用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话
大家好,我是辰哥~
今天辰哥带大家分析一波当前热门手游《王者荣耀》英雄皮肤,比如皮肤上线时间、皮肤类型(勇者;史诗;传说等)、价格。
1.获取数据
数据来源于《王者荣耀官方网站》,网页数据如下:

所需内容:
英雄名称
英雄皮肤名称
上线时间
皮肤类型(勇者;史诗;传说等)
价格(这个在官方没有获取到,是辰哥这边手动统计的)
首先通过查看network分析获取所有皮肤的数据(通过分析发现是异步加载的)
查看响应数据

url = "https://pvp.qq.com/zlkdatasys/data_zlk_xpflby.json"
response = requests.get(url).json()
for i in response['pcblzlby_c6']:
print(i['pcblzlbybt_d3'],i['lbyrq_e5'],i['pcblzlbyxqydz_c4'])
这里只获取到英雄皮肤名称、上线时间以及皮肤详细信息链接(包含皮肤类型、对应英雄)

这里只获取到了189款皮肤(9*21=189),接着在继续通过异步请求获得的皮肤详细信息链接,去获取皮肤的具体信息。
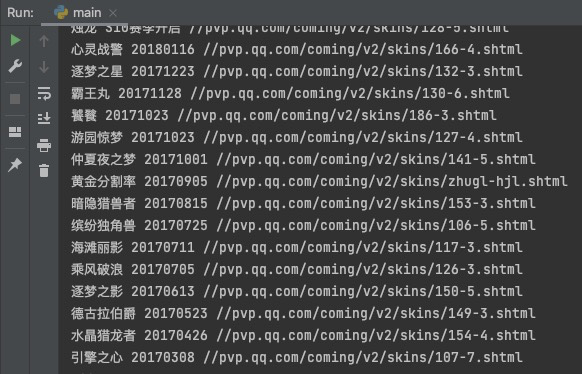
以其中一个皮肤为例

可以获取到皮肤类型(传说);皮肤名称(仲夏夜之梦);对应英雄(貂蝉);

通过查看源代码可以发现所需内容对应的网页标签,其中皮肤类型是图片的形式展示,但是我们需要的是文字内容,但是也不并非无规律可寻
皮肤类型规律:
勇者:1.png
限定:5.png
史诗:12.png
传说:15.png
KPL限定:19.png
情人节限定:24.png
荣耀典藏:26.png
FMVP:38.png
战令限定:40.png
其他:剩下的就归类到其他类(赛季限定等等)
上面的规律是皮肤类型图片对应的文字内容。
url = "https:"+"//pvp.qq.com/coming/v2/skins/141-5.shtml"
response = requests.get(url)
response.encoding = 'gbk'
text = response.text
selector = etree.HTML(text)
img = selector.xpath('//*[@id="showSkin"]/div/img/@src')[0]
print(frompic_gettext(img))
skin = selector.xpath('//*[@id="showSkin"]/div/div[2]/span[1]/text()')[0]
print(skin)
hero = selector.xpath('//*[@id="showSkin"]/div/div[2]/span[2]/text()')[0]
print(hero)
text = selector.xpath('//*[@id="showSkin"]/div/p/text()')[0]
print(text)

最终获取全部(189)的皮肤信息
url = "https://pvp.qq.com/zlkdatasys/data_zlk_xpflby.json"
response = requests.get(url).json()
for i in response['pcblzlby_c6']:
types,skin,hero,text = getdetail(str(i['pcblzlbyxqydz_c4']))
print(hero,skin,i['lbyrq_e5'],types,text)
输出结果:
最后将数据保存到excel,并手动统计皮肤对应的价格
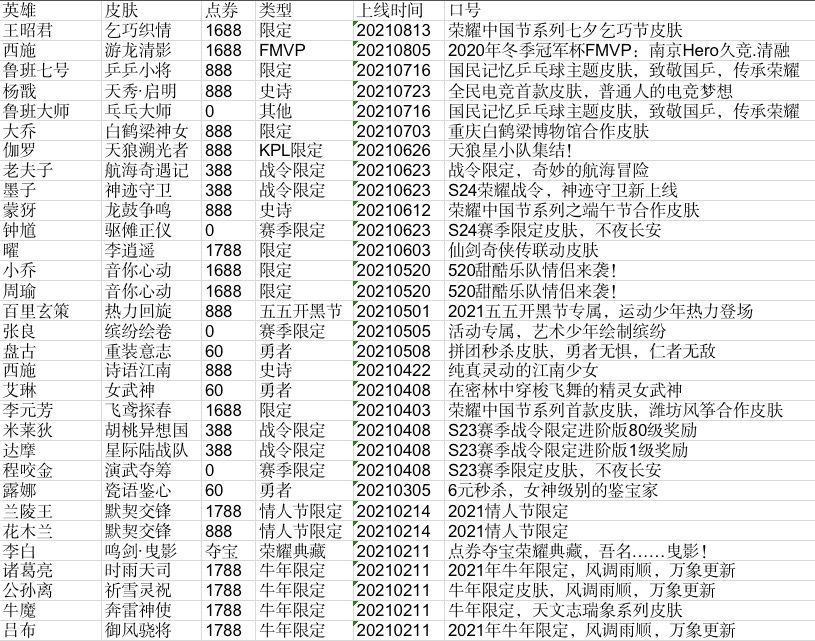
在点券这列:
1.有具体点券信息的就直接统计(不包含首周优惠)
2.赛季专属的用0表示(免费获得)
3.战令限定的默认388(购买战令进阶)
4.其他一些抽奖,夺宝的直接用对应文字统计。
在皮肤类型这里也清洗了一下(比如五五开黑节,牛年限定等等)
2.可视化
先来给口号字段做一下词云图
这里直接使用辰哥的可视化平台进行制作
(show.chenlove.cn)
以下的可视化图表都直接在上面的平台一键生成

