云原生 AI 前沿:Kubeflow Training Operator 统一云上 AI 训练
分布式训练与 Kubeflow
当开发者想要讲深度学习的分布式训练搬上 Kubernetes 集群时,首先想到的往往就是 Kubeflow 社区中形形色色的 operators,如 tf-operator、mpi-operator。
这些服务于各种深度学习训练(TensorFlow、PyTorch、MXNet 等)的 operators 主要的工作包括:
- 在 Kubernetes 集群上创建 Pod 以拉起各个训练进程
- 配置用作服务发现的信息(如
TF_CONFIG)以及创建相关 Kubernetes 资源(如 Service) - 监控并更新整个任务的状态
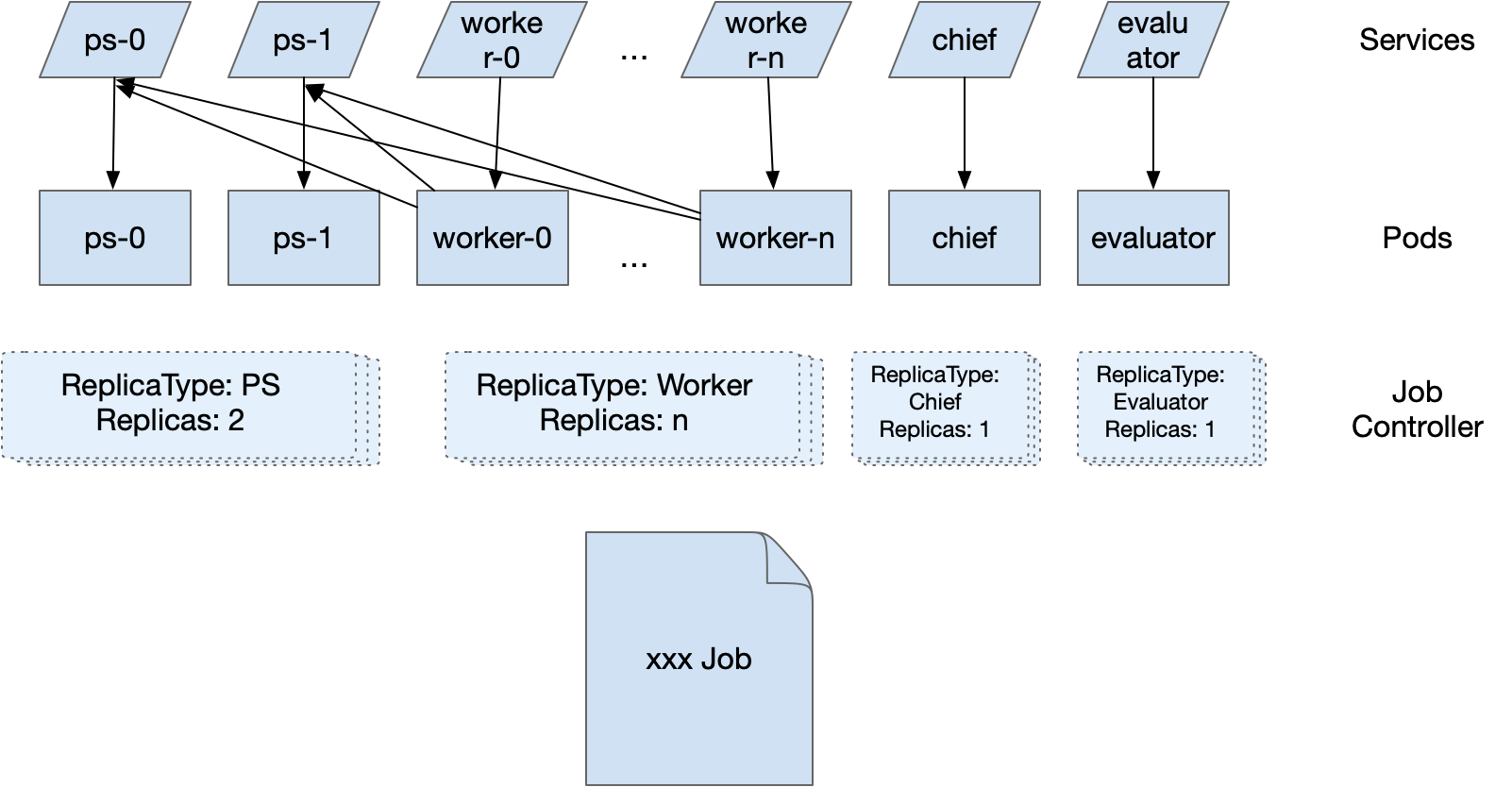
事实上,Kubeflow 的训练 Operators 已经成为在 Kubernetes 上运行分布式训练任务的实际标准。
不仅各大公有云厂商都已经基本收录或集成了 Kubeflow 的训练 operators,社区上其他与深度学习训练相关的项目(如用以自动机器学习的 Katib,又如提供自动化编排功能的 Flyte)都对接了 Kubeflow 中的 operators 作为下发创建分布式训练任务的工具。
Kubeflow Operators 的问题
在 2019 年初,Kubeflow 社区启动了 kubeflow/common 项目用以维护 operator 之间重复使用的部分代码。经过一年多的迭代和重构,在 2020 年中该项目逐渐稳定并开始接入训练 operator 。当前,tf-operator、mxnet-operator 和 xgboost-operator 即为构建在 kubeflow/common 项目之上的训练 operators。
然而,整个 Kubeflow 训练 operators 的项目维护依然存在许多挑战。
主要包括:
- 大量开发者的精力耗费在针对不同训练框架的功能增强和故障修复上
- 难以将测试和发布的基础功能与服务在不同 operators 之间复用
- 第三方组件需要对接大量不同的 operators
- 新的训练框架需要开发完整的对应的 operator 才能使用,开发成本过高
- 众多的 operators 对刚刚接触 Kubeflow 的新人开发者而言学习成本过高
以上问题都是 Kubeflow 的开发者和维护者面对的。除此之外,这些 operator 的使用者同样面临一些问题:
- 用户需要安装多个 operator 组件才能支持多种训练 APIs
- 各种 Kubeflow Jobs 的 JobSpec 看上去很类似,但是又有些许不同,并没有提供统一的使用体验
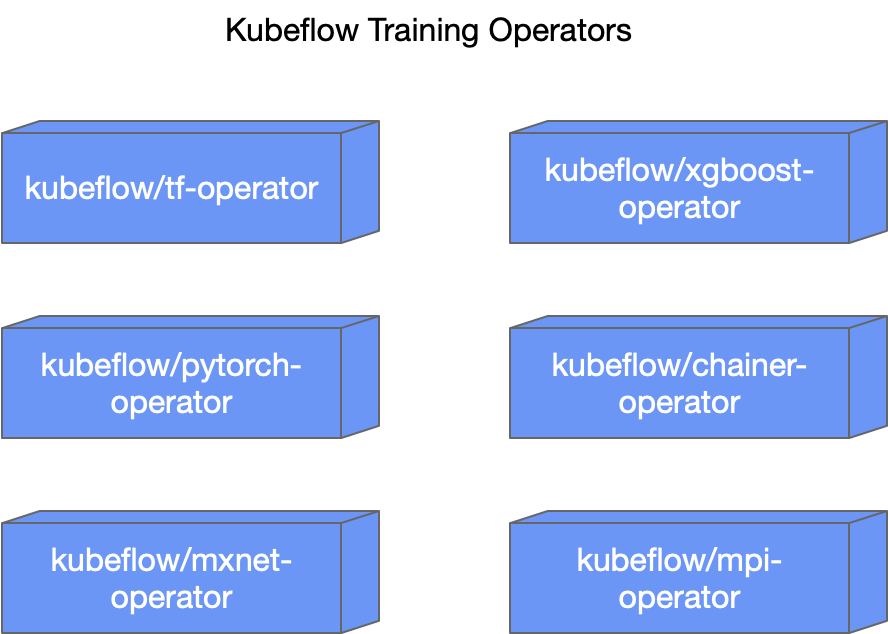
这问题的原因主要在于每个深度学习框架都对应一个的 operator 独立在一个 repository 中进行维护。这种分开维护的模式使得诸如构建环境、测试环境、部署方式以及代码逻辑都无法做到很好的整合。
尽管深度学习框架的数量处在收敛的过程中,但依然会有源源不断的新框架希望通过 Kubeflow 可以快速接入 Kubernetes 进行分布式训练,而这些新的增量使得问题变得更为严重。
Proposal:All-in-One
针对上面提到的各项问题,经过社区会议的多次讨论,决定尝试通过融合的方式将多个 Kubeflow 的训练 operator 代码汇聚到一个仓库。
同时,参照 controller-runtime 中推荐的 One-Manager-Multi-Controller 的模式,让多个处理不同 API 的 controller 可以共享一个 Manager 及其 cache,在简化代码的同时也减少了在多个 operator 同时部署时冗余的 APIServer 请求:
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{...})
...
