python scrapy 登录知乎过程
前面了解了scrapy框架的大概各个组件的作用,
现在要爬取知乎数据,那么第一步就是要登录!
看下知乎的登录页面发现登录主要是两大接口
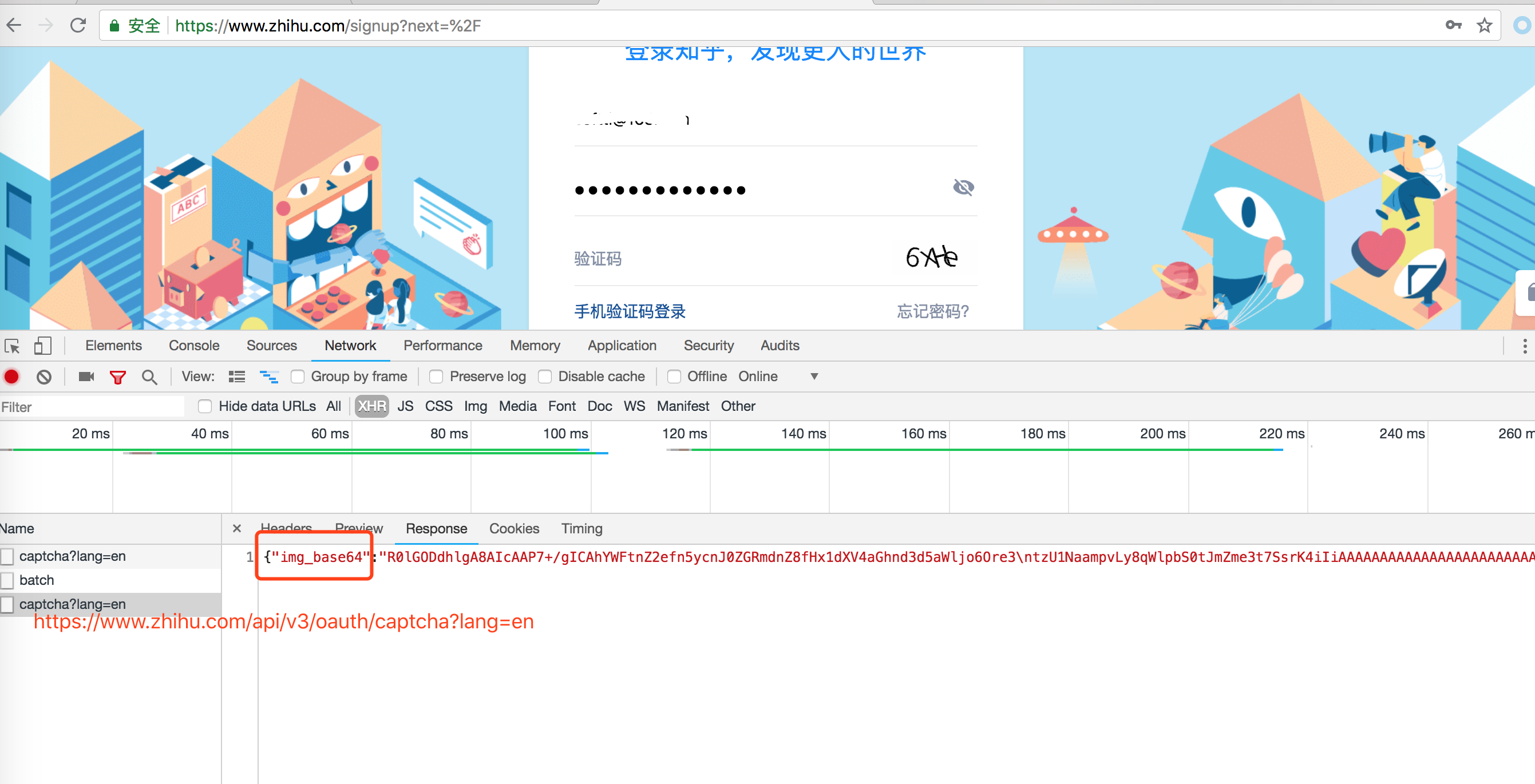
一: 登录页面地址,获取登录需要的验证码,如下图
打开知乎登录页面,需要输入用户名和密码, 还有一个验证码,
看chrome 调试工具发现验证码是这个地址返回的: https://www.zhihu.com/api/v3/oauth/captcha?lang=en
返回的结果中用base64加密了, 我们需要手动解密
二: 知乎登录接口
登录接口就是点击登录按钮访问的接口,
接口地址: https://www.zhihu.com/api/v3/oauth/sign_in
我们要做的就是封装参数,调用登录接口.