上传前面的excel文件,
选择口号字段和词云图背景;
点击生成词云图
点击导出,下载到本地

同样一键给皮肤字段做一下词云图

上线时间分析

统计每年发布的皮肤数量
df = pd.read_excel("王者荣耀英雄皮肤.xlsx")
time = df["上线时间"].tolist()
clear_time = [str(i)[0:4] for i in time]
result = Counter(clear_time)
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
t = [i[0] for i in d]
v = [i[1] for i in d]
"""
['2020', '2019', '2021', '2018', '2017']
[47, 44, 43, 42, 14]
"""
同样的还是使用辰哥的可视化平台(选择饼图)
对结果进行可视化
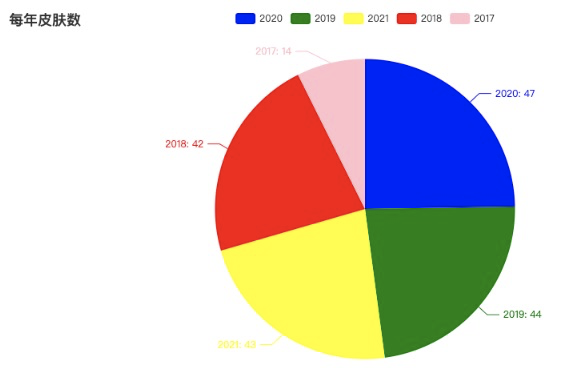
可以看出从2017~2021上线皮肤数量逐年增加,由于2021年刚过一半,所以还未超过2020年的数量。
分析每年几月皮肤数量最多