for _, s := range enabledSchemes {
setupFunc, supported := controller_v1.SupportedSchemeReconciler[s]
if !supported {os.Exit(1)}
if err = setupFunc(mgr, enableGangScheduling); err != nil {
setupLog.Error(err, "unable to create controller", "controller", s)
os.Exit(1)
}
}
所有的 Controller(Reconciler)都需要向 SupportedSchemeReconciler 提前完成注册:
var SupportedSchemeReconciler = map[string]ReconcilerSetupFunc{
tensorflowv1.Kind: func(mgr manager.Manager, enableGangScheduling bool) error {
return tensorflowcontroller.NewReconciler(mgr, enableGangScheduling).SetupWithManager(mgr)
},
pytorchv1.Kind: func(mgr manager.Manager, enableGangScheduling bool) error {
return pytorchcontroller.NewReconciler(mgr, enableGangScheduling).SetupWithManager(mgr)
},
...,
}
用户可以在启动 operator 进程时通过 --enable-scheme 来指定需要开启支持的 API。后续有新的 Controller 接入,按照这种“先注册后启动”的方式来选择性地开启对应的 controllers。
进展与近期规划
当前融合已经正式并入 tf-operator 的 master 分支。用户很快可以在即将发布的 Kubeflow 1.4 Release 中体验到融合后的 tf-operator:部署单个 operator 即可支持包括 TFJob、PyTorchJob、MXNetJob 和 XGBoostJob 在内的四种 API 支持。
在代码仓库层面的融合是 Kubeflow Training Operator 迈向下一个阶段的第一步。这一步更多地解决了在项目运营层面,包括环境复用、整体代码管理上的一致性。而针对开发者的低代码开发,包括新功能增强、bug 修复和新 API 接入,将是我们规划的下一步目标。
根据这样的设计,开发者只需要修改非常有限的几个函数即可接入新的 API。
主要包括:
// 根据 ctrl.Request 获取对应的自定义 Job
GetJob(ctx context.Context, req ctrl.Request) (client.Object, error)
// 从自定义 Job 中以 map[commonv1.ReplicaType]*commonv1.ReplicaSpec 的格式抽取 ReplicasSpecs
ExtractReplicasSpec(job client.Object) (map[commonv1.ReplicaType]*commonv1.ReplicaSpec, error)
// 从自定义 Job 中抽取 RunPolicy
ExtractRunPolicy(job client.Object) (*commonv1.RunPolicy, error)
// 从自定义 Job 中抽取 JobStatus
ExtractJobStatus(job client.Object) (*commonv1.JobStatus, error)
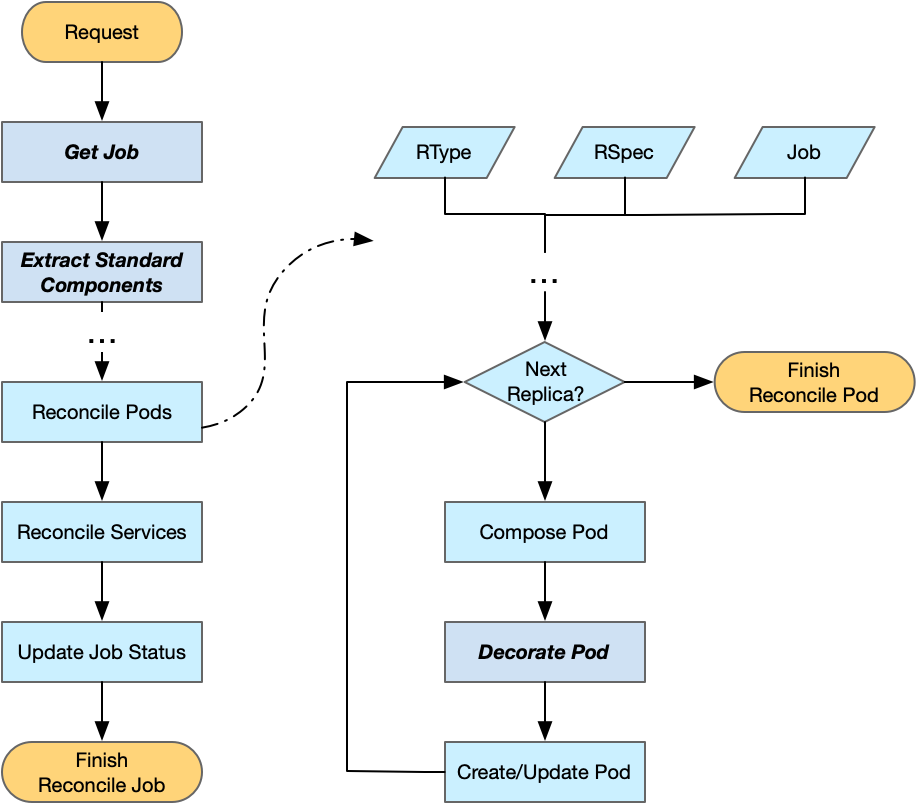
开发者如果需要注入一些用以服务发现的环境变量,可以覆盖方法 DecoratePod(rtype commonv1.ReplicaType, podTemplate *corev1.PodTemplateSpec, job client.Object) 在 client 向 APIServer 提交创建请求前修改 Pod。
