Variational Auto-encoder(VAE)变分自编码器-Pytorch
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.utils import save_image # 配置GPU或CPU设置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 创建目录
# Create a directory if not exists
sample_dir = 'samples'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir) # 超参数设置
# Hyper-parameters
image_size = 784
h_dim = 400
z_dim = 20
num_epochs = 15
batch_size = 128
learning_rate = 1e-3 # 获取数据集
# MNIST dataset
dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True) # 数据加载,按照batch_size大小加载,并随机打乱
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True) # 定义VAE类
# VAE model
class VAE(nn.Module):
def __init__(self, image_size=784, h_dim=400, z_dim=20):
super(VAE, self).__init__()
self.fc1 = nn.Linear(image_size, h_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(h_dim, z_dim)
self.fc4 = nn.Linear(z_dim, h_dim)
self.fc5 = nn.Linear(h_dim, image_size) # 编码 学习高斯分布均值与方差
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h), self.fc3(h) # 将高斯分布均值与方差参数重表示,生成隐变量z 若x~N(mu, var*var)分布,则(x-mu)/var=z~N(0, 1)分布
def reparameterize(self, mu, log_var):
std = torch.exp(log_var / 2)
eps = torch.randn_like(std)
return mu + eps * std
# 解码隐变量z
def decode(self, z):
h = F.relu(self.fc4(z))
return F.sigmoid(self.fc5(h)) # 计算重构值和隐变量z的分布参数
def forward(self, x):
mu, log_var = self.encode(x)# 从原始样本x中学习隐变量z的分布,即学习服从高斯分布均值与方差
z = self.reparameterize(mu, log_var)# 将高斯分布均值与方差参数重表示,生成隐变量z
x_reconst = self.decode(z)# 解码隐变量z,生成重构x’
return x_reconst, mu, log_var# 返回重构值和隐变量的分布参数 # 构造VAE实例对象
model = VAE().to(device)
print(model)
# VAE( (fc1): Linear(in_features=784, out_features=400, bias=True)
# (fc2): Linear(in_features=400, out_features=20, bias=True)
# (fc3): Linear(in_features=400, out_features=20, bias=True)
# (fc4): Linear(in_features=20, out_features=400, bias=True)
# (fc5): Linear(in_features=400, out_features=784, bias=True)) # 选择优化器,并传入VAE模型参数和学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#开始训练
for epoch in range(num_epochs):