统计2017~2021年皮肤数量最多的月份
for j in [str(i)[0:6] for i in time]:
if "2017" in str(j):
t_2017.append(j[4:6])
if "2018" in str(j):
t_2018.append(j[4:6])
if "2019" in str(j):
t_2019.append(j[4:6])
if "2020" in str(j):
t_2020.append(j[4:6])
if "2021" in str(j):
t_2021.append(j[4:6])
# 排序
d_2017 = sorted(Counter(t_2017).items(), key=lambda x: x[1], reverse=True)
d_2018 = sorted(Counter(t_2018).items(), key=lambda x: x[1], reverse=True)
d_2019 = sorted(Counter(t_2019).items(), key=lambda x: x[1], reverse=True)
d_2020 = sorted(Counter(t_2020).items(), key=lambda x: x[1], reverse=True)
d_2021 = sorted(Counter(t_2021).items(), key=lambda x: x[1], reverse=True)
print("2017",d_2017[0])
print("2018",d_2018[0])
print("2019",d_2019[0])
print("2020",d_2020[0])
print("2021",d_2021[0])
"""
2017 ('10', 3)
2018 ('10', 6)
2019 ('02', 10)
2020 ('01', 14)
2021 ('02', 10)
"""
可以看到在2017和2018年10月上线皮肤较多,从19年开始,过年时当月上线的皮肤数量比同年其他月份数量多。
不同点券价格
统计excel中点券一列中包含几种价格,并进行排序
price = df["点券"].tolist()
clear_price = [str(i) for i in price]
result = Counter(clear_price)
# 排序
d = sorted(result.items(), key=lambda x: x[1], reverse=True)
t = [i[0] for i in d]
v = [i[1] for i in d]
"""
['888', '1788', '0', '388', '1688', '60', '夺宝', '488', '抽奖', '贵族限定', '660']
[52, 30, 28, 21, 19, 17, 13, 6, 2, 1, 1]
"""
将结果导入可视化平台,生成可视化图
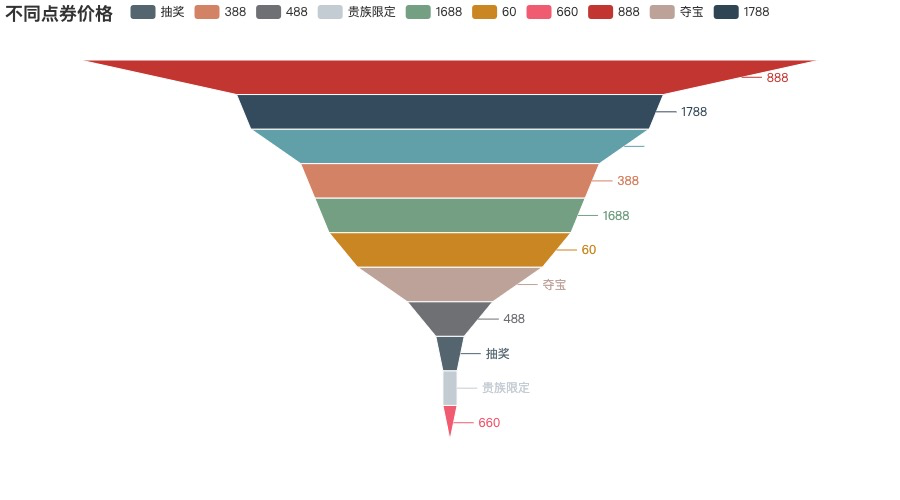
其中第三个是0,因为赛季皮肤可以免费获取(所需点券为0),以上就是《王者荣耀》获得皮肤的几种价格,像夺宝抽奖这种靠运气,无法去衡量点券,所以就直接展示中文意思。
几种不同皮肤类型

统计excel中类型字段,并排序
"""
['史诗', '勇者', '限定', '战令限定', '其他', '赛季限定', 'KPL限定',
'FMVP', '荣耀典藏', '情人节限定', '鼠年限定', '猪年限定', '牛年限定',
'五五开黑节', '传说', '狗年限定', '五周年限定', '四周年限定', '三周年限定', '战队赛专属', '二周年限定']
[27, 27, 26, 21, 20, 18, 9, 6, 6, 5, 5, 5, 4, 2, 2, 2, 1, 1, 1, 1, 1]
"""0
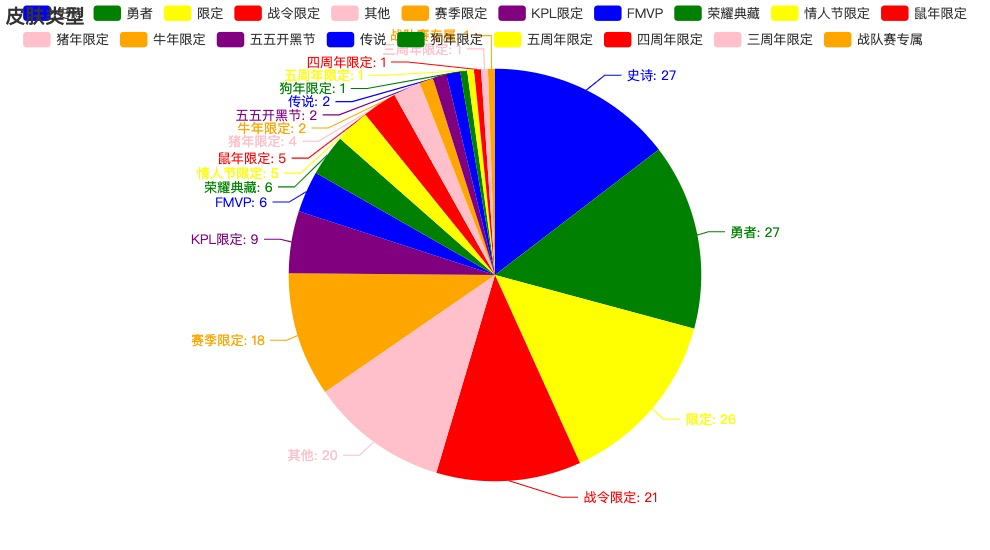
当前统计到是20种类型,但远不止20,因为对于“其他”标签的还包含多种,因此皮肤类型起码20+,估计20多种。此外还可以看出史诗和勇者这两个类型的皮肤是较多的。
同一种点券对应不同皮肤类型

