in memory computing 存内计算是学术圈自娱自乐还是真有价值?
如果单从初衷和预想的价值来看,还是很诱人的。在冯诺依曼体系中,cpu计算和memory存储是分离的,而两者之间的data movement会造成高延迟和高耗能。
关于PIM类似的思想在50年前曾有人提出过,比如1969年WILLIAM H. KAUTZ发表的论文Cellular Logic-in-Memory Arrays和1970年在斯坦福大学工作的HAROLD S. STONE发表的论文A Logic-in-Memory Computer,不过因为当时memory scaling不大,耗能瓶颈还没有出现,人们更多的是对CPU性能的关注,所以这些想法并没有被实现。


而随着近年AI等访存密集和计算密集应用的发展,高延迟和高耗能的问题成为急需解决的问题。
Nvidia的Chief Scientist——Bill Dally在2015年的一个演讲Nvidia's Path to Exascale给了一组数据:DRAM与CPU之间的date movement耗能是单纯double precise浮点数加法耗能的1000倍。

2018年的一篇论文Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks 统计了Google常见产品(Chome/Tensorflow Mobile/video playback/video capture)的耗能情况,发现62.7%浪费在cpu和memory之间的data movement上。

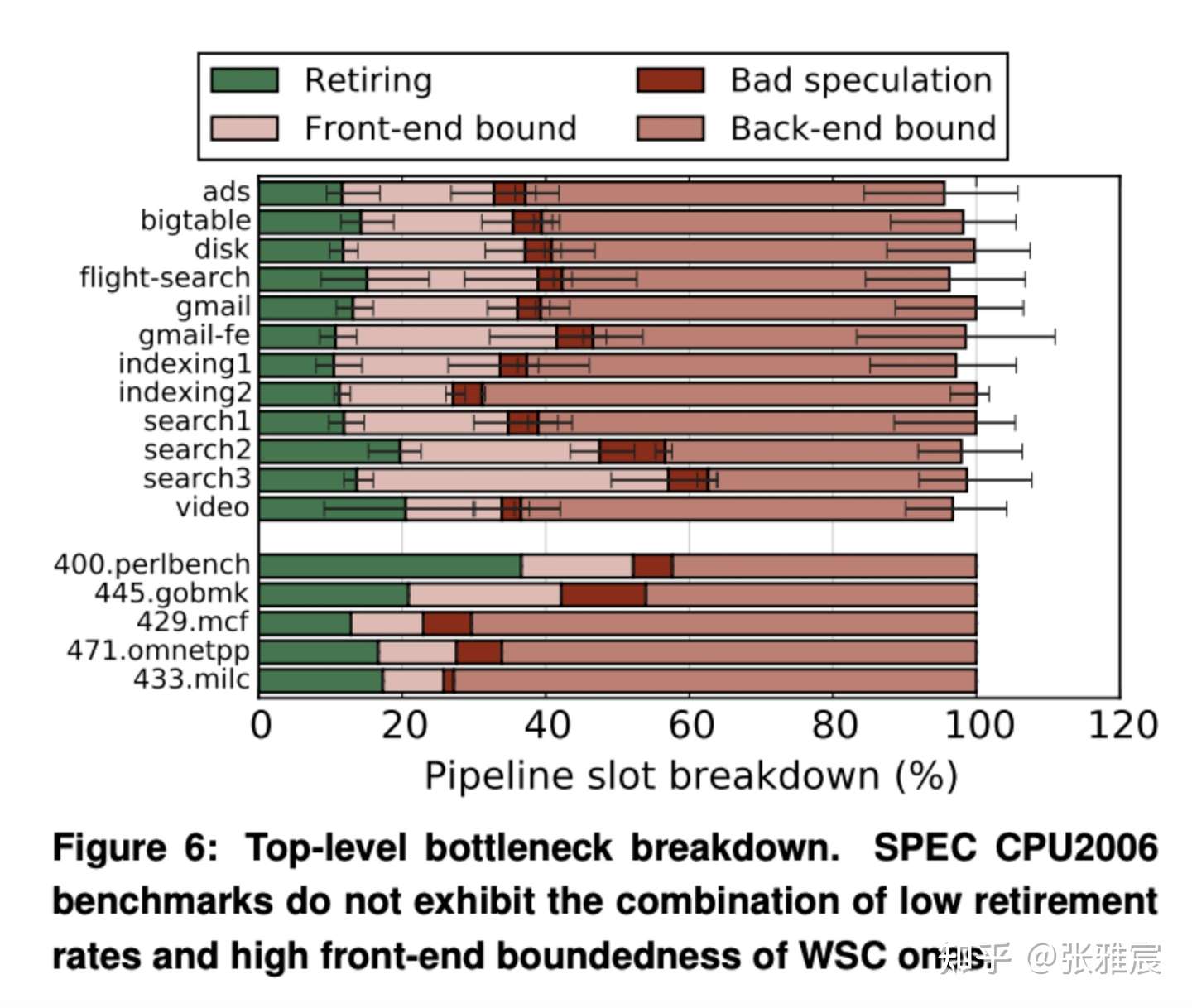
2015年Google和哈佛大学联合发表了论文Profiling a warehouse-scale computer,研究人员在Google不同数据中心的20000多台机器上做了为期三年的实验,发现只有20%左右的cycles在做【userful work】,而50% - 60%的cycles是因为Back-end bound而被浪费,在Back-end bound中,80%是【serving data cache request】

