RabbitMQ,RocketMQ,Kafka 消息模型对比分析
消息模型
消息队列的演进
消息队列模型
早起的消息队列是按照"队列"的数据结构来设计的。
生产者(Producer)产生消息,进行入队操作,消费者(Consumer)接收消息,就是出队操作,存在于服务端的消息容器就称为消息队列。

当然消费者也可能不止一个,存在的多个消费者是竞争的关系,消息被其中的一个消费者消费了,其它的消费者就拿不到消息了。
发布订阅模型
如果一个人消息想要同时被多个消费者消费,那么上面的队列模式就不适用了,于是又引出了一种新的模式,发布订阅模型。

在发布-订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。
发布者发送消息到主题中,然后订阅者需要先订阅主题。订阅主题的订阅者之后就可以收到发送者发送的消息了。
发布订阅也是兼容消息队列模型的,如果只有一个订阅者,就是消息队列模型了。
RabbitMQ的消息模型
RabbitMQ 使用的还是消息队列这种消息模型,不过它引入了一个 exchange 的概念。
exchange 也就是交换器,位于生产者和队列之间,生产者产生的数据是直接发送到 exchange 中,然后 exchange 根据配置的策略将消息发送到对应的队列中。

RabbitMQ 中通过绑定将交换器和队列关联起来,绑定的时候一般会指定一个绑定键(BindingKey)。
生产者发送消息的时候会指定一个 RoutingKey ,当 RoutingKey 和 BindingKey,一样的时候就会被发送的对应的队列中去。
交换器的类型
RabbitMQ 中肠常用的交换器有 fanout、direct、topic、headers 四种,这里来一一分析下
direct
direct 会根据发送消息的 RoutingKey ,然后发送到和 RoutingKey 匹配的 BindingKey 对应的队列中去。

如果发送消息的路由键也就是 RoutingKey,为 log 的时候,两个消息队列都会收到消息,如果路由键为 debug ,exchange 只会把消息发送到消息队列1中。
topic
direct 中的 RoutingKey 和 BindingKey 是完全匹配才能发送消息,topic 中在此基础之上做了扩展,也就是引入了模糊匹配机制。
RoutingKey 和 BindingKey 中使用 . ,来分割字符串,被 . 分割开的每一段字符串就是一个匹配字符;
BindingKey 中主要通过 * 和 # ,用于模糊匹配,* 表示一个单词,# 代表任意0个或多个单词;
BindingKey 中单独使用 # 时,会接收所有的消息,这与类型 fanout一致;
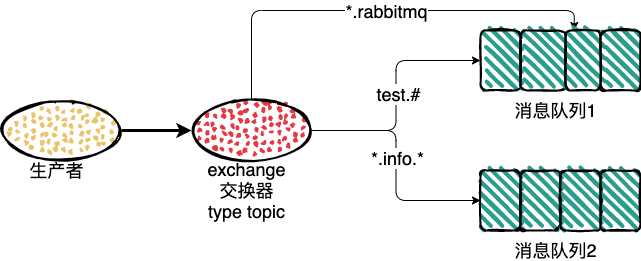
栗子:
1、路由键为 test.rabbitmq 消息队列1和消息队列2都会收到消息;
2、路由键为 rabbitmq 没有队列能收到消息;
3、路由键为 test 消息队列2会收到消息;
4、路由键为 rr.info.ww 消息队列2会收到消息;
5、路由键为 info 没有队列能收到消息;
fanout
该交换器收到的信息会被发送到所有与改交换器绑定的队列中。
headers
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers (也是一个键值对的形式) ,对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列 headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
Kafka的消息模型

Kafaka 中引入了一个 broker。broker 接收生产者的信息,为消息设置偏移量,并且保存的磁盘中。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。
同时 broker 也会对生产者和消费者进行消息的确认。
生产者发送消息到 broker,如果没有收到 broker 的确认就可以选择继续发送;
消费者同理,在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,broker 只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。
如果一个主题中,每次只有一个消费实例在处理,同时我们也要保持消息的有序性,当前消息没有被消费掉就不能接着消费下一个消息。那么,消费的性能将是极低的,这时候引入了一个分区的概念。
主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
同时引入了消费者组,消费者是消费者组中的一部分,这样会有一个或者多个消费者读一个分支,不过群组会保证一个分区只能被一个消费者消费,通过多消费者,这样消费的性能就提高了。
每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被Consumer Group1消费过,也会再给Consumer Group2消费。不过同组内是竞争关系,同组内一个消息只能被同组内的一个消息消费。
消费者通过偏移量来确认读过的数据,他是个不断累加的数据,每次成功消费一个数据这个偏移量就加一。在给定的分区中,每个消息的偏移量都是唯一的。消费者会把每个分区读取的消息偏移量保存在 Zookeeper 或 Kafka 上,如果消费者关闭或重启,它的读取状态不会丢失。
RocketMQ的消息模型