for i, (x, _) in enumerate(data_loader):
# 前向传播
x = x.to(device).view(-1, image_size)# 将batch_size*1*28*28 ---->batch_size*image_size 其中,image_size=1*28*28=784
x_reconst, mu, log_var = model(x)# 将batch_size*748的x输入模型进行前向传播计算,重构值和服从高斯分布的隐变量z的分布参数(均值和方差) # 计算重构损失和KL散度
# Compute reconstruction loss and kl divergence
# For KL divergence, see Appendix B in VAE paper or http://yunjey47.tistory.com/43
# 重构损失
reconst_loss = F.binary_cross_entropy(x_reconst, x, size_average=False)
# KL散度
kl_div = - 0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # 反向传播与优化
# 计算误差(重构误差和KL散度值)
loss = reconst_loss + kl_div
# 清空上一步的残余更新参数值
optimizer.zero_grad()
# 误差反向传播, 计算参数更新值
loss.backward()
# 将参数更新值施加到VAE model的parameters上
optimizer.step()
# 每迭代一定步骤,打印结果值
if (i + 1) % 10 == 0:
print ("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Div: {:.4f}"
.format(epoch + 1, num_epochs, i + 1, len(data_loader), reconst_loss.item(), kl_div.item())) with torch.no_grad():
# Save the sampled images
# 保存采样值
# 生成随机数 z
z = torch.randn(batch_size, z_dim).to(device)# z的大小为batch_size * z_dim = 128*20
# 对随机数 z 进行解码decode输出
out = model.decode(z).view(-1, 1, 28, 28)
# 保存结果值
save_image(out, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch + 1))) # Save the reconstructed images
# 保存重构值
# 将batch_size*748的x输入模型进行前向传播计算,获取重构值out
out, _, _ = model(x)
# 将输入与输出拼接在一起输出保存 batch_size*1*28*(28+28)=batch_size*1*28*56
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(sample_dir, 'reconst-{}.png'.format(epoch + 1)))
大概长这么个样子:
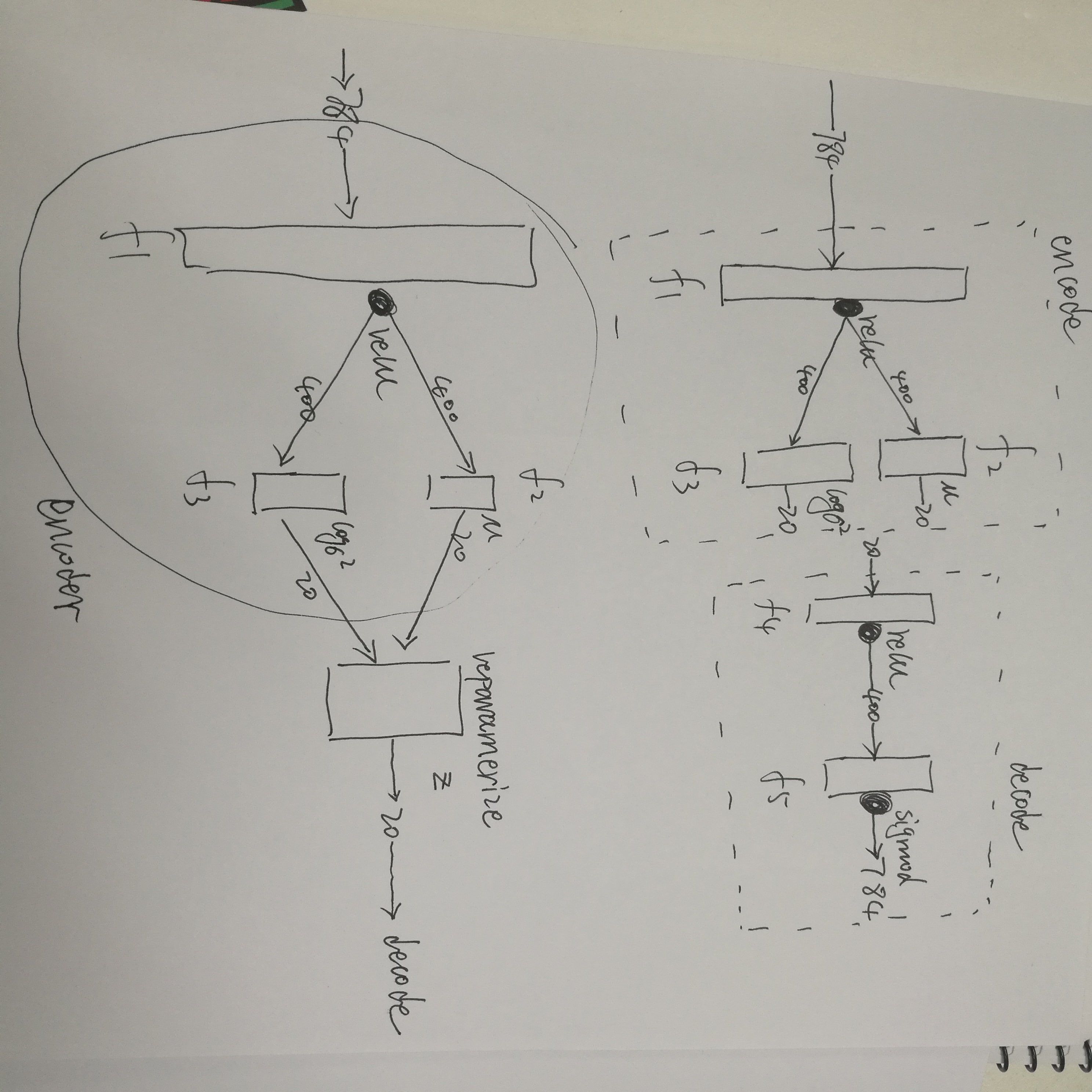
附上一张结果图:

Variational Auto-encoder(VAE)变分自编码器-Pytorch的更多相关文章
- VAE变分自编码器
我在学习VAE的时候遇到了很多问题,很多博客写的不太好理解,因此将很多内容重新进行了整合. 我自己的学习路线是先学EM算法再看的变分推断,最后学VAE,自我感觉这个线路比较好理解. 一.首先我们来宏观 ...