以上低代码开发方式的基础已经以 pkg/reconciler.v1 的形态合入 kubeflow/common 仓库。很快,我们也将在 tf-operator 上引入基于该 reconciler.v1 包的基础 API,希望可以在验证 reconciler.v1 的同时为更多通用的实用案例提供一种更为简便接入 Kubernetes 的方式。
如果开发者希望以更低层 API 的方式对 controller 进行开发,pkg/controller.v1 包可以满足这一类开发者的需求。
远景展望
尽管针对 Kubeflow Training Operator 的优化改造还在进行中,我们并没有止步于此。对于 Training Operator 的未来的发展,我们认为存在以下几个领域值得持续投入:
- 首先是进一步提高 Kubeflow Training Operator 适配定制化需求 Job 时的灵活性。我们计划提出与深度学习训练框架解耦的一种 Job API 以支持更广泛的任务定义,并允许用户可以借助 kubeflow/common 中的 controller.v1 和 reconciler.v1 进行定制化开发,但其学习成本和开发成本依然过高。甚至在将来,初级开发者可以不修改 operator 而仅仅添加/修改一些 webhook 或是 decorator server 来实现定制化修改。
- 第二个方面是进一步增强 Kubeflow Training Operator 和其他第三方组件交互时的便利性。我们希望未来利用 Kubeflow Training Operator 来构建 AI 平台的开发者可以方便地将其与其他模块对接,实现诸如任务队列、流水线、超参数搜索等功能。
- 最后也是最关键的,我们依然希望可以进一步提升 Kubeflow Training Operator 的稳定性。
我们欢迎更多的同学能够尝试、体验 Kubeflow 并且投入到 Kubeflow 项目中来。
参考资料
[1]add reconciler.v1: 【https://github.com/kubeflow/common/pull/141】
[2]
reconciler.v1 implementation: 【https://github.com/kubeflow/common/tree/master/pkg/reconciler.v1/common】
[3] All-in-one Kubeflow Training Operator: 【https://docs.google.com/document/d/1x1JPDQfDMIbnoQRftDH1IzGU0qvHGSU4W6Jl4rJLPhI/edit】
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

云原生 AI 前沿:Kubeflow Training Operator 统一云上 AI 训练的更多相关文章
- CNCF 旗下首个为中国开发者量身打造的云原生课程,《CNCF x Alibaba 云原生技术公开课》即将上线
伴随着以 Kubernetes 为代表的云原生技术体系的日益成熟以及 CNCF 生态的逐渐壮大,“云原生”已然成为了未来云计算时代里一个当仁不让的关键词.但是,到底什么是“云原生”?云原生与 CNCF ...
- 探索云网络技术前沿,Sigcomm 2019 阿里云参会分享
Sigcomm 2019简介 一年一度的网络顶级学术峰会Sigcomm于8月20日至22日在北京举行.作为ACM Special Interest Group on Data Communicatio ...
- 金融云原生漫谈(三)|银行云原生基础设施构建:裸金属VS虚拟机
在金融行业数字化转型的驱动下,国有银行.股份制银行和各级商业银行也纷纷步入容器化的进程. 如果以容器云上生产为目标,那么整个容器云平台的设计.建设和优化对于银行来说是一个巨大的挑战.如何更好地利用 ...
- 云原生生态周报 Vol. 8 | Gartner 发布云原生趋势
业界要闻 Gartner 发布云原生基础设施未来的八大趋势:权威分析机构 Gartner 在对 2020 年技术趋势的展望当中指出:“预计2020年所有领先的容器管理软件均内置服务融合技术,到2022 ...