RocketMQ 中的消息模型和 Kafaka 类似,把 Kafaka 中的分区换成队列,就是 RocketMQ 的消息模型了。
不过虽然消息模型类似,但是实现方式还是有很大的差别的。
参考
【消息队列高手课】https://time.geekbang.org/column/intro/100032301
【消息队列设计精要】https://tech.meituan.com/2016/07/01/mq-design.html
【RabbitMQ实战指南】https://book.douban.com/subject/27591386/
【Kafka权威指南】https://book.douban.com/subject/27665114/
【RabbitMQ,RocketMQ,Kafka 消息模型对比分析】https://boilingfrog.github.io/2021/12/18/几种消息队列的消息模型/
RabbitMQ,RocketMQ,Kafka 消息模型对比分析的更多相关文章
- MQ选型对比ActiveMQ,RabbitMQ,RocketMQ,Kafka 消息队列框架选哪个?
最近研究消息队列,发现好几个框架,搜罗一下进行对比,说一下选型说明: 1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便.不考虑r ...
- Kafka消息模型
一.消息传递模型 传统的消息队列最少提供两种消息模型,一种P2P,一种PUB/SUB,而Kafka并没有这么做,巧妙的,它提供了一个消费者组的概念,一个消息可以被多个消费者组消费,但是只能被一个消费者 ...
- RabbitMQ之五种消息模型
首先什么是MQ MQ全称是Message Queue,即消息对列!消息队列是典型的:生产者.消费者模型.生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息.因为消息的生产和消费都是异步的,而 ...
- kafka消息分发策略分析
当我们使用kafka向指定Topic发送消息时,如果该Topic具有多个partition,无论消费者有多少,最终都会保证一个partition内的消息只会被一个Consumer group中的一个C ...
- rabbitmq五种消息模型整理
目录 0. 配置项目 1. 基本消息模型 1.1 生产者发送消息 1.2 消费者获取消息(自动ACK) 1.3 消息确认机制(ACK) 1.4 消费者获取消息(手动ACK) 1.5 自动ACK存在的问 ...
- 分布式消息队列RocketMQ&Kafka -- 消息的“顺序消费”
在说到消息中间件的时候,我们通常都会谈到一个特性:消息的顺序消费问题.这个问题看起来很简单:Producer发送消息1, 2, 3... Consumer按1, 2, 3...顺序消费. 但实际情况却 ...
- ActiveMQ、RabbitMQ、RocketMQ、Kafka四种消息中间件分析介绍
ActiveMQ.RabbitMQ.RocketMQ.Kafka四种消息中间件分析介绍 我们从四种消息中间件的介绍到基本使用,以及高可用,消息重复性,消息丢失,消息顺序性能方面进行分析介绍! 一.消息 ...
- 关于ActiveMQ、RocketMQ、RabbitMQ、Kafka一些总结和区别
这是一篇分享文 转自:http://www.cnblogs.com/williamjie/p/9481780.html 尊重原作,谢谢 消息队列 为什么写这篇文章? 博主有两位朋友分别是小A和小B: ...
- 8.关于ActiveMQ、RocketMQ、RabbitMQ、Kafka一些总结和区别
这是一篇分享文 转自:http://www.cnblogs.com/williamjie/p/9481780.html 尊重原作,谢谢 消息队列 为什么写这篇文章? 博主有两位朋友分别是小A和小B: ...
随机推荐
- [luogu4747]Intrinsic Interval
有一个结论,答案一定是所有包含其合法区间中$l$最大且$r$最小的 证明比较容易,考虑两个合法区间有交,那么交必然合法,同时交也必然包含该区间,因此这个区间一定是合法的(取$l$最大的和$r$最小的两 ...
- Ubuntu下的磁盘管理
采用fat的磁盘存储,插入后采用相同命令会出现sdb和sdb1 sdb:磁盘 sdb1:磁盘分区标号为1 命令 df:显示磁盘使用情况 du:查询某个文件的大小读 du-h 或du -h --max- ...
- Dapr-可观测性
前言: 前篇-Actor构建块文章对Dapr的Actor构建块进行了解,本篇继续对可观测性 进行了解学习. 一.可观测性 用于获取可观察性的系统信息称为遥测. 它可以分为四大类: 分布式跟踪 提供有关 ...
- Mac Maven 安装及配置
一.下载 打开 Maven 官方下载页面:https://maven.apache.org/download.cgi#,点击下载链接即可开始下载: 以 Maven 3.8.4 为例,解压后可以 ...
- 探索JavaScript执行机制
前言 不论是工作还是面试,我们可能都经常会碰到需要知道代码的执行顺序的场景,所以打算花点时间彻底搞懂JavaScript的执行机制. 如果这篇文章有帮助到你,️关注+点赞️鼓励一下作者,文章公众号首发 ...
- 『学了就忘』Linux文件系统管理 — 59、使用fdisk命令进行手工分区
目录 1.手工分区前提 (1)要有一块新的硬盘 (2)在虚拟机中添加一块新硬盘 2.手工分区 (1)查看Linux系统所有硬盘及分区 (2)手工分区:详细步骤 (3)保存手工分区 3.硬盘格式化 4. ...
- JDK 动态代理与 CGLIB 动态代理,它俩真的不一样
摘要:一文带你搞懂JDK 动态代理与 CGLIB 动态代理 本文分享自华为云社区<一文带你搞懂JDK 动态代理与 CGLIB 动态代理>,作者: Code皮皮虾 . 两者有何区别 1.Jd ...
- 洛谷 P7879 -「SWTR-07」How to AK NOI?(后缀自动机+线段树维护矩乘)
洛谷题面传送门 orz 一发出题人(话说我 AC 这道题的时候,出题人好像就坐在我的右侧呢/cy/cy) 考虑一个很 naive 的 DP,\(dp_i\) 表示 \([l,i]\) 之间的字符串是否 ...
- CSP-S 2021 游记
福兮祸之所伏 胜利是一种肯定,代表我应该在这条路上坚定不移地走下去. 胜利也是一种危机,它粉饰太平.养虎自齧,并把人最丑陋的一些想法暴露出来:虚荣心.骄傲心都在这个过程中被放大,懒惰心.自满心也找到了 ...
- tabix 操作VCF文件
tabix 可以对NGS分析中常见格式的文件建立索引,从而加快访问速度,不仅支持VCF文件,还支持BED, GFF,SAM等格式. 下载地址: 1 https://sourceforge.net/pr ...