- VAE变分自编码器实现
变分自编码器(VAE)组合了神经网络和贝叶斯推理这两种最好的方法,是最酷的神经网络,已经成为无监督学习的流行方法之一. 变分自编码器是一个扭曲的自编码器.同自编码器的传统编码器和解码器网络一起,具有附 ...
- 变分自编码器(Variational auto-encoder,VAE)
参考: https://www.cnblogs.com/huangshiyu13/p/6209016.html https://zhuanlan.zhihu.com/p/25401928 https: ...
- (转) 变分自编码器(Variational Autoencoder, VAE)通俗教程
变分自编码器(Variational Autoencoder, VAE)通俗教程 转载自: http://www.dengfanxin.cn/?p=334&sukey=72885186ae5c ...
- 变分自编码器(Variational Autoencoder, VAE)通俗教程
原文地址:http://www.dengfanxin.cn/?p=334 1. 神秘变量与数据集 现在有一个数据集DX(dataset, 也可以叫datapoints),每个数据也称为数据点.我们假定 ...
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 基于变分自编码器(VAE)利用重建概率的异常检测
本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立 ...
- 变分推断到变分自编码器(VAE)
EM算法 EM算法是含隐变量图模型的常用参数估计方法,通过迭代的方法来最大化边际似然. 带隐变量的贝叶斯网络 给定N 个训练样本D={x(n)},其对数似然函数为: 通过最大化整个训练集的对数边际似然 ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
随机推荐
- golang 斐波那契数
golang 斐波那契数 package main import "fmt" /* 斐波那契数,亦称之为斐波那契数列(意大利语: Successione di Fibonacci) ...
- jquery中语法初学必备
$(this).hide() - 隐藏当前元素 $("p").hide() - 隐藏所有段落 $(".test").hide() - 隐藏所有 class=&q ...
- nginx 配置的server_name参数
nginx中的server_name指令主要用于配置基于名称虚拟主机. 一 匹配顺序,server_name指令在接到请求后的匹配顺序如下: 1.确切的server_name匹配,例如: server ...
- 震惊,hexo个人博客居然有这么方便的评论系统
论文搞得一头火,瞎倒腾了一下,没想到几分钟给自己的博客换了个评论系统. 之前用的gitalk,需要依赖github,死活没有成功,而且评论者还需要登录github才可以评论,不好用,刚才偶然间发现va ...
- 北漂IT男返乡2年的三线楼市观察(宜昌夷陵篇)-原创
一直想写点什么,这段时间总算有空,好嘞,正好有兴致来写一写楼市相关的文章以饕读者和粉丝朋友. 宜昌?说宜昌您可能不知道,但是说三峡大坝您就知道了 最近这两年,因为小宝的降临,我多半时间待在老家宜昌陪伴 ...
- MYSQL 神奇的操作insert into test select * from test;
将16行数据复制一份插入数据库,变成32行
- vim 外部粘贴代码,如何保持原格式,而不持续缩进
主要内容:使用“:set paste” 来实现vim 按照源文件格式复制 在vim 使用中偶尔要复制外部代码,常常出现不停缩进的问题: 怎么避免此种情况出现呢 可以在命令模式中使用“:set past ...
- TextFX Notepad++
textFx Notepad++ - 国内版 Bing https://cn.bing.com/search?FORM=U227DF&PC=U227&q=textFx+Notepad% ...
- iptables 配置 场景1
这样配置完成后,没法完成本地回环,需要对lo网卡进行配置 本地报文无法发出,继续添加规则
- ztree checkbox父子联动
1. 对于ztree而言,如果需要设置或者取消ztree的父子联动,只要在setting里面设置chkboxType的参数即可: 其中Y表示被checkbox被勾选时的联动情况,N表示取消勾选时的联动 ...