- 最佳案例 | 游戏知几 AI 助手的云原生容器化之路
作者 张路,运营开发专家工程师,现负责游戏知几 AI 助手后台架构设计和优化工作. 游戏知几 随着业务不断的拓展,游戏知几AI智能问答机器人业务已经覆盖了自研游戏.二方.海外的多款游戏.游戏知几研发团 ...
- AI云原生浅谈:好未来AI中台实践
AI时代的到来,给企业的底层IT资源的丰富与敏捷提出了更大的挑战,利用阿里云稳定.弹性的GPU云服务器,领先的GPU容器化共享和隔离技术,以及K8S集群管理平台,好未来通过云原生架构实现了对资源的灵活 ...
- 云原生的弹性 AI 训练系列之二:PyTorch 1.9.0 弹性分布式训练的设计与实现
背景 机器学习工作负载与传统的工作负载相比,一个比较显著的特点是对 GPU 的需求旺盛.在之前的文章中介绍过(https://mp.weixin.qq.com/s/Nasm-cXLtJObjLwLQH ...
- 成本降低40%、资源利用率提高20%的 AI 应用产品云原生容器化之路
作者 郭云龙,腾讯云高级工程师,目前就职于 CSIG 云产品三部-AI 应用产品中心,现负责中心后台业务框架开发. 导语 为了满足 AI 能力在公有云 SaaS 场景下,服务和模型需要快速迭代交付的需 ...
- 直击KubeCon 2018 |云原生正在改变你的衣食住行
云计算从不被看好到成长为势不可挡的技术潮流,仅仅用了十年的时间.如今“云原生”又被企业以及开发者奉为圭臬,并被认为是云计算的未来. 阿里云容器技术负责人易立认为云计算有三个阶段:云搬迁.云就绪和云原生 ...
随机推荐
- HSDB工具类使用探索jvm
本文是引用https://club.perfma.com/article/2261053 有人问了个小问题,说: public class Test { static Test2 t1 = new T ...
- Django debug page XSS漏洞(CVE-2017-12794)
影响版本:1.11.5之前的版本 访问http://your-ip:8000/create_user/?username=<script>alert(1)</script>创建 ...
- Java进阶 | 从整体上观察面向对象
一.面向对象 面向对象是Java编程中最核心的思想,基本特征:继承.封装.多态. 1.特征之封装 将结构.数据.操作封装在对象实体中,使用时可以不关注对象内部结构,只能访问开放权限的功能入口,从而降低 ...
- vue 快速入门 系列 —— vue-cli 上
其他章节请看: vue 快速入门 系列 Vue CLI 4.x 上 在 vue loader 一文中我们已经学会从零搭建一个简单的,用于单文件组件开发的脚手架:本篇,我们将全面学习 vue-cli 这 ...
- C++ //运算符重载 +号
1 #include <iostream> 2 #include <string> 3 using namespace std; 4 5 //1.成员函数重载 +号 6 cla ...
- 被字节跳动、小米、美团面试官问的AndroidFramework难倒了? 这里有23道面试真题,助力成为offer收割机!
目录 1.Android中多进程通信的方式有哪些?a.进程通信你用过哪些?原理是什么?(字节跳动.小米)2.描述下Binder机制原理?(东方头条)3.Binder线程池的工作过程是什么样?(东方头条 ...
- MapReduce框架原理-OutputFormat工作原理
OutputFormat概述 OutputFormat主要是用来指定MR程序的最终的输出数据格式 . 默认使用的是TextOutputFormat,默认是将数据一行写一条数据,并且把数据放到指定的输出 ...
- Android消息机制1-Handler(Java层)
一.概述 在整个Android的源码世界里,有两大利剑,其一是Binder IPC机制,,另一个便是消息机制(由Handler/Looper/MessageQueue等构成的). Android有大量 ...
- JVM-初见
目录 JVM的体系结构 类加载器 双亲委派机制 Native PC程序计数器 方法区(Method Area) 栈 堆 调优工具 常见JVM调优参数 常见垃圾回收算法 引用计数算法 复制算法 标记-清 ...
- 黑马JVM教程——自学笔记(三)
四.类加载与字节码技术 4.1.类文件结构 首先获得.class字节码文件 方法: 在文本文档里写入java代码(文件名与类名一致),将文件类型改为.java java终端中,执行javac X:.. ...