代码如下:
# -*- coding: utf-8 -*- import hmac
import json
import scrapy
import time
import base64
from hashlib import sha1 class ZhihuLoginSpider(scrapy.Spider):
name = 'zhihu_login'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
headers = {
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'Referer': 'https://www.zhihu.com/signup?next=%2F',
'User-Agent': agent,
'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20'
}
grant_type = 'password'
client_id = 'c3cef7c66a1843f8b3a9e6a1e3160e20'
source = 'com.zhihu.web'
timestamp = str(int(time.time() * 1000))
timestamp2 = str(time.time() * 1000)
print(timestamp)
print(timestamp2)
# 验证登录成功之后, 可以开始真正的爬取业务
def check_login(self, response):
# 验证是否登录成功
text_json = json.loads(response.text)
print(text_json)
yield scrapy.Request('https://www.zhihu.com/inbox', headers=self.headers) def get_signature(self, grant_type, client_id, source, timestamp):
"""处理签名"""
hm = hmac.new(b'd1b964811afb40118a12068ff74a12f4', None, sha1)
hm.update(str.encode(grant_type))
hm.update(str.encode(client_id))
hm.update(str.encode(source))
hm.update(str.encode(timestamp))
return str(hm.hexdigest()) def parse(self, response):
print("****************")
print(response.url)
#print(response.body.decode("utf-8")) def start_requests(self):
yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers, callback=self.is_need_capture) def is_need_capture(self, response):
print(response.text)
need_cap = json.loads(response.body)['show_captcha']
print(need_cap) if need_cap:
print('需要验证码')
yield scrapy.Request(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
headers=self.headers,
callback=self.capture,
method='PUT'
)
else:
print('不需要验证码')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 输入知乎用户名
"password": "", # 输入知乎密码
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": "baidu"
}
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login
)
# yield scrapy.Request('https://www.zhihu.com/captcha.gif?r=%d&type=login' % (time.time() * 1000),
# headers=self.headers, callback=self.capture, meta={"resp": response})
# yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
# headers=self.headers, callback=self.capture, meta={"resp": response},dont_filter=True) def capture(self, response):
# print(response.body)
try:
img = json.loads(response.body)['img_base64']
except ValueError:
print('获取img_base64的值失败!')
else:
img = img.encode('utf8')
img_data = base64.b64decode(img) with open('/var/www/html/scrapy/zh.gif', 'wb') as f:
f.write(img_data)
f.close()
captcha = raw_input('请输入验证码:')
post_data = {
'input_text': captcha
}
yield scrapy.FormRequest(
url='https://www.zhihu.com/api/v3/oauth/captcha?lang=en',
formdata=post_data,
callback=self.captcha_login,
headers=self.headers
) def captcha_login(self, response):
try:
cap_result = json.loads(response.body)['success']
print(cap_result)
except ValueError:
print('关于验证码的POST请求响应失败!')
else:
if cap_result:
print('验证成功!')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data = {
"client_id": self.client_id,
"username": "", # 输入知乎用户名
"password": "", # 输入知乎密码
"grant_type": self.grant_type,
"source": self.source,
"timestamp": self.timestamp,
"signature": self.get_signature(self.grant_type, self.client_id, self.source, self.timestamp), # 获取签名
"lang": "en",
"ref_source": "homepage",
"captcha": '',
"utm_source": ""
}
headers = self.headers
headers.update({
'Origin': 'https://www.zhihu.com',
'Pragma': 'no - cache',
'Cache-Control': 'no - cache'
})
yield scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=headers,
callback=self.check_login
)
登录成功后调用check_login方法测试是否有登录状态.
