embeding 是什么
要搞清楚embeding先要弄明白他和one hot encoding的区别,以及他解决了什么one hot encoding不能解决的问题,带着这两个问题去思考,在看一个简单的计算例子
以下引用 YJango的Word Embedding–介绍
https://zhuanlan.zhihu.com/p/27830489
One hot representation
程序中编码单词的一个方法是one hot encoding。
实例:有1000个词汇量。排在第一个位置的代表英语中的冠词"a",那么这个"a"是用[1,0,0,0,0,…],只有第一个位置是1,其余位置都是0的1000维度的向量表示,如下图中的第一列所示。
也就是说,
在one hot representation编码的每个单词都是一个维度,彼此independent。
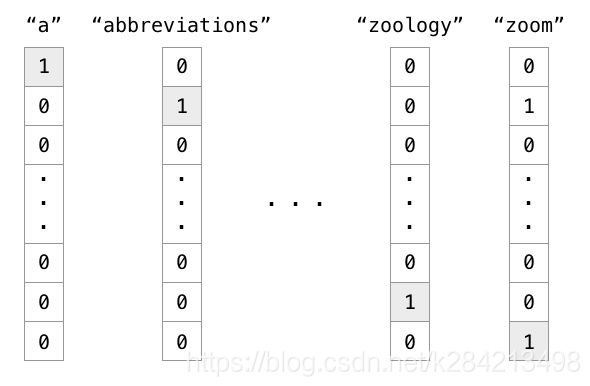
这里我们可以看到One hot方式处理的数据
1、会产生大量冗余的稀疏矩阵
2、维度(单词)间的关系,没有得到体现
继续引用
神经网络分析
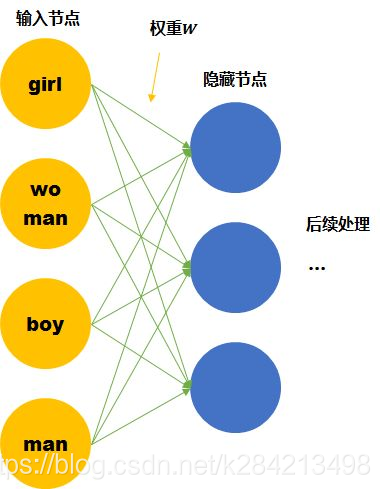
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
One hot representation
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的权重。如果只看第一层的权重,下面的情况需要确定43个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。
Distributed representation
我们这里手动的寻找这四个单词之间的关系 f 。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,第二个维度是age)。
那么这时再来看神经网络需要学习的连接线的权重就缩小到了23。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
Word embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
Word embedding就是要从数据中自动学习到输入空间到Distributed representation空间的 映射f 。

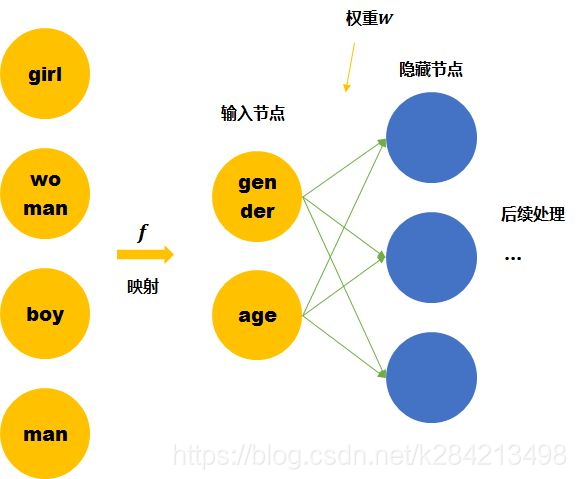
以上的计算都没有涉及到label,所以训练过程是无监督的
看一个实际代码计算的例子
假设有一个维度为7的稀疏向量[0,1,0,1,1,0,0]。你可以把它变成一个非稀疏的2d向量,如下所示:
model = Sequential()
model.add(Embedding(2, 2, input_length=7))#输入维,输出维
model.compile('rmsprop', 'mse')
model.predict(np.array([[0,1,0,1,1,0,0]]))array([[[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03005414, -0.02224021]]], dtype=float32)这个转换实际上是把[0,1,0,1,1,0,0]增加一个纵向展开的维度
model.layers[0].W.get_value()array([[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888]], dtype=float32)通过比较两个数组可以看出0值映射到第一个索引,1值映射到第二个索引。嵌入构造函数的第一个值是输入中的值范围。在示例中它是2,因为我们给出了二进制向量作为输入。第二个值是目标维度。第三个是我们给出的向量的长度。
所以,这里没有什么神奇之处,只是从整数到浮点数的映射。
计算例子的model.layers[0].W.get_value(),就是上面引用图示中的映射f
embeding 是什么的更多相关文章
- Embeding Python & Extending Python with FFPython
Introduction ffpython is a C++ lib, which is to simplify tasks that embed Python and extend Python. ...