同一种点券价格对应多种皮肤类型
比如888点券对应【'限定', '史诗', 'KPL限定', '五五开黑节', '情人节限定'等】
分别统计点券为888;1788;1688;0(免费)对应哪些皮肤类型,并绘制关系图(同样也是使用可视化平台进行绘制)
for i in range(0,len(price)):
if str(price[i])=="888":
if tp[i] not in c_888:
c_888.append(tp[i])
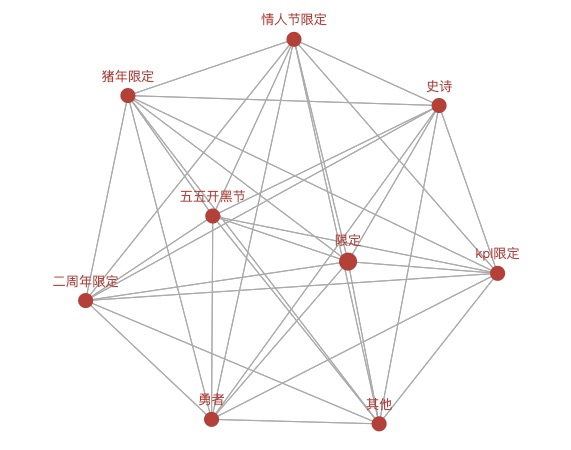
if str(price[i])=="1788":
if tp[i] not in c_1788:
c_1788.append(tp[i])
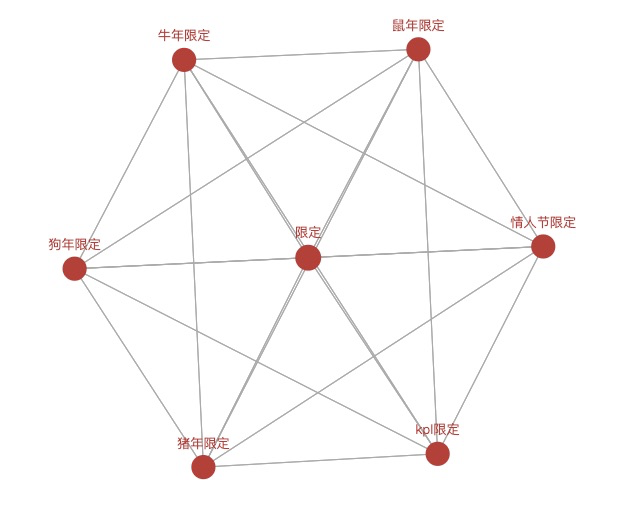
if str(price[i])=="0":
if tp[i] not in c_0:
c_0.append(tp[i])
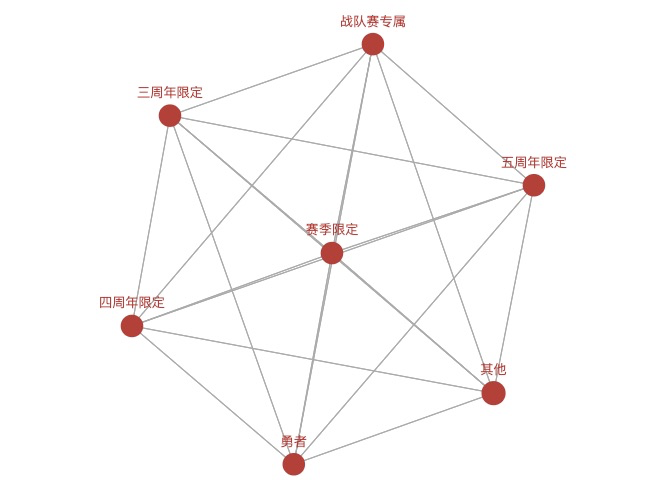
if str(price[i])=="1688":
if tp[i] not in c_1688:
c_1688.append(tp[i])
"""
888 ['限定', '史诗', 'KPL限定', '五五开黑节', '情人节限定', '勇者', '猪年限定', '其他', '二周年限定']
1788 ['限定', '情人节限定', '牛年限定', 'KPL限定', '鼠年限定', '猪年限定', '狗年限定']
0 ['其他', '赛季限定', '五周年限定', '四周年限定', '勇者', '三周年限定', '战队赛专属']
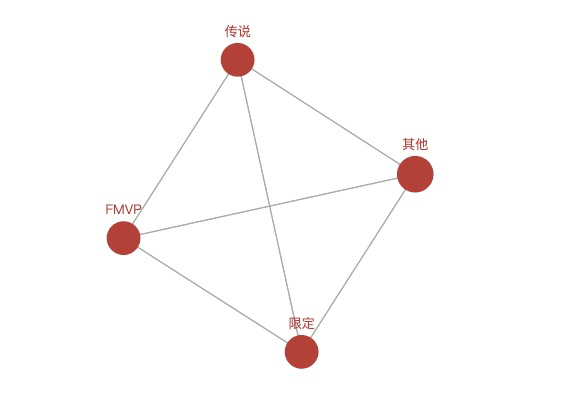
1688 ['限定', 'FMVP', '传说', '其他']
"""
888点券对应皮肤类型
1788点券对应皮肤类型
0点券对应皮肤类型
1688点券对应皮肤类型
今天的文章就到这里了
上面所涉及的可视化都是通过辰哥的可视化平台进行制作。感兴趣的小伙伴可以去看看(show.chenlove.cn)
最后
1. 本文详细介绍了python爬虫获取《王者荣耀》英雄皮肤信息并且可视化
2. 本文仅供读者学习使用,不做其他用途!
用Python爬取《王者荣耀》英雄皮肤数据并可视化分析,用图说话的更多相关文章
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤 在爬取所有之前,先完成一张皮肤的爬取 打开anacond调出编译器Jupyter Notebook 打开王者荣耀官网 下拉找到位于网页右边的英雄/皮肤 点击[+更多] 进入 ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用Python爬取"王者农药"英雄皮肤
0.引言 作为一款现象级游戏,王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了.本篇就来教大家如何使用Python来爬取这些精美的英雄皮肤. 1.环 ...
- 用Python爬取"王者农药"英雄皮肤 原