严格来说,题主说的in memory computing可以分成两类:
- process using memory : 偏向于电路革新,比如让存储器本身具有计算能力,但是这种方法目前计算精度较为有限。
- process near memory : 存储器内部集成额外的计算单元,比如3D-stacked memory、logic in memory controllers.
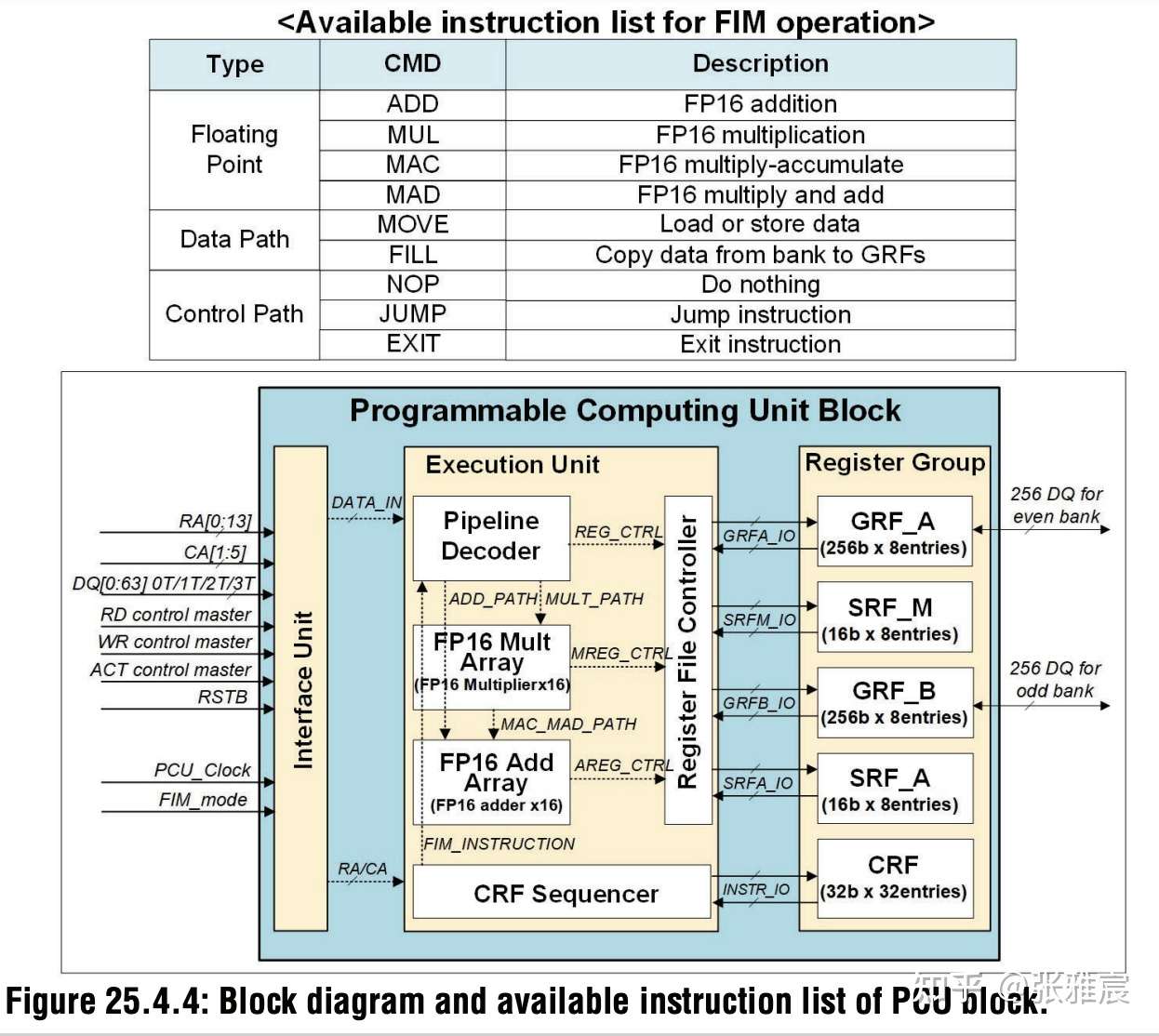
2021年Samsung发布了基于HBM-PIM的Function-in-Memory DRAM,主要针对AI场景,使用20nm DRAM工艺,并且实现了1.2TOPS的浮点数算力。可以将整体计算性能提升两倍、耗能降低70%。