- keras embeding设置初始值的两种方式
随机初始化Embedding from keras.models import Sequential from keras.layers import Embedding import numpy a ...
- Embeding如何理解?
参考: http://www.sohu.com/a/206922947_390227 https://zhuanlan.zhihu.com/p/27830489 https://www.jianshu ...
- 分享一些学习资料-大量PDF电子书
分享一些学习用的电子书籍,给那些喜欢看书而不一定有机会买书的童鞋. 反对积分下载,提倡自由分享. 分享地址: http://pan.baidu.com/s/1qWK5V0g 提取密码: np33 ...
- 第七章 人工智能,7.6 DNN在搜索场景中的应用(作者:仁重)
7.6 DNN在搜索场景中的应用 1. 背景 搜索排序的特征分大量的使用了LR,GBDT,SVM等模型及其变种.我们主要在特征工程,建模的场景,目标采样等方面做了很细致的工作.但这些模型的瓶颈也非常的 ...
- Feuding Families and Former Friends: Unsupervised Learning for Dynamic Fictional Relationships-Naacl 2016-20160422
1.Information publication:-Naacl 2016 2.What 根据小说中的人物描述,a)在每个时间段给出,人物关系的描述的概率分布,b)从时间轴上看出关系的变化轨迹,提出模 ...
- VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback-AAAI2016 -20160422
1.Information publication:AAAI2016 2.What 基于BPR模型的改进:在商品喜好偏序对的学习中,将商品图片的视觉信息加入进去,冷启动问题. 3.Dataset Am ...
- 关于Go,你可能不注意的7件事(转的)
http://tonybai.com/2015/09/17/7-things-you-may-not-pay-attation-to-in-go/ code https://github.com/bi ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
随机推荐
- Scrum会议博客以及测试报告
3组Alpha冲刺阶段博客目录 一.Scrum Meeting1. 第六周会议记录(链接地址:https://www.cnblogs.com/Cherrison-Time/articles/11788 ...
- pyspark minHash LSH 查找相似度
先看看官方文档: MinHash for Jaccard Distance MinHash is an LSH family for Jaccard distance where input feat ...
- RSA 加密 解密 (长字符串) JAVA JS版本加解密
系统与系统的数据交互中,有些敏感数据是不能直接明文传输的,所以在发送数据之前要进行加密,在接收到数据时进行解密处理:然而由于系统与系统之间的开发语言不同. 本次需求是生成二维码是通过java生成,由p ...
- npm start a http server( 在windows的任意目录上开启一个http server 用来测试html 页面和js代码,不用放到nginx的webroot目录下!!)
原文:https://stackabuse.com/how-to-start-a-node-server-examples-with-the-most-popular-frameworks/#:~:t ...
- git push 缓存密码和用户名
https://stackoverflow.com/questions/6565357/git-push-requires-username-and-password git remote -v -- ...
- Union-Find(并查集): Dynamic Connectivity 问题
设计算法一般所使用的方法过程 什么是Dynamic connectivity 我们的problem就是支持这两种操作: Union与connected query Example 问题是两个objec ...
- PHP——最新号码归属地数据库
前言 最近在忙的一个项目,为了数据安全,不能够使用任何第三方的接口~ 号码库 | https://github.com/wangyang0210/Phone-Number-Range 代码 其实就是一 ...
- docker 进程 转载:https://www.cnblogs.com/ilinuxer/p/6188303.html
今天我们会分析Docker中进程管理的一些细节,并介绍一些常见问题的解决方法和注意事项. 容器的PID namespace(名空间) 在Docker中,进程管理的基础就是Linux内核中的PID名空间 ...
- Go语言 - 数组 | 多维数组
Array 数组是同一种数据类型元素的集合. 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化. 1.数组 在定义阶段,长度和类型就固定了,以后不能更改 2.长度也是数组 ...
- python的拷贝方式以及深拷贝,浅拷贝详解
python的拷贝方法有:切片方法, 工厂方法, 深拷贝方法, 浅拷贝方法等. 几种方法都可以实现拷贝操作, 具体区别在于两点:1.代码写法不同. 2.内存地址引用不同 代码演示: import co ...