详细过程) 相关环境 Intellij IDEA Ultimate Tomcat JDK MySql 5.6(win32/win64) Maven (可使用Intellij ...
- 团队工作准则&贡献分配规则
团队工作准则&贡献分配规则 NewTeam 2017/10/24 v1.0 工作准则及内容 全体成员 所有成员在接受任务时应结合自身情况考虑,如果认为任务内容或时间有不合理之处应当立即提出修改 ...
- 【Tesseract】Tesseract API在VS 2013中的配置以及调用
想要在VS中使用Tesseract库,必须使用经过相对应的VS版本编译过的dll以及lib.比如在VS 2013中,就必须使用在VS 2013中编译过的Tesseract库. 这里我给出经过VS 20 ...
- Vue Elementui 如何让输入框每次自动聚焦
在项目优化中碰到一个小问题,在每次提示框显示的时候让提示框中的输入框聚焦.如下图.一般情况下提示框是隐藏的.点击了编辑才会弹出. 那么原生属性autofocus 只在模板加载完成时起作用,也就是说只有 ...
- org.springframework.web.filter.DelegatingFilterProxy的作用
一.类结构 DelegatingFilterProxy类继承GenericFilterBean,间接实现了Filter,故而该类属于一个过滤器.那么就会有实现Filter中init.doFilter. ...
- 前端面试题(6)图片格式jpg,gif,png-8,png-24的区别,及其各自的使用场景
Gif格式特点: 透明性,Gif是一种布尔透明类型,既它可以是全透明,也可以是全不透明,但是它并没有半透明(alpha透明). 动画,Gif这种格式支持动画. 无损耗性,Gif是一种无损耗的图像格式, ...
- SpringMVC---@RequestMapping
配置文件 承接第一,二章 index.jsp <%@ page language="java" contentType="text/html; charset=UT ...
- 多个Fragment的分开管理方案
当项目里有多个Fragment的时候 我们希望让Fragment有个分类 并且展示的时候不会混淆在一起 例如:项目中导航栏有三个按钮 每个按钮对应一种分类的布局,每个分类的布局中有多个Fragm ...
- 一个RtspServer的设计与实现和RTSP2.0简介
一个RtspServer的设计与实现和RTSP2.0简介 前段时间着手实现了一个RTSP Server,能够正常实现多路RTSP流的直播播放,因项目需要,只做了对H.264和AAC编码的支持,但是 ...