padding: 10px; border-bottom: 1px solid #d3d3d3; background-color: #2e8b57; } .second-menu-item { pa ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
随机推荐
- 37.qt quick- 高仿微信实现局域网聊天V3版本(添加登录界面、UDP校验登录、皮肤更换、3D旋转)
1.版本介绍(已上传至群里) 版本说明: 添加登录界面. UDP校验登录. 皮肤更换. 3D旋转(主界面和登录界面之间切换) . 效果图如下所示: 如果效果图加载失败,可以去哔哩哔哩 https:// ...
- Docker:Docker的Run命令使用时报错
命令报错:WARNING: Your kernel does not support swap limit capabilities, memory limited without swap. 这是因 ...
- hdu 1145(Sticks) DFS剪枝
Sticks Problem Description George took sticks of the same length and cut them randomly until all par ...
- 使用Octotree插件在Edge上以树形结构浏览GitHub上的源码
先预览效果左侧的目录通过点击,就可以到达对应的源码位置. 首先点击打开Edge中的浏览器扩展在右上角...=>点击扩展=>点击获取Microsoft Edge扩展按钮=>在左侧搜索所 ...
- 使用.net Core 3.1 多线程读取数据库
第一步:先创建一个DBhepler类,作为连接数据库中心,这个不过多说明,单纯作为数据库的连接........... 1 public static string Constr = "数据库 ...
- 国产深度学习框架mindspore-1.3.0 gpu版本无法进行源码编译
官网地址: https://www.mindspore.cn/install 所有依赖环境 进行sudo make install 安装,最终报错: 错误记录信息: cat /tmp/mind ...
- 基于 apache-arrow 的 duckdb rust 客户端
背景 duckdb 是一个 C++ 编写的单机版嵌入式分析型数据库.它刚开源的时候是对标 SQLite 的列存数据库,并提供与 SQLite 一样的易用性,编译成一个头文件和一个 cpp 文件就可以在 ...
- FiddlerEverywhere 的配置和基本应用
一.下载大家自行在官网下载即可,这个可以当做是fiddler的升级版本,里面加了postman的功能,个人感觉界面比较清晰简约,比较喜欢. 二.下载完成之后大家可以自行注册登录,主页面的基本使用如下: ...
- [HNOI2008]GT考试 题解
这题比较难搞.考虑设计状态:\(f_{i,j}\) 表示当前考虑到 \(X_i\) 位,且 \(X\) 的后 \(j\) 位刚好与 \(A\) 列匹配时的方案数.最终答案为 \(\sum_{i=0}^ ...
- synchronized锁定类方法、volatile关键字及其他(八)
同步静态方法 synchronized还可以应用在静态方法上,如果这么写,则代表的是对当前.java文件对应的Class类加锁.看一下例子,注意一下printC()并不是一个静态方法: public ...