我在后面爬取 知乎问题和答案的时候把这个方法当做start_requests方法,用来构造爬取地址.
python scrapy 登录知乎过程的更多相关文章
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- 2019年最新 Python 模拟登录知乎 支持验证码
知乎的登录页面已经改版多次,加强了身份验证,网络上大部分模拟登录均已失效,所以我重写了一份完整的,并实现了提交验证码 (包括中文验证码),本文我对分析过程和代码进行步骤分解,完整的代码请见末尾 Git ...
- python模拟登录知乎
# -*- coding:utf-8 -*- import urllib import urllib2 import cookielib import sys from bs4 import Beau ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 2020.10.20 利用POST请求模拟登录知乎
前两天学习了Python的requests模块的相关内容,对于用GET和PSOT请求访问网页以抓取需要的内容有了初步的了解,想要再从一些复杂的网站积累些经验.最开始我采用最简单的get(url)方法想 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫scrapy框架——人工识别知乎登录知乎倒立文字验证码和数字英文验证码
目前知乎使用了点击图中倒立文字的验证码: 用户需要点击图中倒立的文字才能登录. 这个给爬虫带来了一定难度,但并非无法解决,经过一天的耐心查询,终于可以人工识别验证码并达到登录成功状态,下文将和大家一一 ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
随机推荐
- GAN笔记——理论与实现
GAN这一概念是由Ian Goodfellow于2014年提出,并迅速成为了非常火热的研究话题,GAN的变种更是有上千种,深度学习先驱之一的Yann LeCun就曾说,"GAN及其变种是数十 ...
- docker学习系列(二):使用Dockerfile创建自己的镜像
dockerfile可以允许我们自己创建镜像,通过编写里面的下载软件命令,执行docker build 即可生成镜像文件. 初尝dockerfile 新建一个目录test,然后进入这个目录,创建一个名 ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
- js常用面试题整理
1.array操作关键字: pop() 删除最后一个:push最后添加一个或者多个:reverse颠倒数组:shift删除第一个元素:unshift首部添加元素:concat衔接两个数组:join把数 ...
- spring-boot-2.0.3之redis缓存实现,不是你想的那样哦!
前言 开心一刻 小白问小明:“你前面有一个5米深的坑,里面没有水,如果你跳进去后该怎样出来了?”小明:“躺着出来呗,还能怎么出来?”小白:“为什么躺着出来?”小明:“5米深的坑,还没有水,跳下去不死就 ...
- nginx配置指南
nginx(读作engine x)是一款设计优秀的Http服务器, 其占用内存少, 负载能力强且稳定性高, 正在被越来越多的用户所采用. nginx可以为HTTP, HTTPS, SMTP, POP3 ...
- HTML中多种空格转义字符
记录一下,空格的转义字符分为如下几种: 1. &160#;不断行的空白(1个字符宽度) 2. &8194#;半个空白(1个字符宽度) 3. &8195#;一个空白(2个 ...
- spring cloud config安全
前面两篇介绍了spring cloud config服务端和客户端的简单配置,本篇介绍如何保护config server及对应config client修改. 保护config server,主要是使 ...
- js发送请求
1.Chrome控制台中 net::ERR_CONNECTION_REFUSED js频繁发送请求,有可能连接被拒绝,可用setTimeout,过几秒发送,给个缓冲时间 var overlayAnal ...
- 【读书笔记】iOS-自定义URL Scheme注意事项
如果两个不同的应用注册了同样的URL Scheme,那么后安装的应用会响应符合这种协议格式的URL. 如果你的应用的iPhone和iPad版是各自独立的(即不是Universal类型的),那么你就不应 ...