Samsung在HBM-PIM中集成了额外的Programmable Computint Unit —— PCU,也就是上面说的process near memory。从下图可以看出,PCU包含了浮点数计算阵列FP16 Mult Array、流水线解码单元Pipeline Decoder、寄存器Register Group。PCU直接从邻近的DRAM中直接读取相关数据,在FP16 Mult Array中完成计算,并且根据指令进一步把结果存储到寄存器中,同时主控制器也可以根据需要把结果从寄存器读出。
另外一个比较出名的是UPMEM在2019 Hot Chips上发布的Processing-in-DRAM Engine。与Samsung的不同,这个属于process using memory,在DRAM上开发了内置于DRAM芯片本身的DPU,每个DPU可以访问64 MB的DRAM。UPMEM预计大多数应用需要几百行代码,少数人组成的团队只需2-4周就可以更新软件。


Samsung于2022年1月12号(上上周)在Nature上发布了业内首个基于 MRAM(磁性随机存储器)的存内计算芯片。这个我没细研究过,但是用MRAM来做存内计算,也算是一个巨大的飞跃。

不过还是有很多因素阻碍的PIM,比如:
- memory interleave的问题,现代memory都是按照channel去interleave,用PIM后,比如3D-stacked memory后,如何去分布数据
- 如何更方便的编程,什么操作用PIM,什么操作用CPU
- cache coherence
- 工艺的复杂程度
- ......
Onur Mutlu在ETH Zürich的Fall 2021Computer Architecture课程里也讲过之前关于PIM论文在ISCA 2016、MICRO 2016、HPCA 2017和ISCA 2017被Reject的历史,Reviewer当时给出的comment意思基本是This Will Never Get Implemented、Not practical:


Onur Mutlu对Reviewers的建议 : )

我们一般都是根据过去的经验去评价未来,没价值也没人去做了,这个价值不单单指钱 ,而且真的改变世界了呢 : )
(完)
朋友们可以关注下我的公众号,获得最及时的更新:

in memory computing 存内计算是学术圈自娱自乐还是真有价值?的更多相关文章
- 洛谷P2241-统计方形-矩形内计算长方形和正方形的数量
洛谷P2241-统计方形 题目描述: 有一个 \(n \times m\) 方格的棋盘,求其方格包含多少正方形.长方形(不包含正方形). 思路: 所有方形的个数=正方形的个数+长方形的个数.对于任意一 ...
- [Linux Memory] 用/proc/stat计算cpu的占用率
转载自:http://blog.csdn.net/pppjob/article/details/4060336 在Linux下,CPU利用率分为用户态,系统态和空闲态,分别表示CPU处于用户态执行的时 ...
- [Android Memory] Shallow Heap大小计算释疑
转载自:http://blog.csdn.net/sodino/article/details/24186907 查看Mat文档时里面是这么描述Shallow Heap的:Shallow heap i ...
- box-sizing:border-box 将元素的内边距和边框都设定在宽高内计算
http://www.w3school.com.cn/cssref/pr_box-sizing.asp box-sizing: content-box|border-box|inherit; 值 描述 ...
- 计算思维(美国CMU周以真教授)
博主注:GIScience会议是国际上最为著名的地理信息系统领域的国际会议,自2000年起,每两年举办一次,GIScience 2008会议邀请了美国卡内基-梅隆大学(CMU)计算机系华裔教授周以真博 ...
- 固态硬盘SSD与闪存(Flash Memory)
转自:http://qiaodahai.com/solid-state-drives-ssd-and-flash-memory.html 固态硬盘SSD(Solid State Drive)泛指使用N ...
- yarn资源memory与core计算配置
yarn调度分配主要是针对Memory与CPU进行管理分配,并将其组合抽象成container来管理计算使用 memory配置 计算每台机子最多可以拥有多少个container: container ...
- NANDflash和NORflash的区别(设计师在使用闪存时需要慎重选择)
NANDflash和NORflash的区别(设计师在使用闪存时需要慎重选择) NOR和NAND是现在市场上两种主要的非易失闪存技术.Intel于1988年首先开发出NOR flash技术,彻底 ...
- TensorFlow中的显存管理器——BFC Allocator
背景 作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 使用GPU训练时,一次训练任务无论是模型参数还是中间结果都需要占用大量显存.为了 ...
随机推荐
- 微服务架构 | 5.2 基于 Sentinel 的服务限流及熔断
目录 前言 1. Sentinel 基础知识 1.1 Sentinel 的特性 1.2 Sentinel 的组成 1.3 Sentinel 控制台上的 9 个功能 1.4 Sentinel 工作原理 ...
- GitHubPages的域名解析信息
github目录下CNAME修改
- python习题_读写csv格式的文件
1.读写TXT文件 # *_* coding : UTF-8 *_* # 开发人员 : zfy # 开发时间 :2019/7/7 16:26 # 文件名 : lemon_10_file.PY # 开发 ...
- rm, git rm, git rm --cached 区别与关系
HEAD, staging area, working copy在上篇<Git命令之回退篇 git revert git reset>已经讲过,不明白请自行传送过去. 1. rm 是仅仅删 ...
- requests库session保持持久会话
requests中cookie的原理 http://blog.csdn.net/zhu_free/article/details/50563756 requests - cookies的实现例 ...
- SQL 在数据库中查找拥有此列名的所有表
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE COLUMN_NAME='Column' #"Column"为要查询 ...
- 帆软报表(finereport)点击事件对话框打开
点击事件对话框打开iframe var iframe = $("<iframe id='001' name='001' width='100%' height='100%' scrol ...
- 「BUAA OO Pre」Git生成多个ssh key并连接GitLab仓库
「BUAA OO Pre」Git生成多个ssh key并连接GitLab仓库 Part 0 前言 写作背景 笔者在配置学校GitLab的ssh key时遇到一些问题,原因应为曾经配置过GitHub的s ...
- Solution -「CF 1480G」Clusterization Counting
\(\mathcal{Description}\) Link. 给定一个 \(n\) 阶完全图,边权为 \(1\sim\frac{n(n-1)}2\) 的排列.称一种将点集划分为 \(k\) ...
- 【职业规划】该如何选择职业方向?性能?自动化?测开?,学习选择python、java?看完你会感谢我的~
前言 随着近两年来互联网行业的飞速发展,互联网技术的从业人员也越来越多. 近两年来技术岗位中测试和前端工程师变成了程序员中最好招的岗位. 测试行业卷也越来越厉害了. 也正是因为如此,我们要把自己的路越 ...